Downloaded 410 times


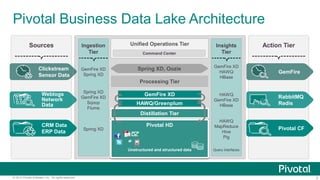

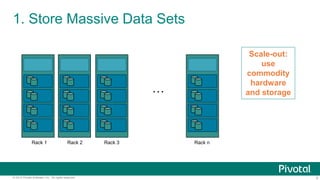

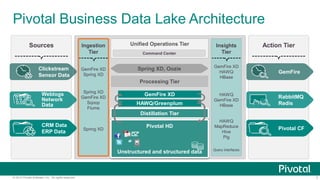

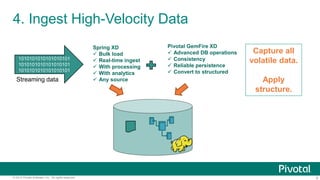



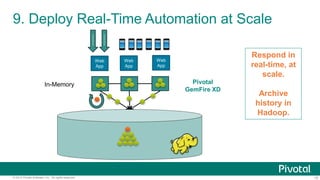





The document outlines ten innovative uses for a Hadoop-based data lake showcased at the Strata Conference in New York in 2014. Key points include the ability to store massive data sets, ingest various data types, and apply structure to unstructured data, which enhances data integration and predictive analytics. The architecture enables scalable real-time automation and continuous innovation for improved business insights.























































































