Downloaded 85 times



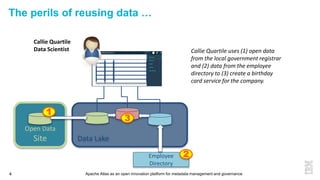
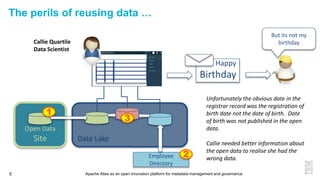
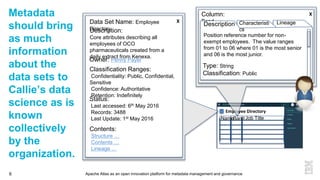



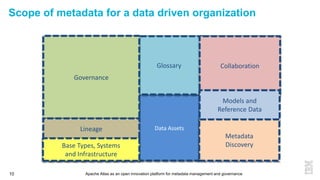

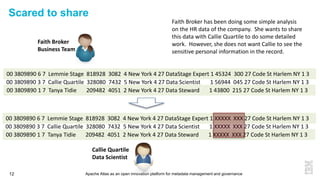
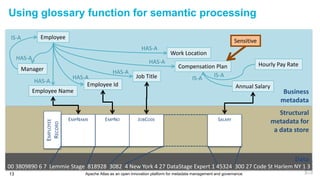


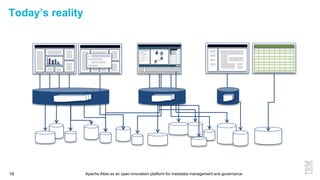
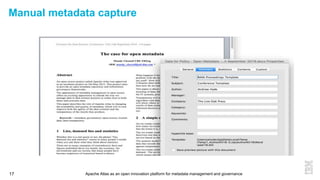

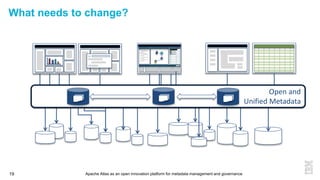

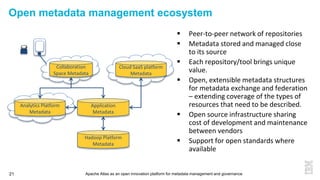

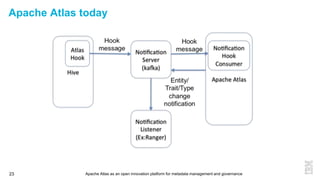
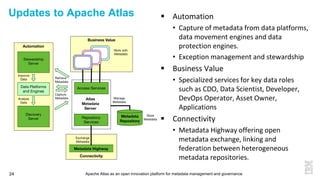

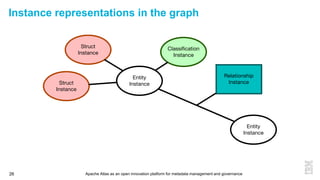
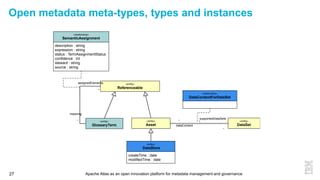
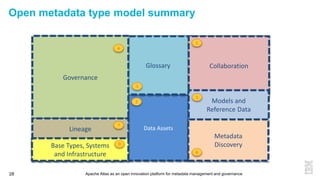
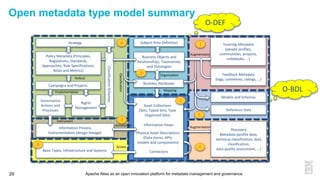

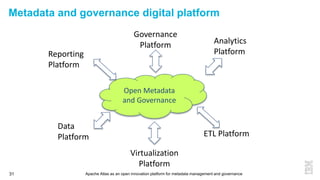

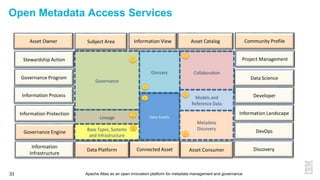
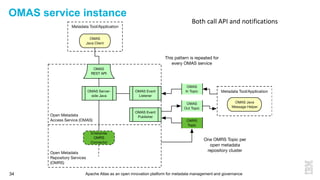
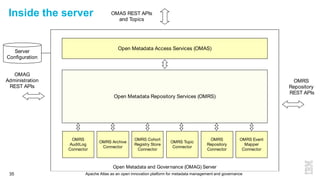
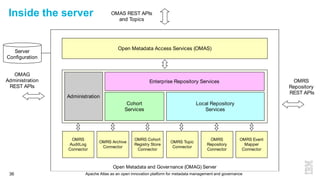
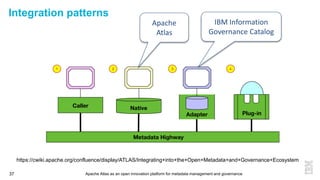
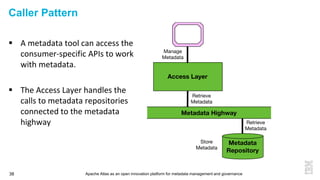
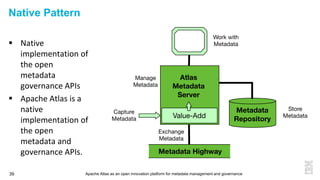
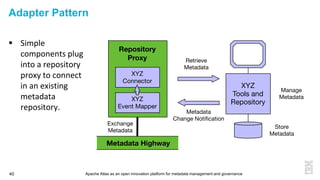
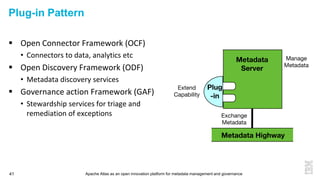
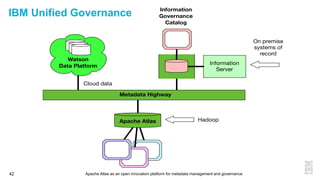
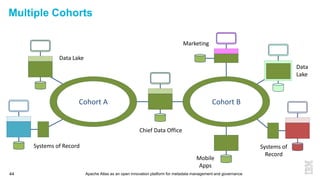
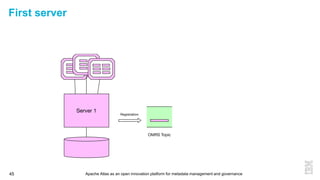
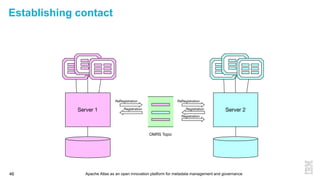
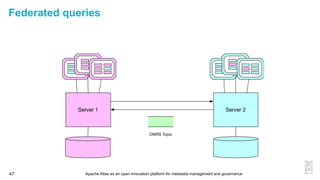
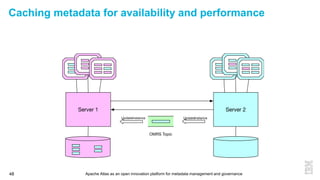

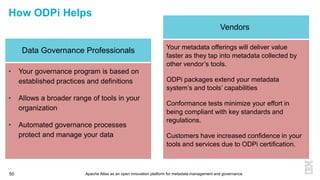




This document discusses metadata and the importance of metadata management. It introduces Apache Atlas as an open source platform for metadata management and governance. Key points include: - Metadata is important for data reuse, analytics, and governance. It provides context and meaning about data. - Current reality is that metadata is often not well supported or integrated across tools. Apache Atlas aims to provide an open, unified approach. - Apache Atlas has graduated to a top-level Apache project. It provides a type-agnostic metadata store and interfaces that can be accessed by various tools. - The vision is for an open ecosystem where metadata is shared and federated across repositories from different vendors and tools.

















![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)

















![The Evolution of Metadata: LinkedIn's Story [Strata NYC 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/metadatajourneylinkedinstratapublic-190930045839-thumbnail.jpg?width=640&height=640&fit=bounds)


















































