Download as PDF, PPTX



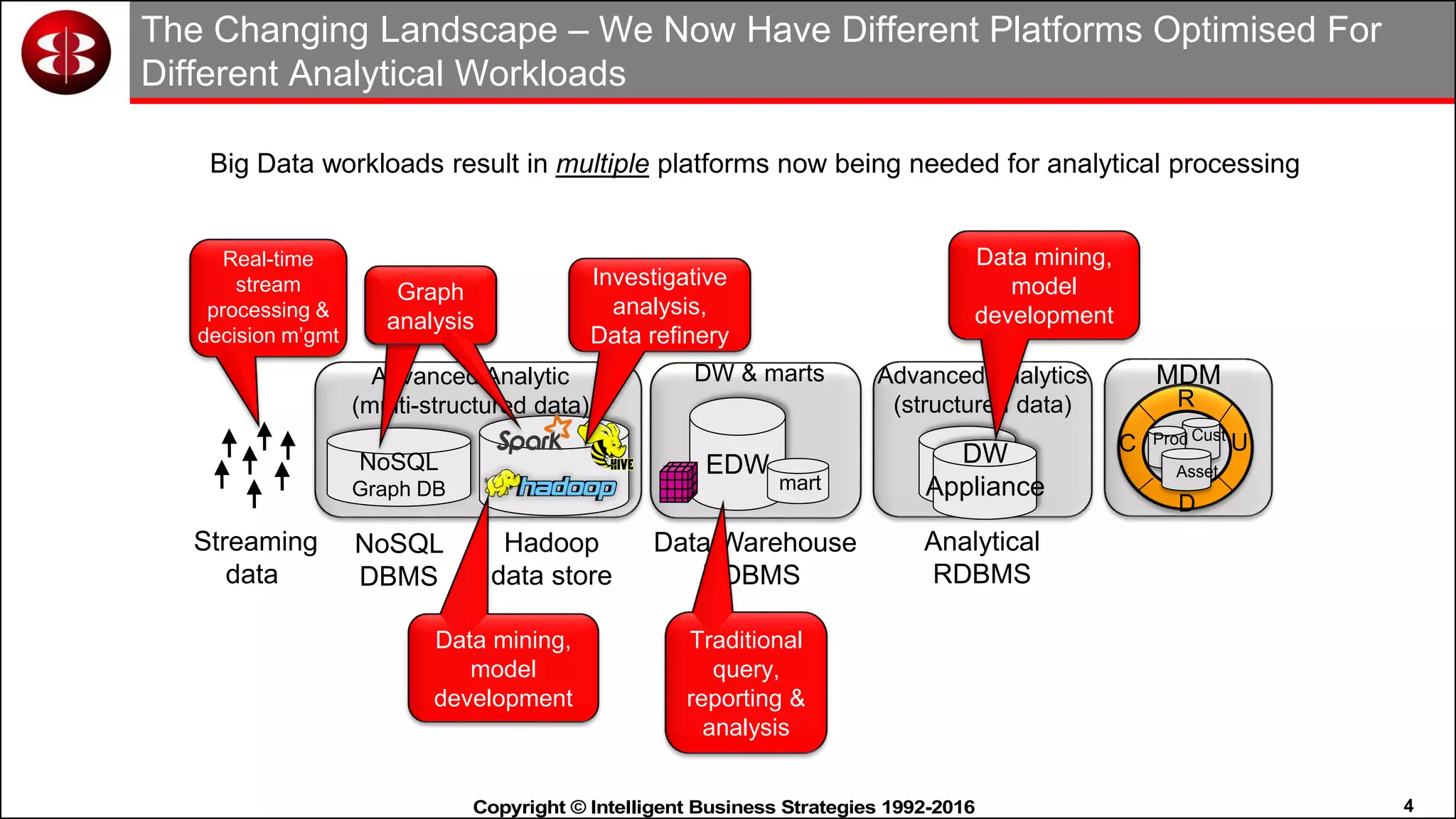
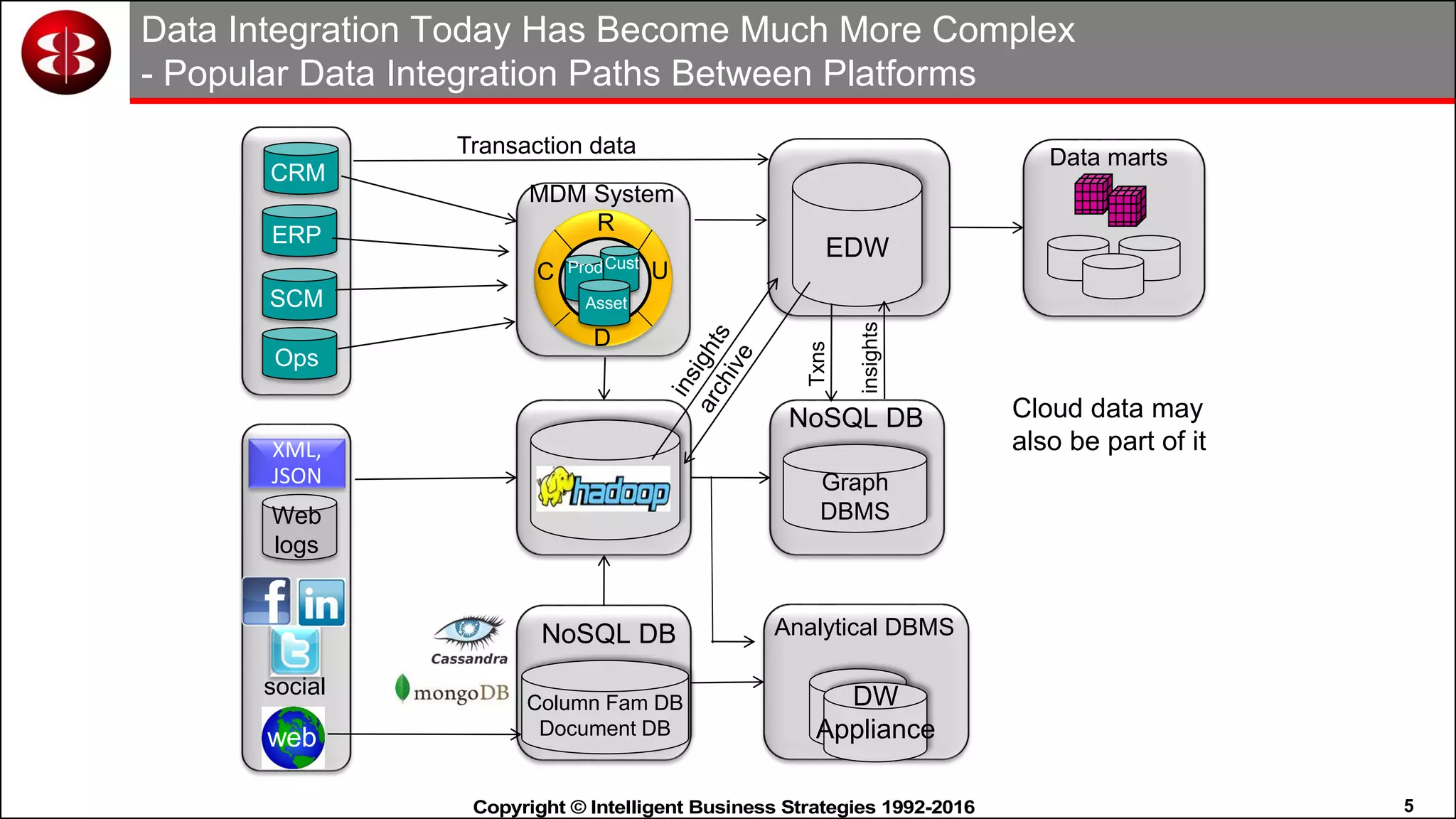
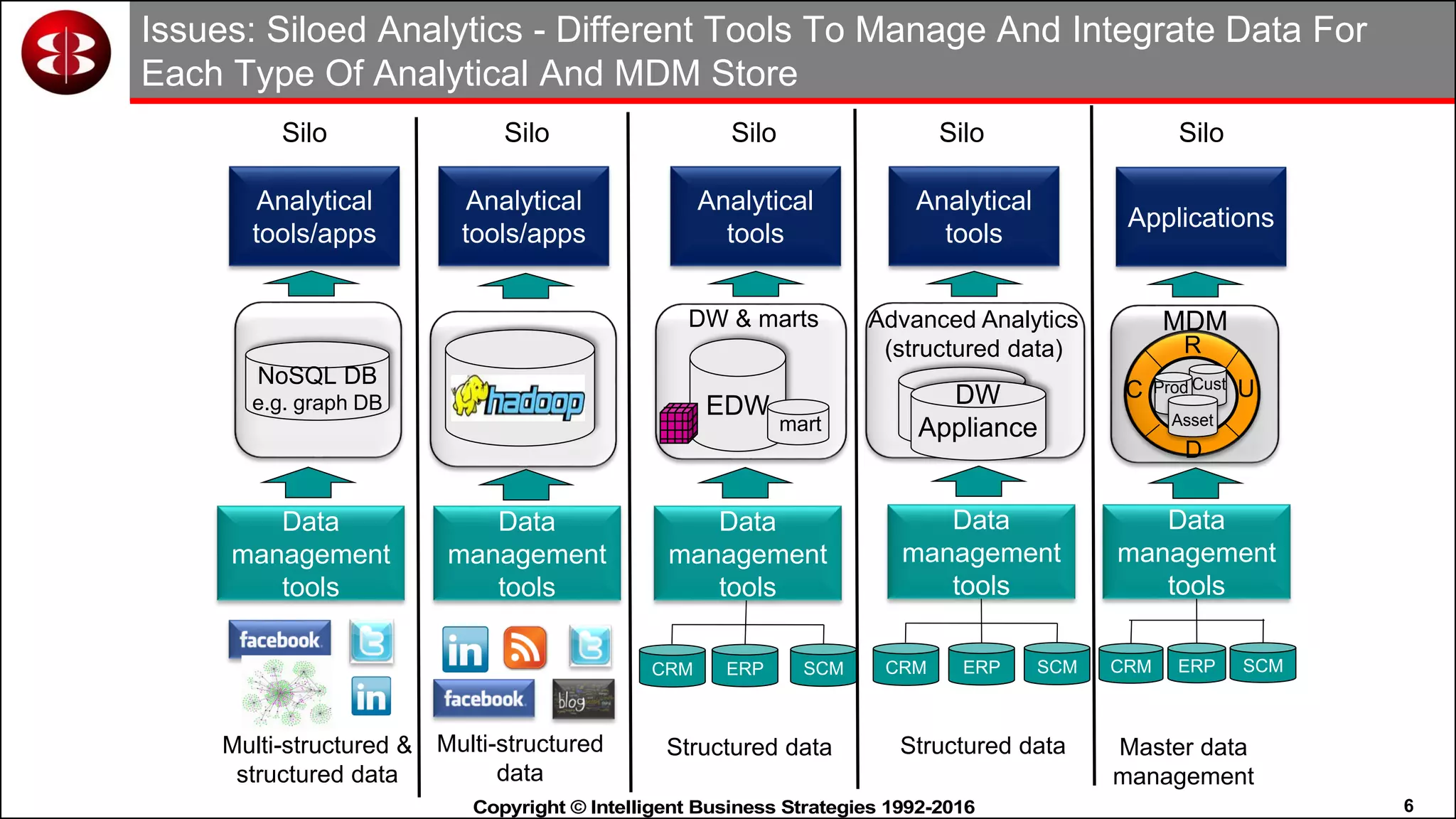
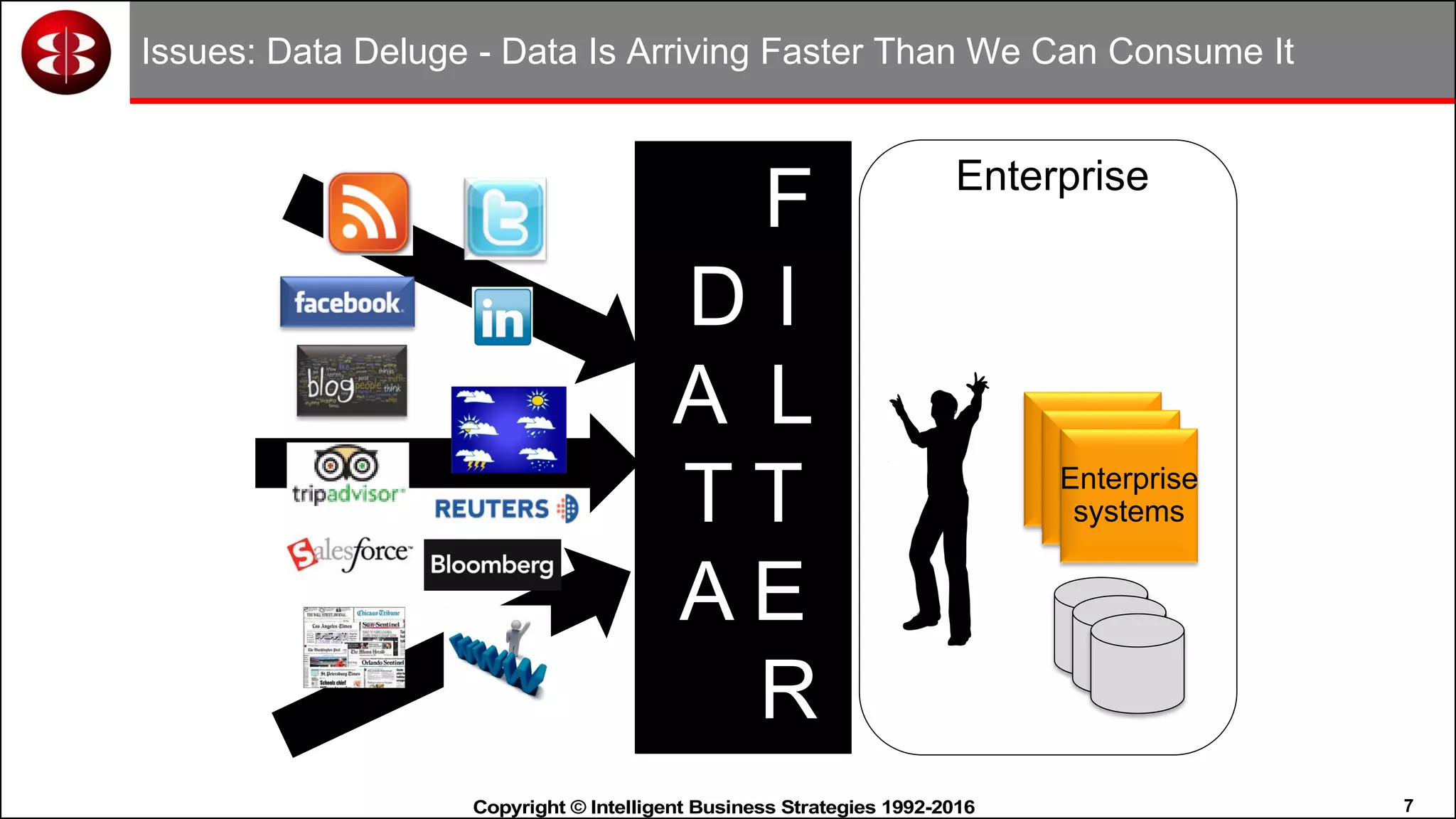
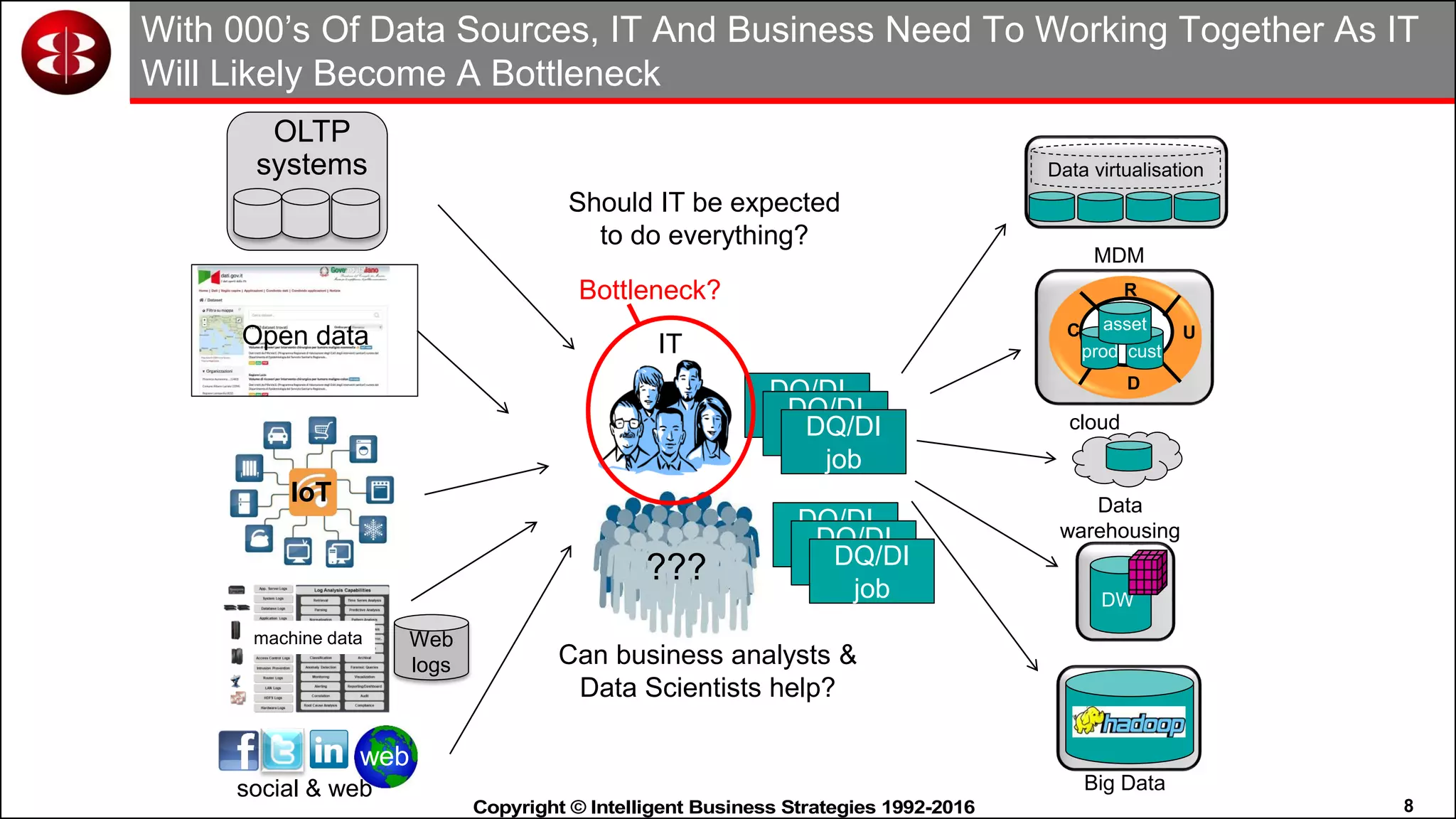
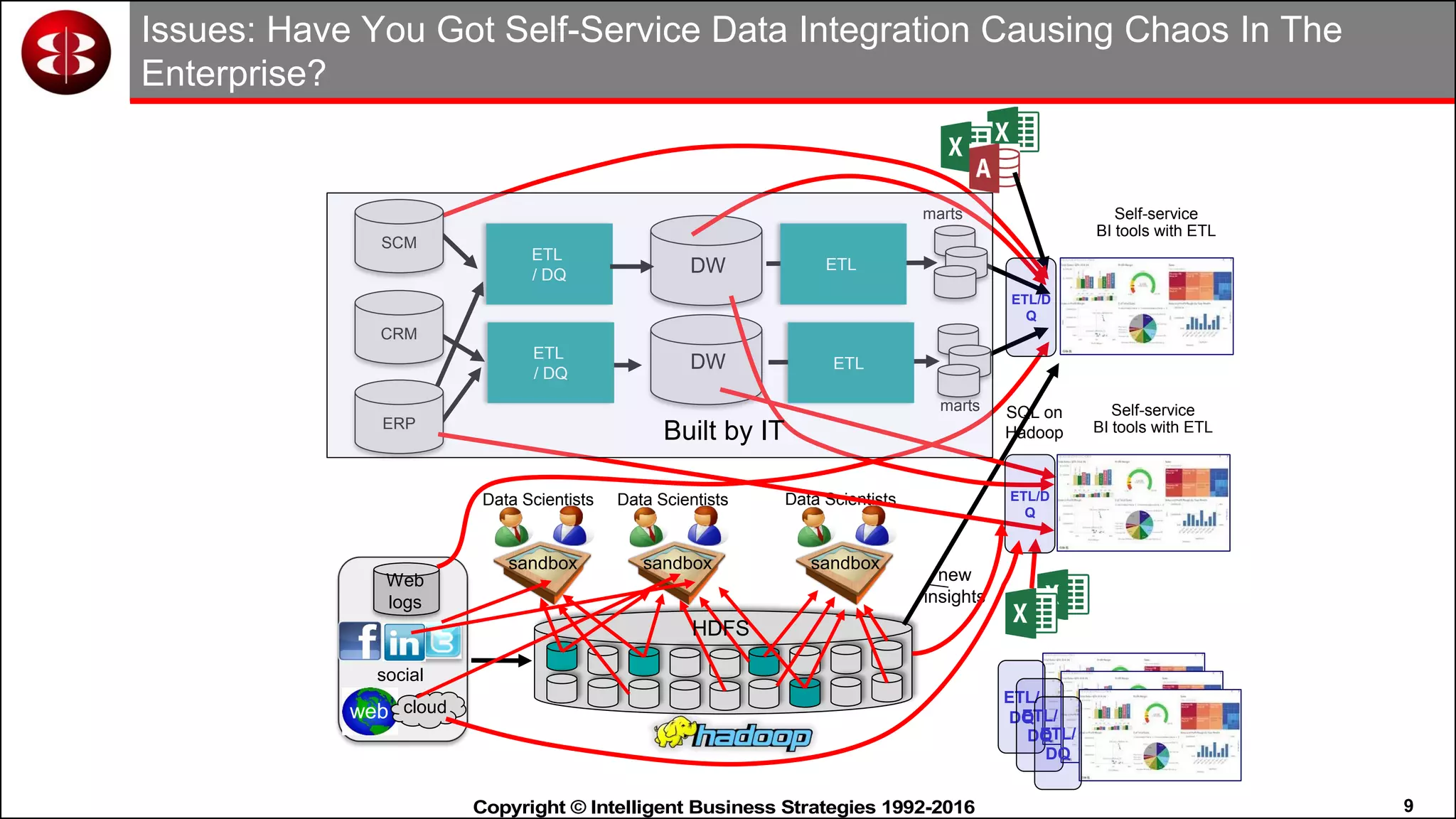





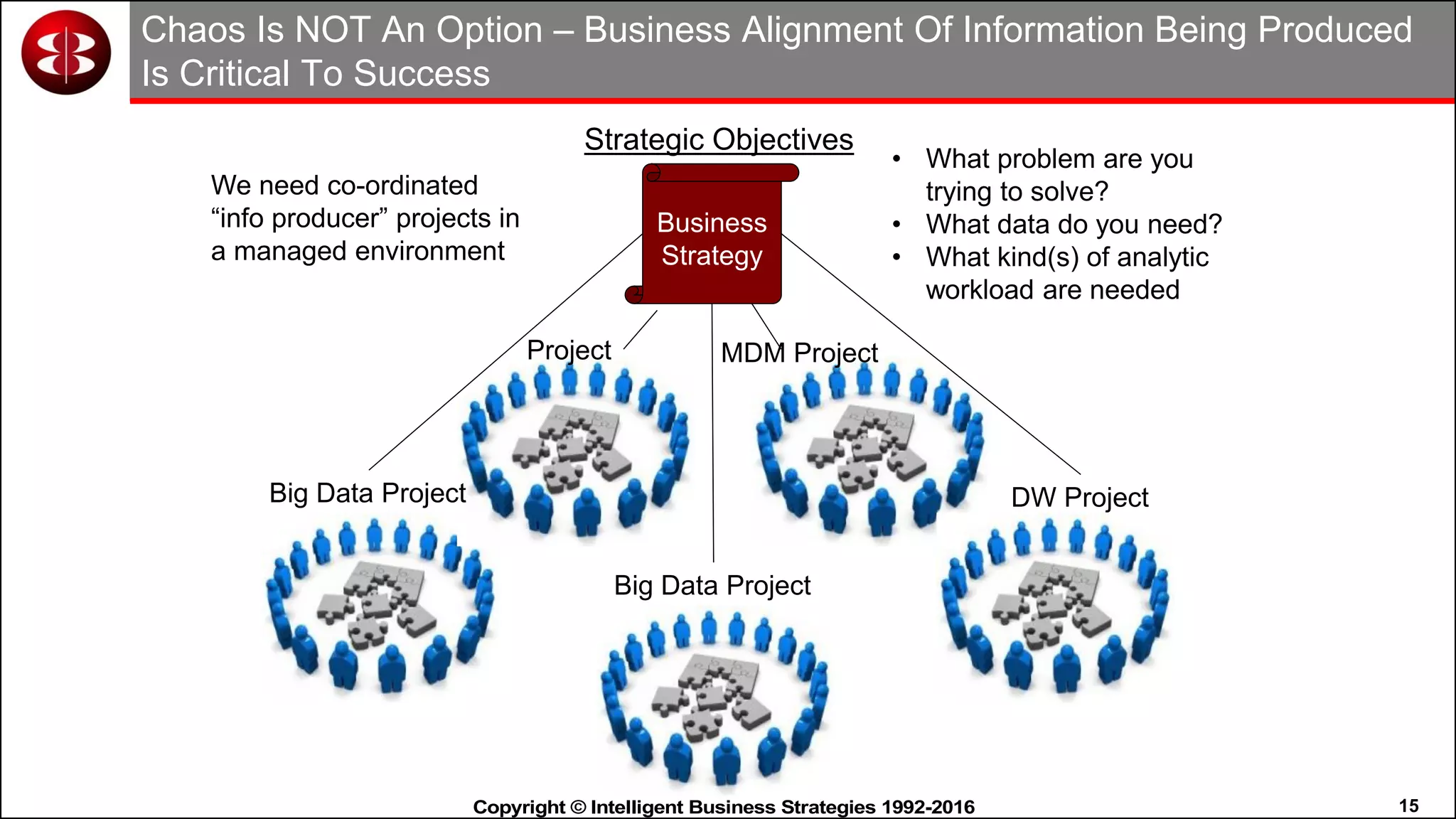


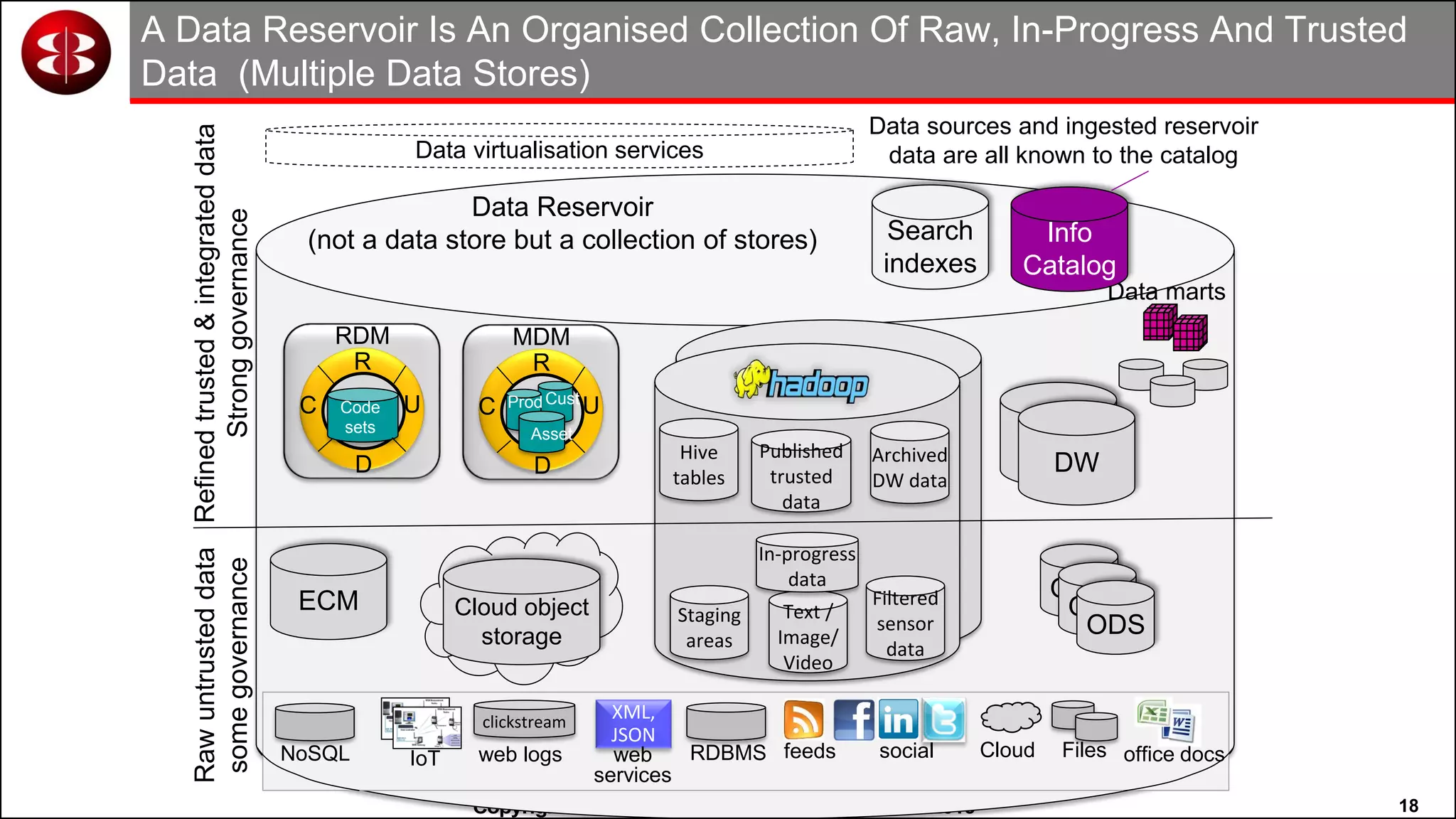
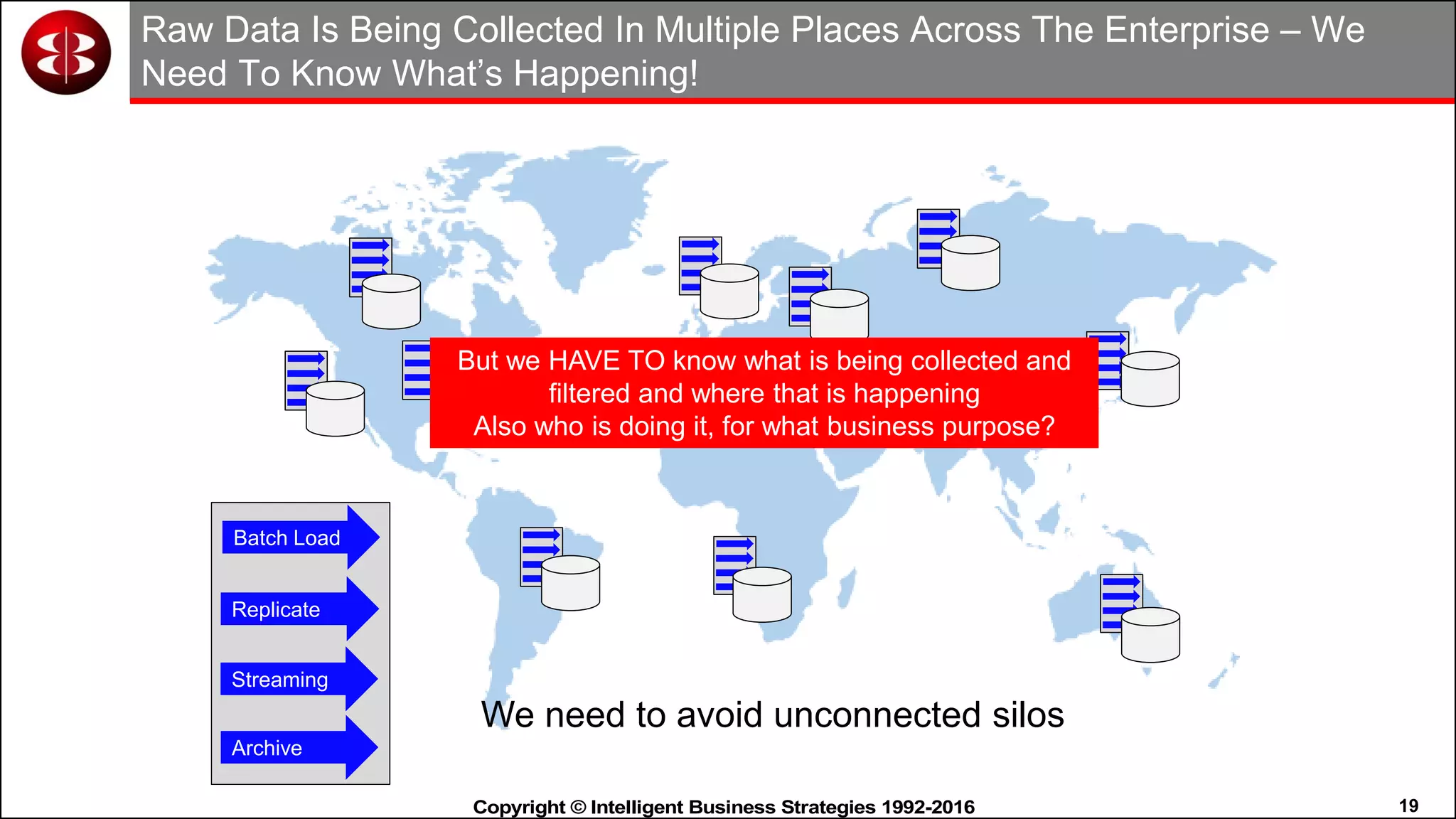
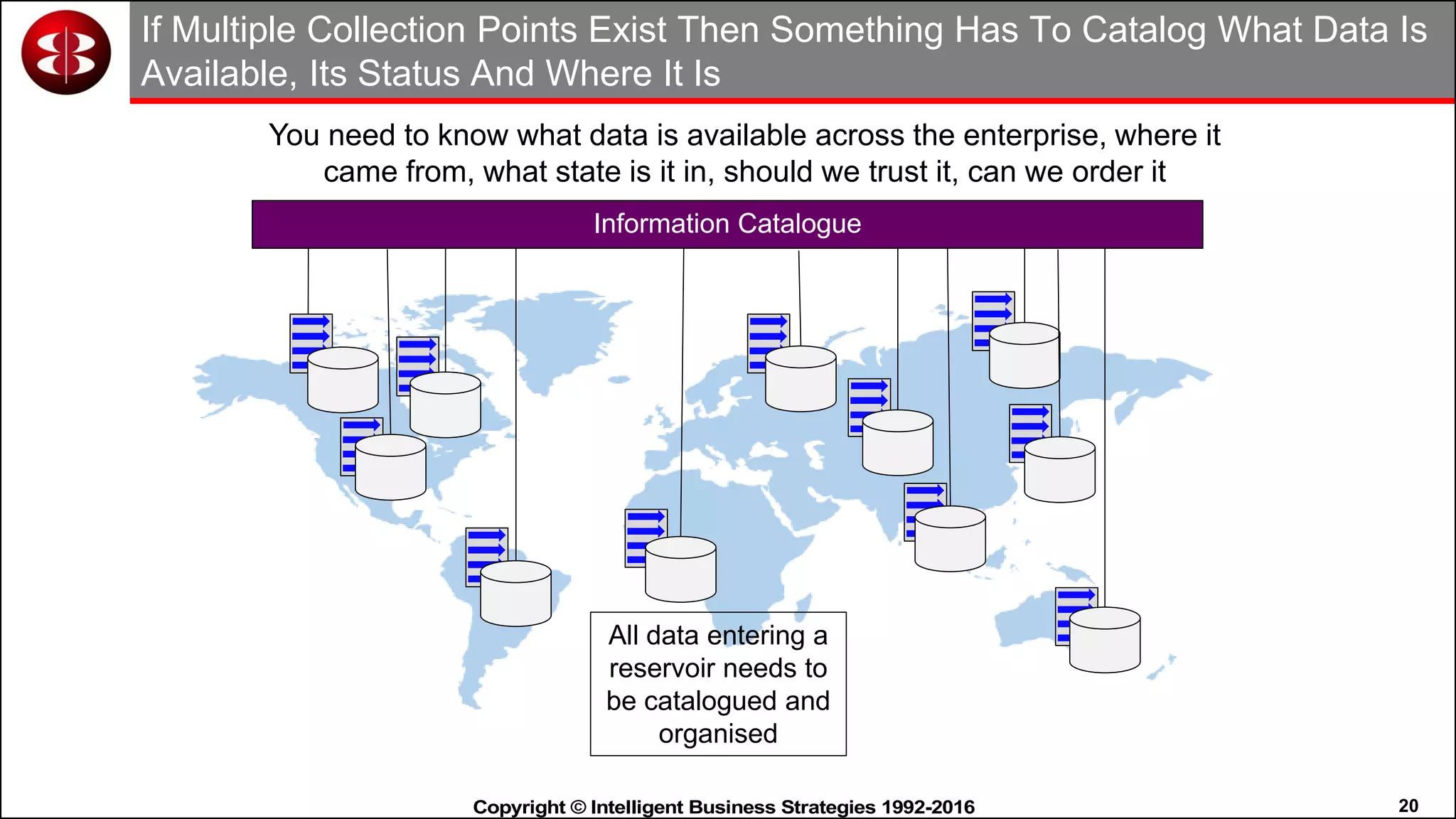
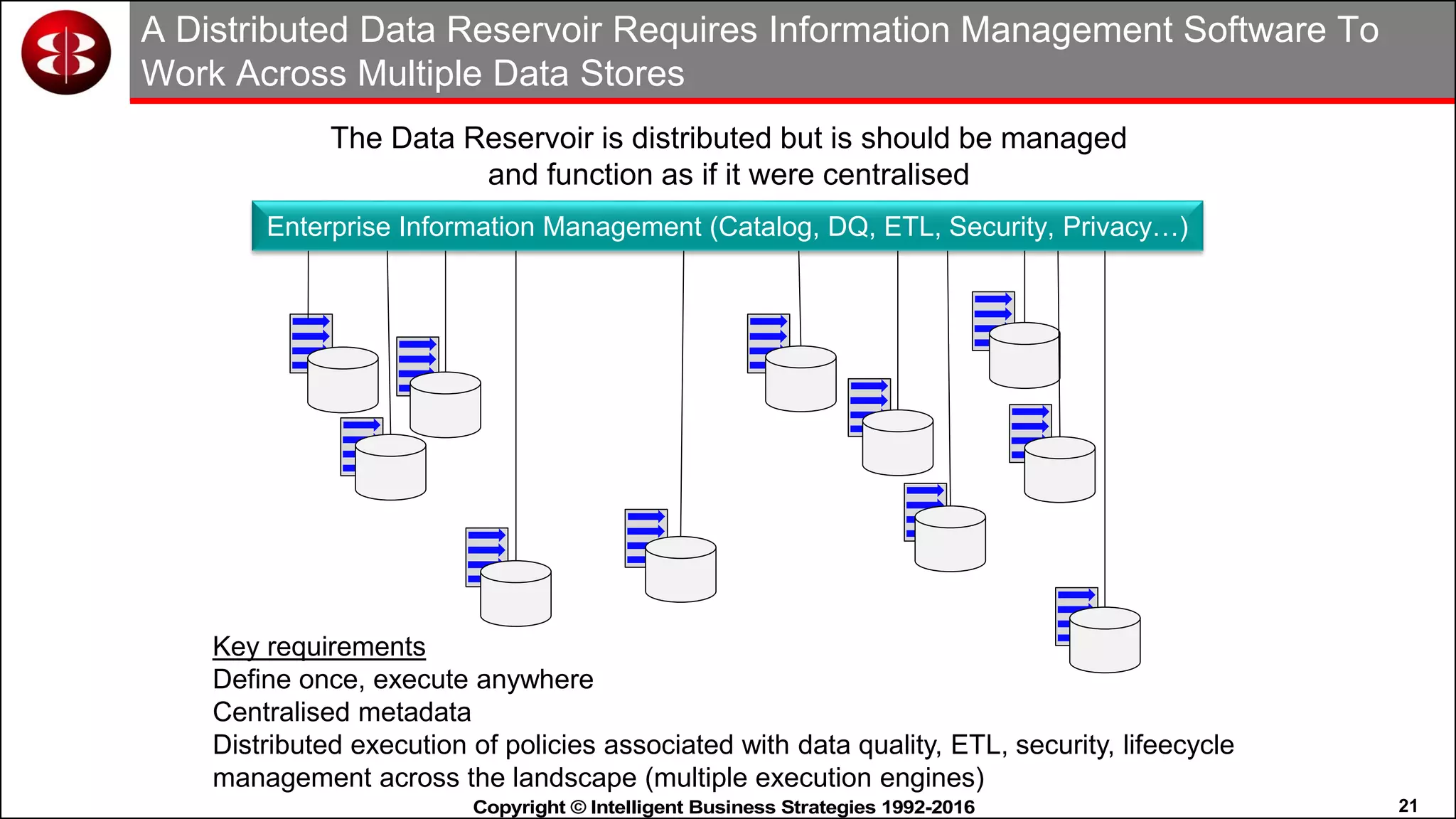
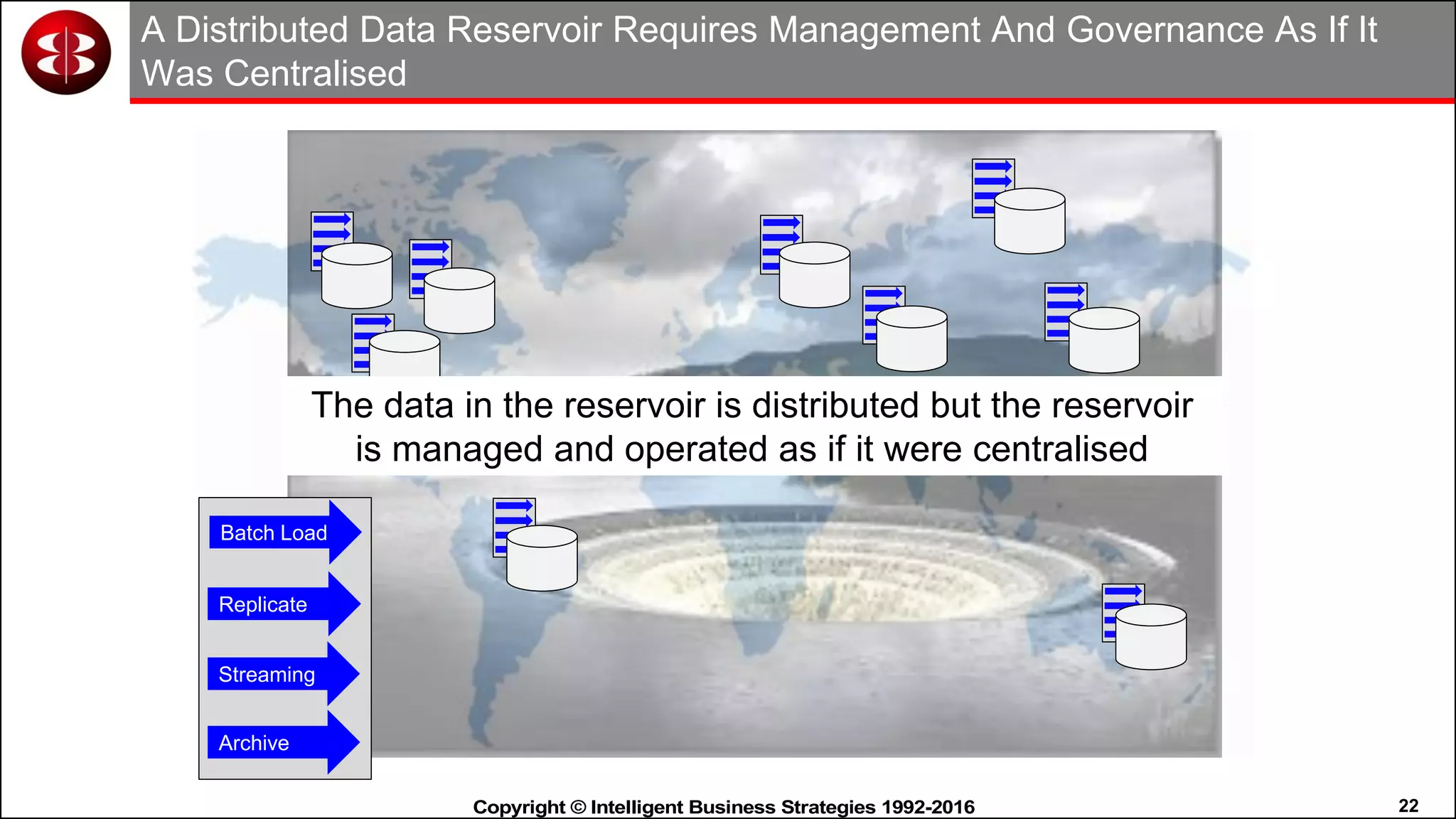

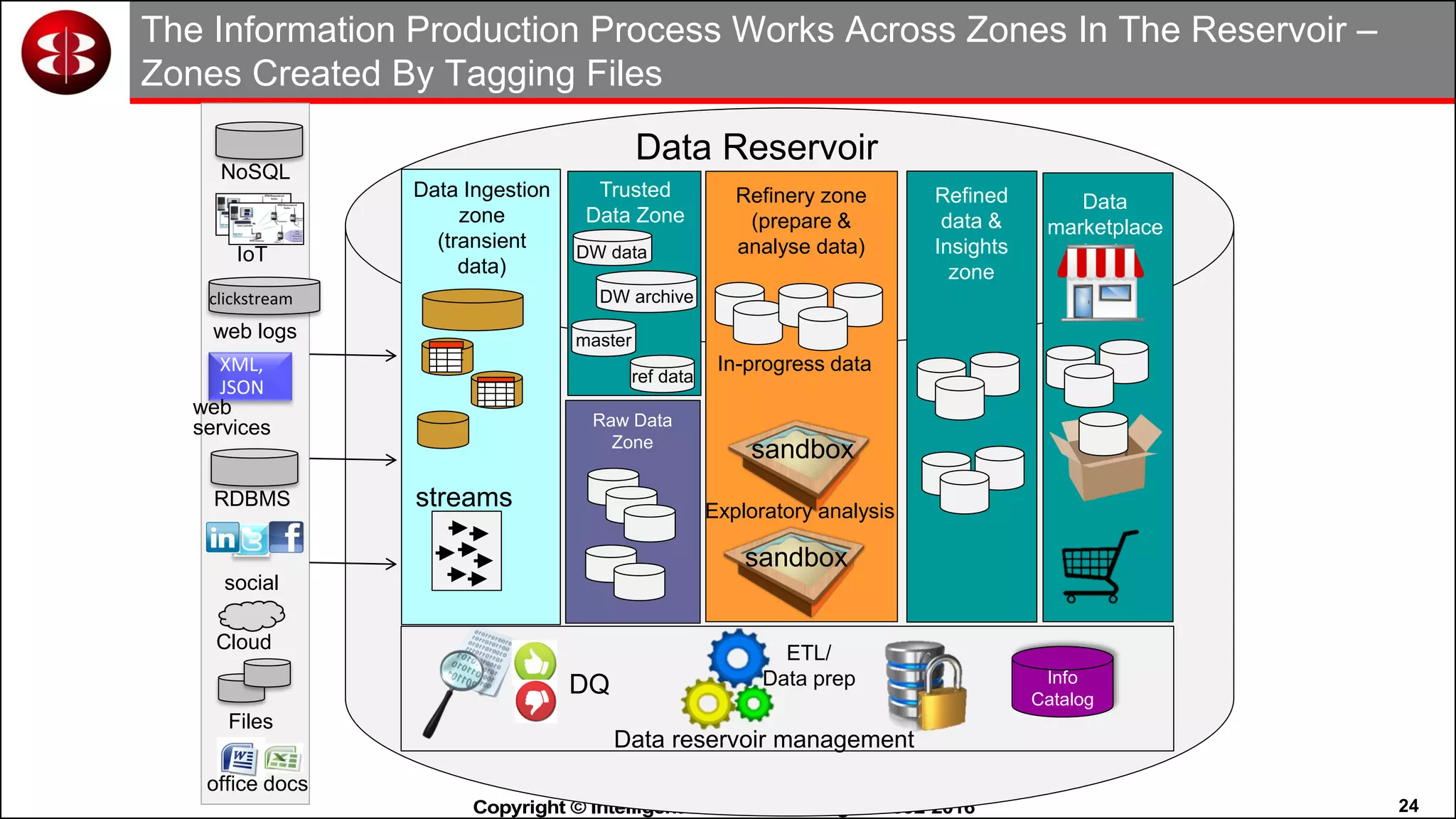

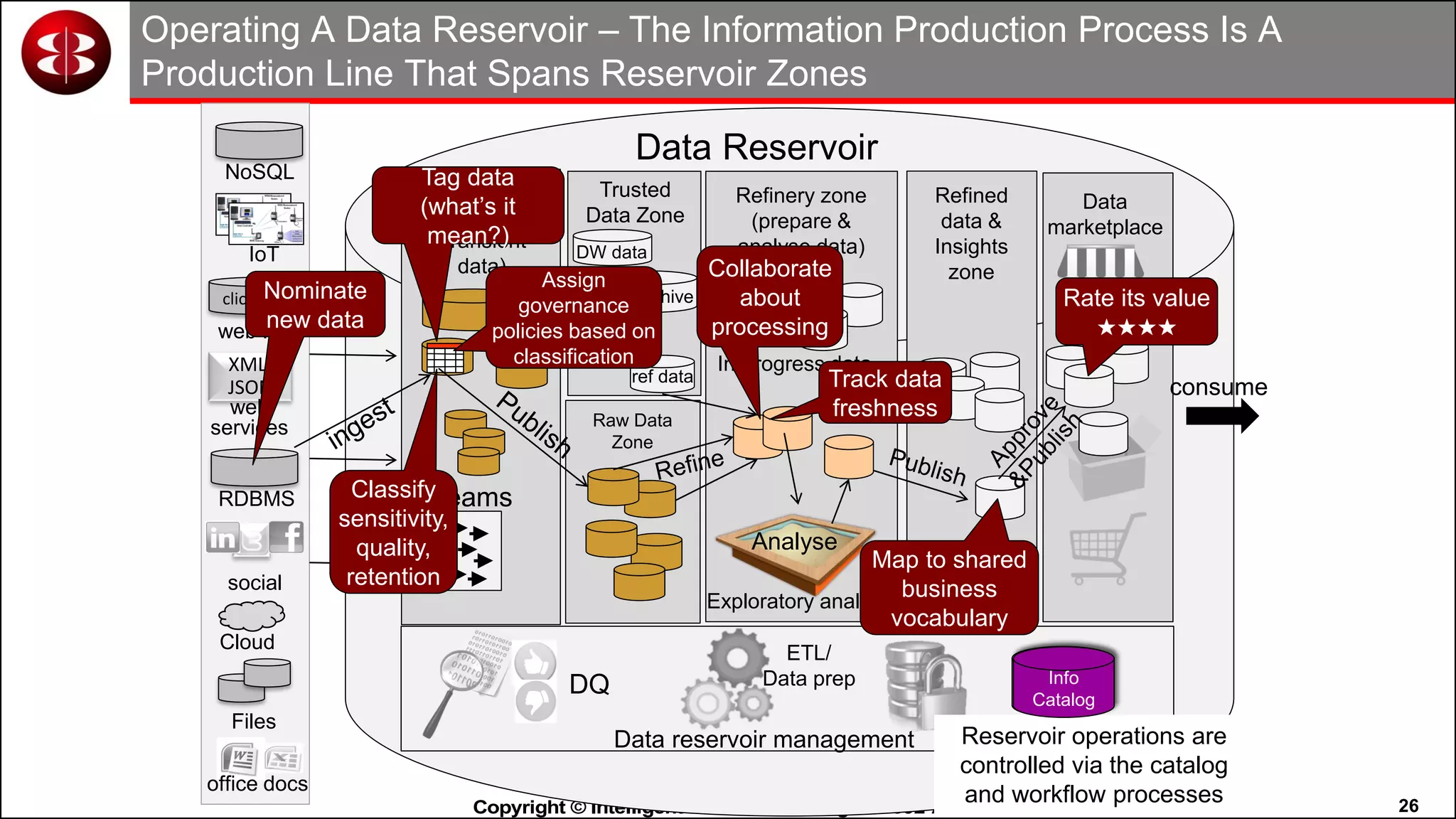
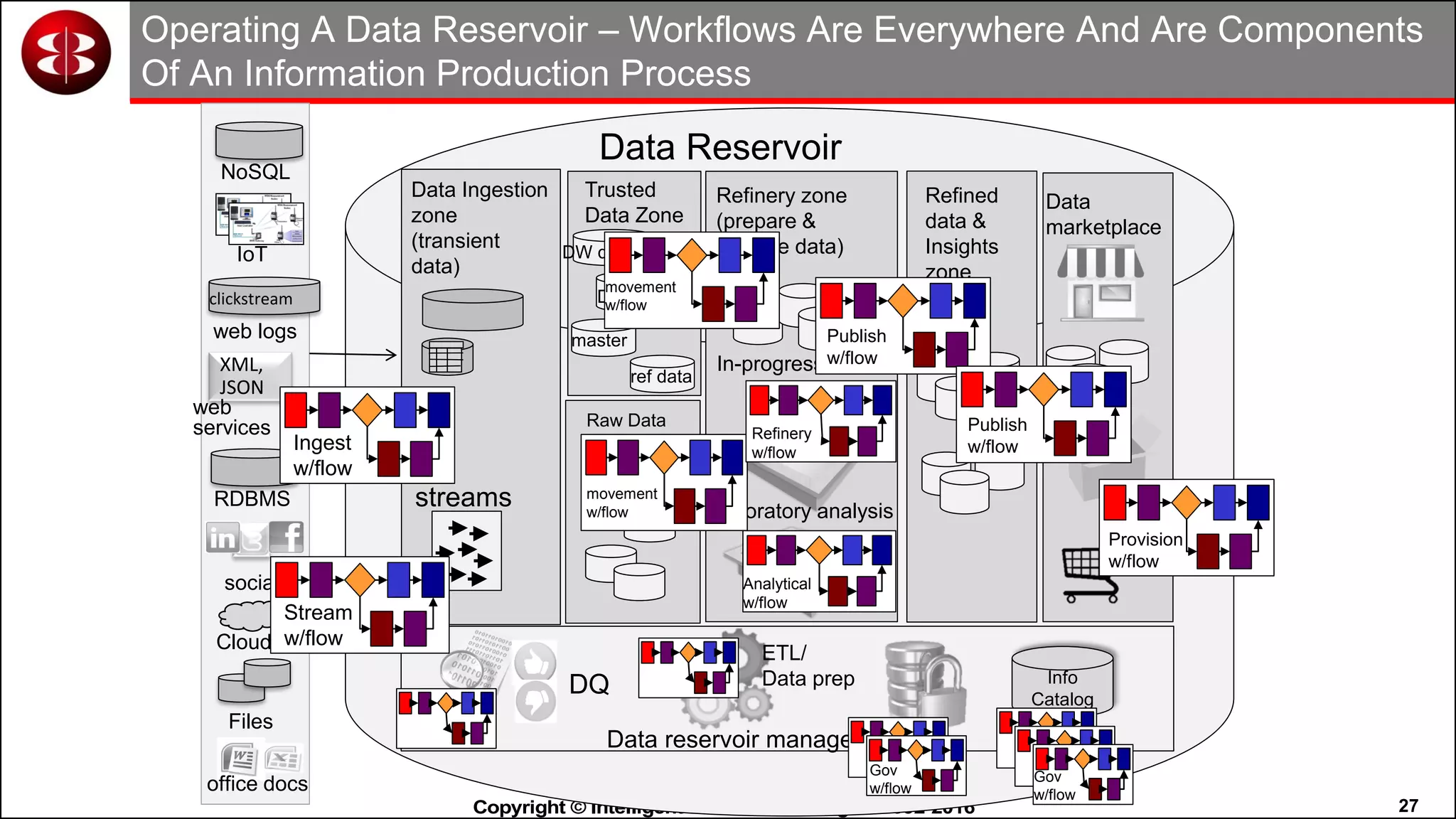


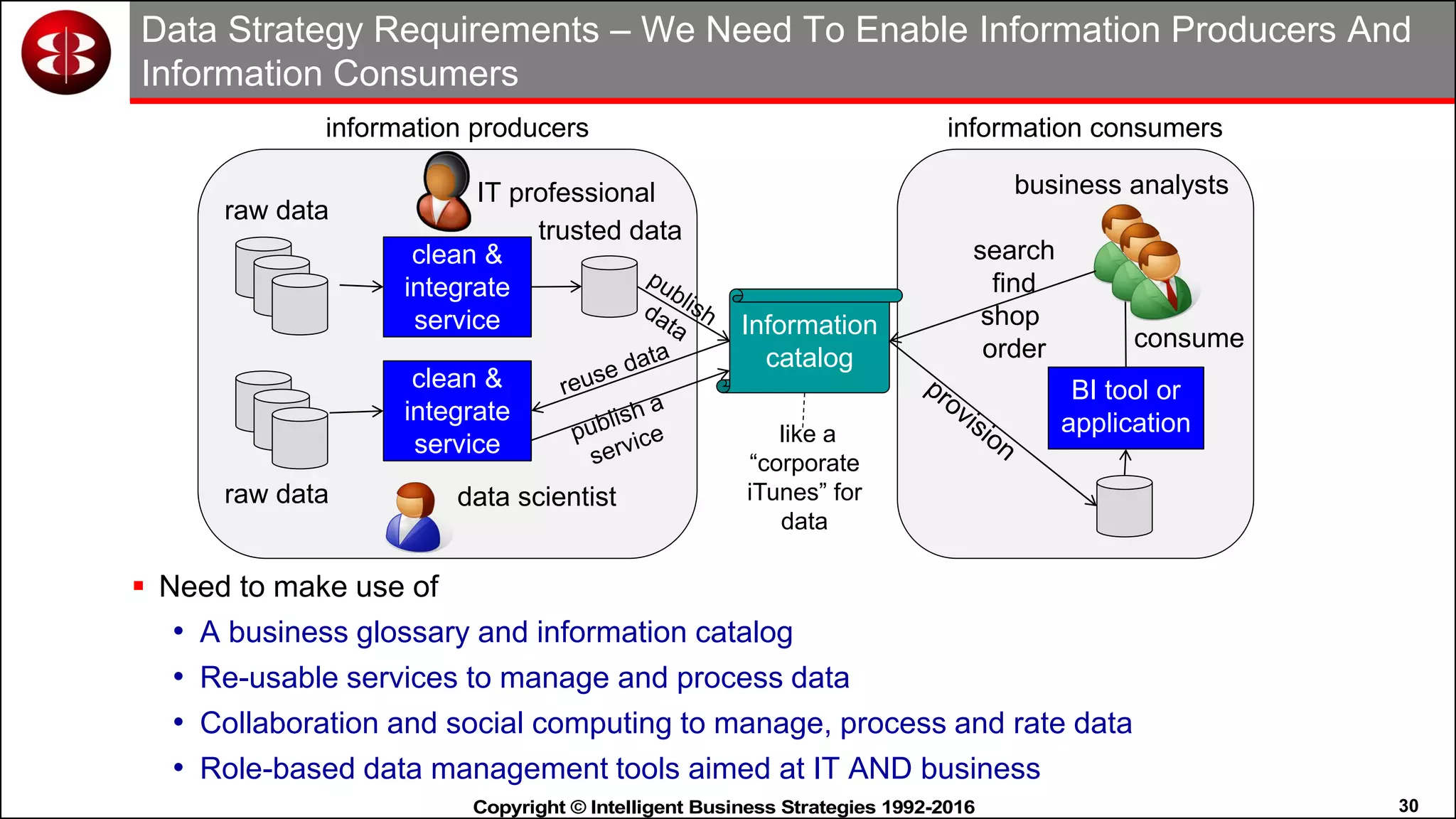
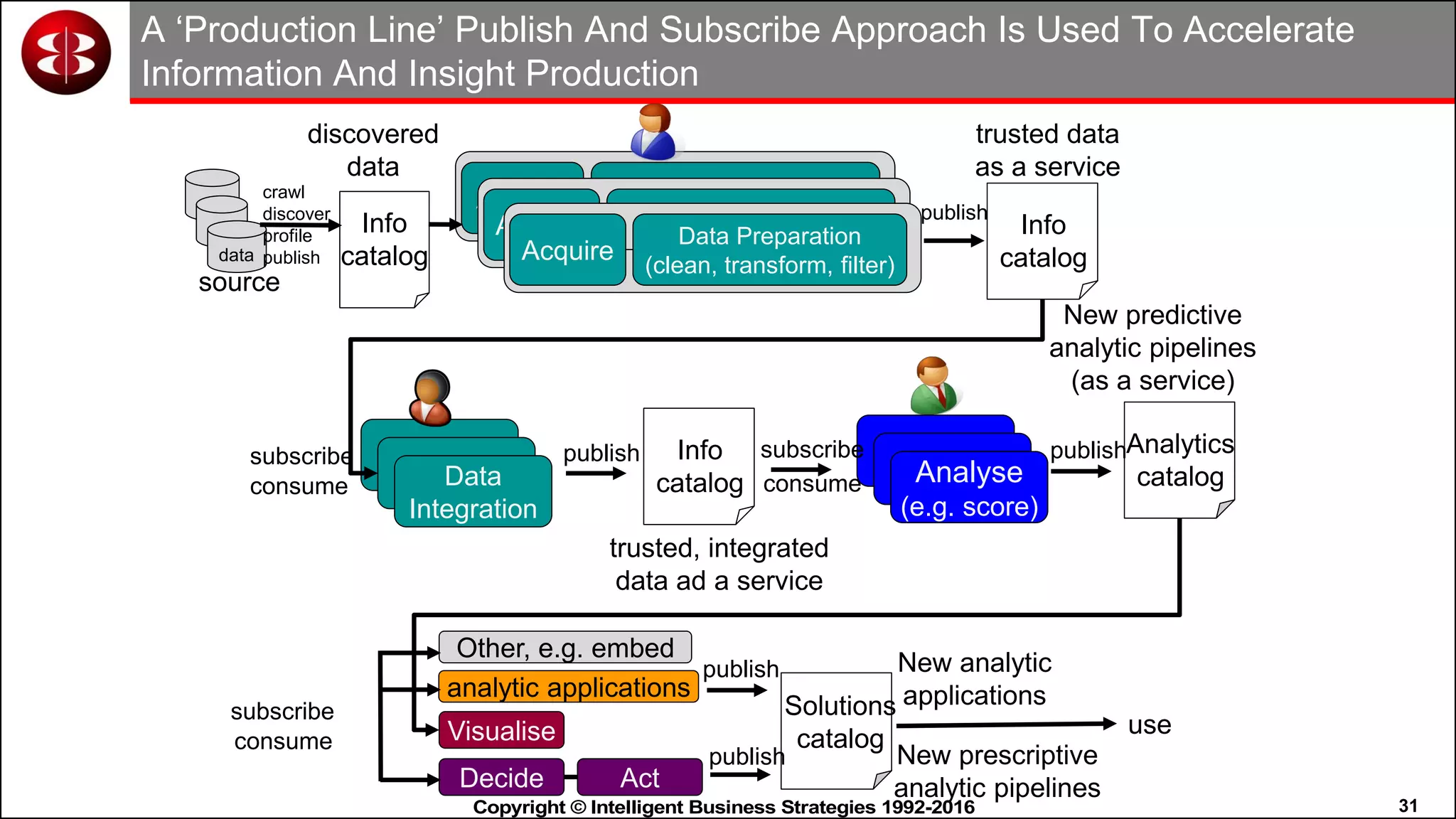
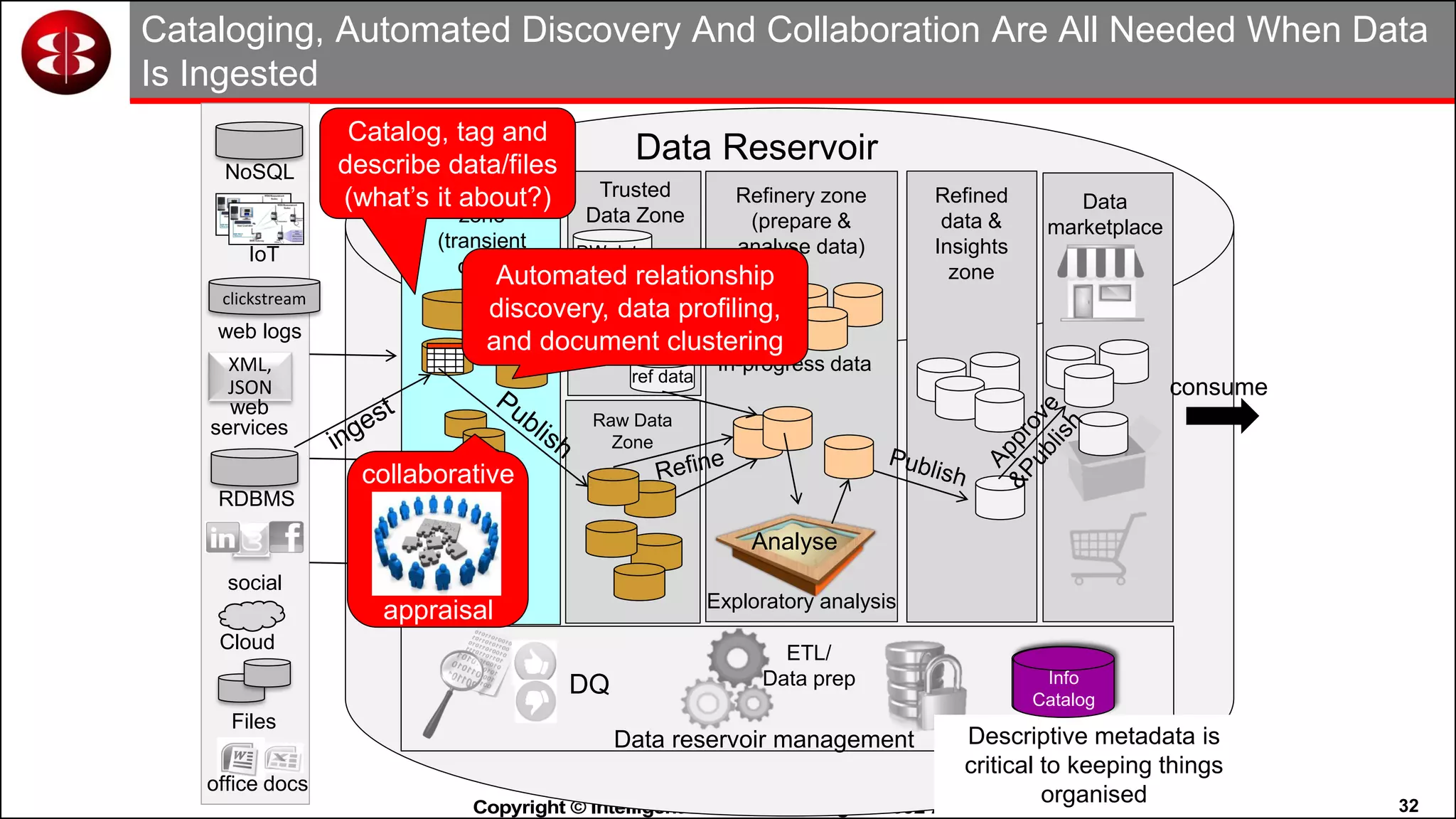

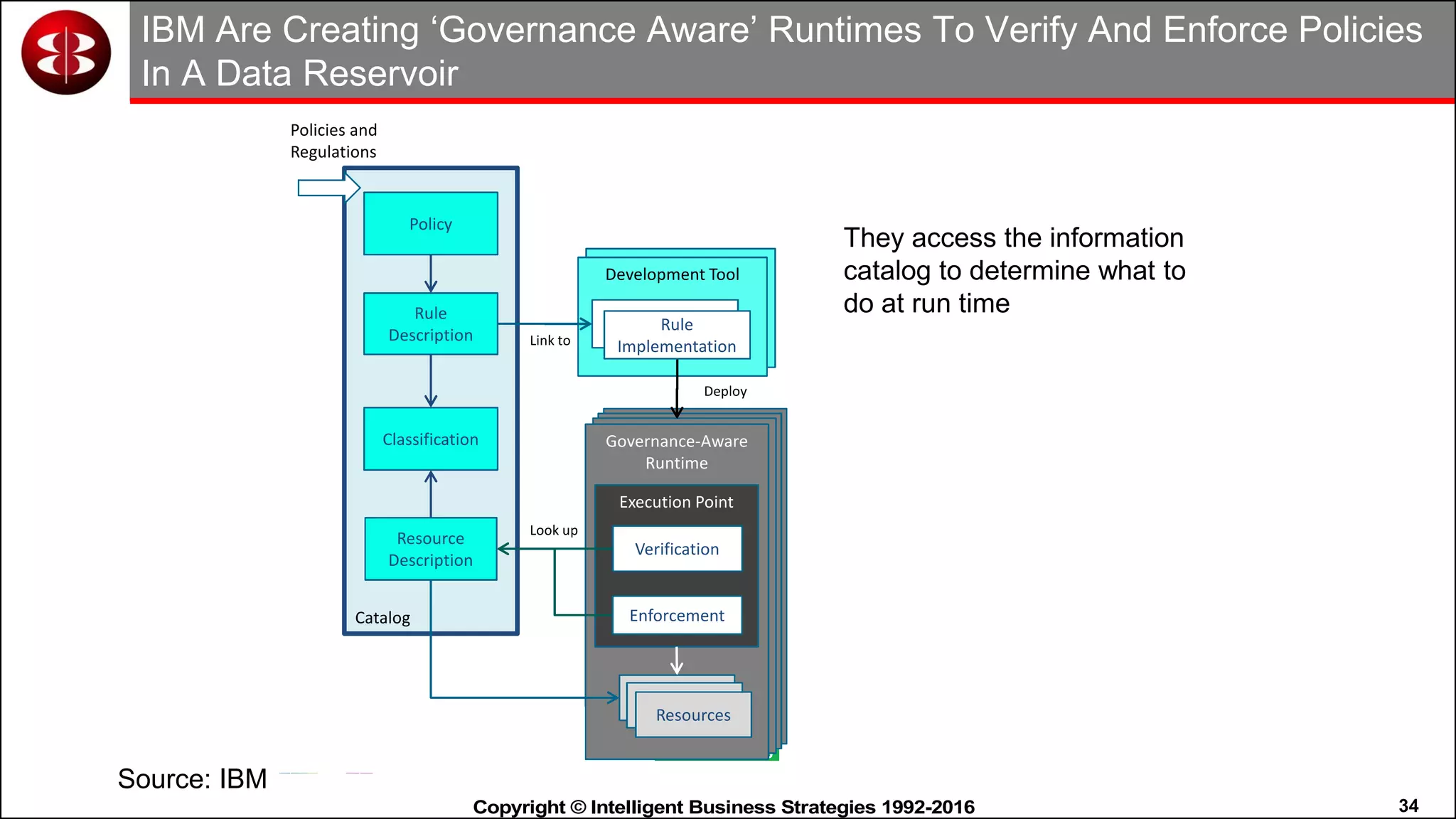

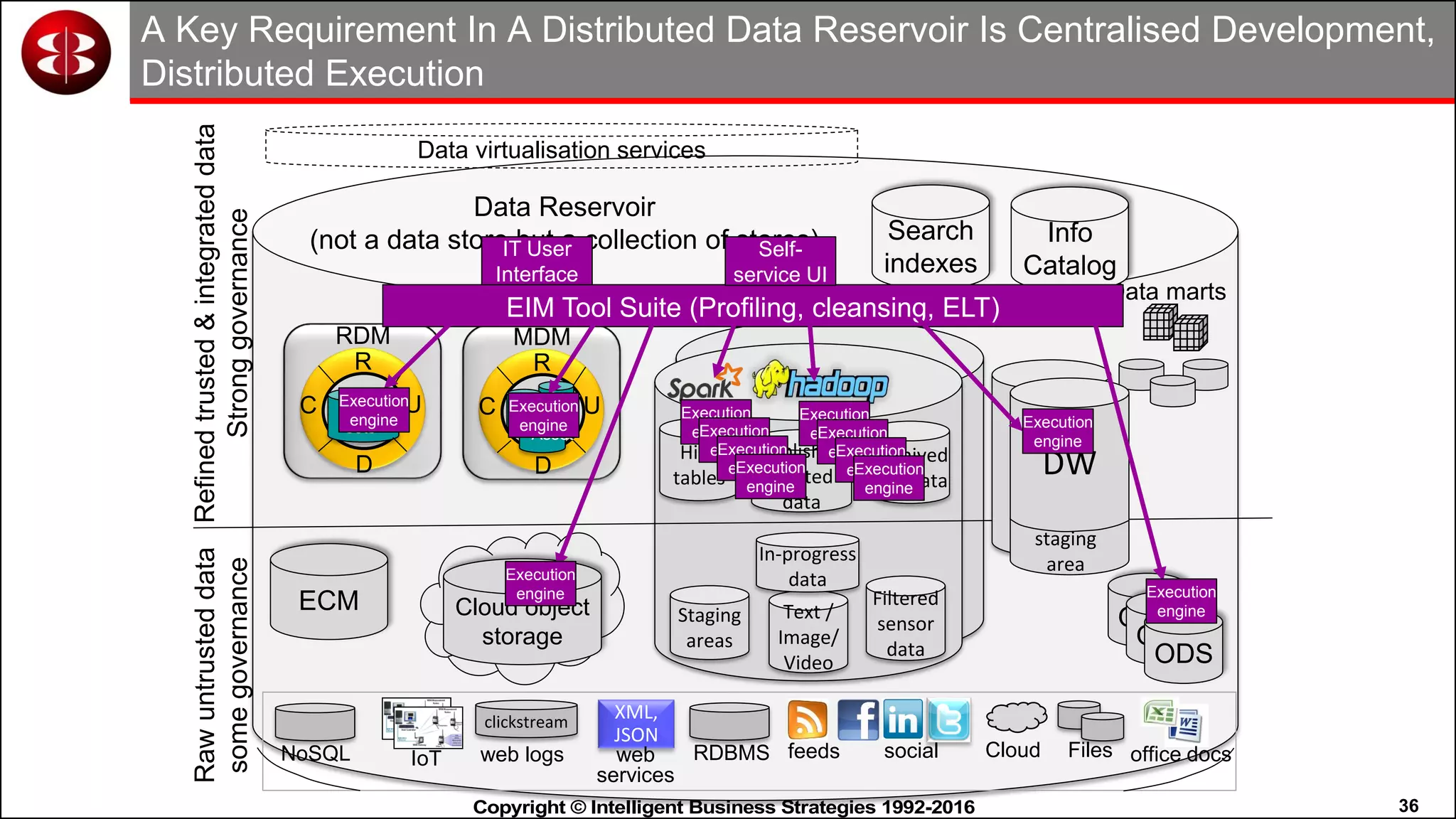
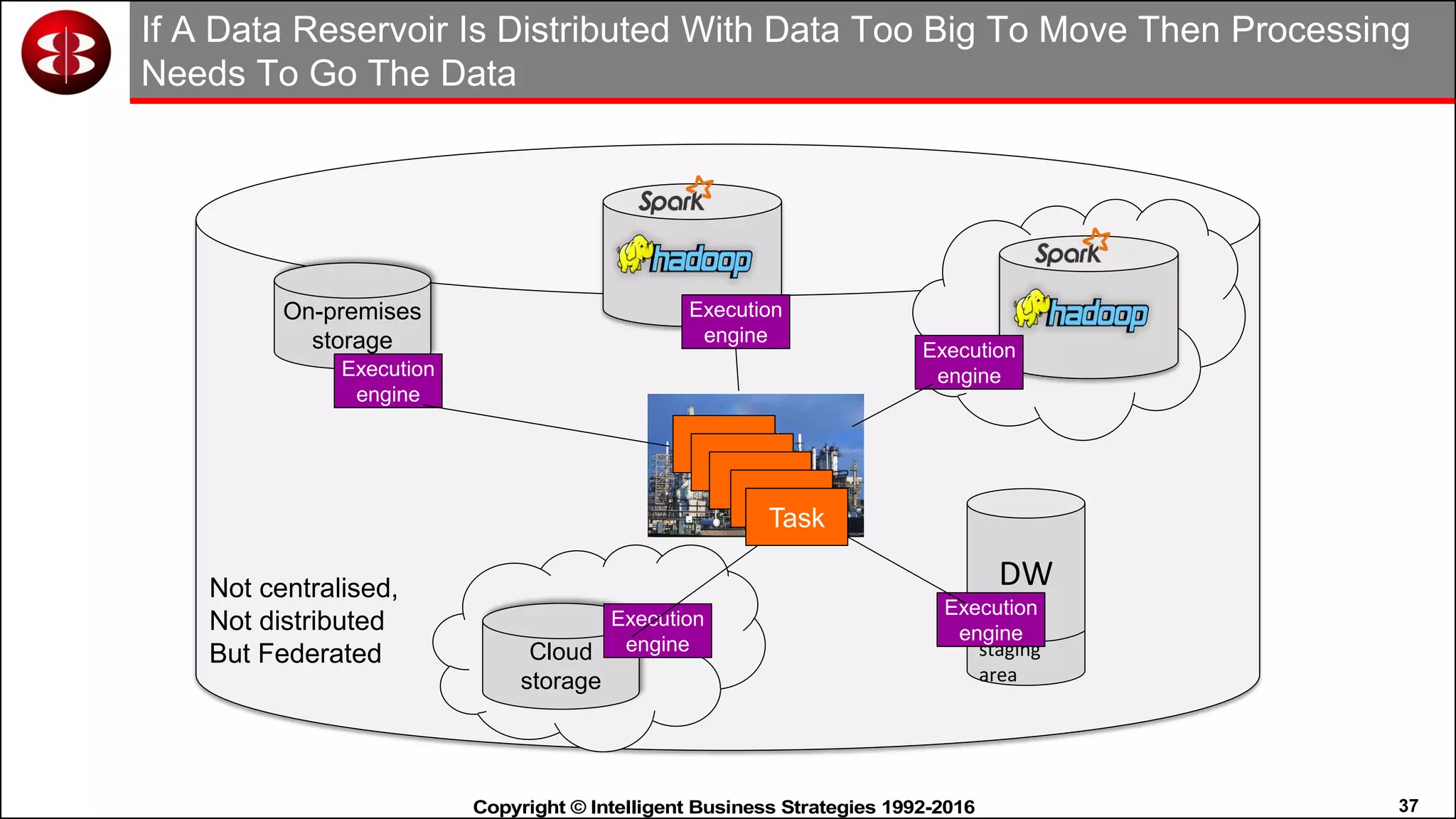

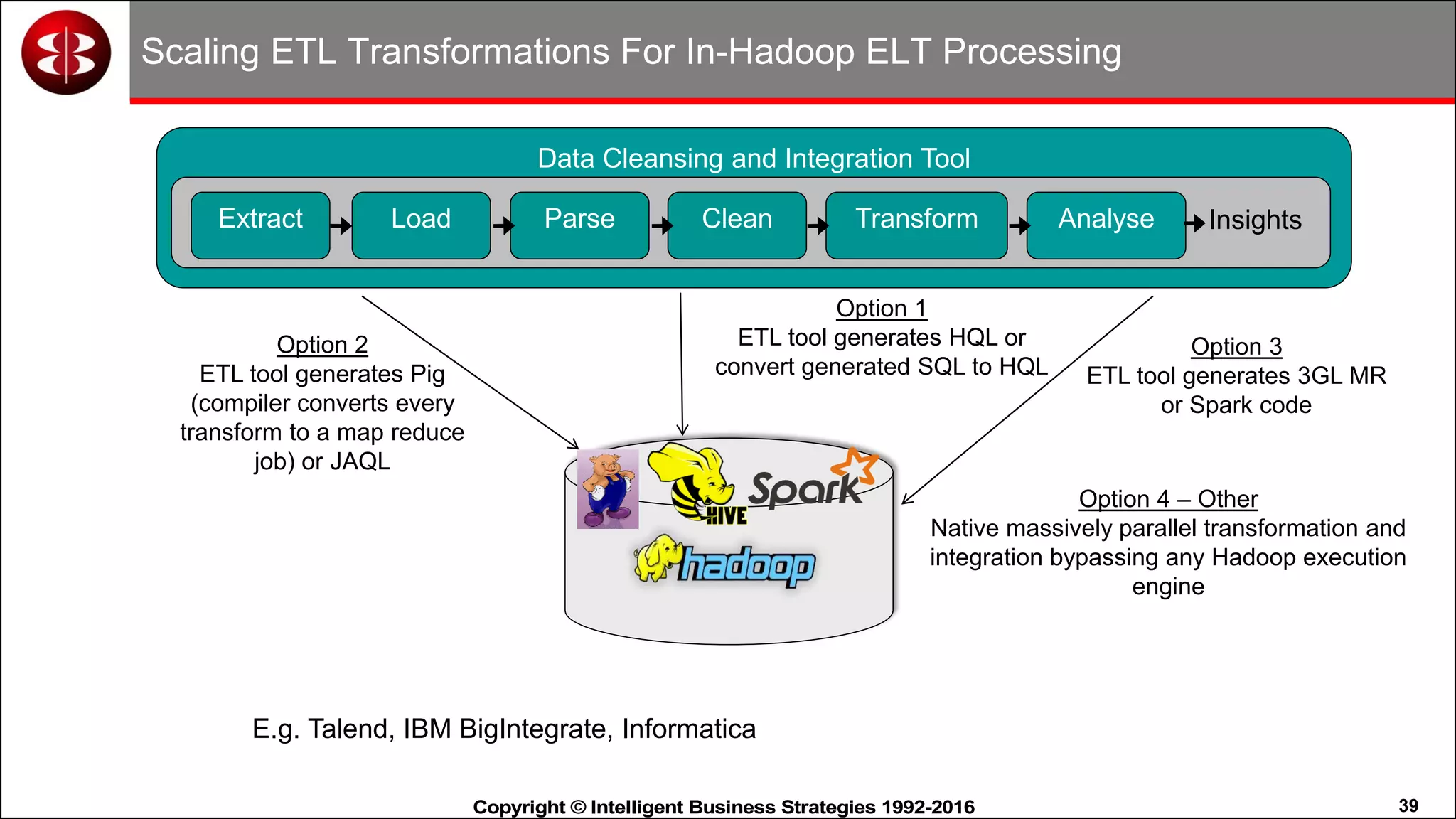
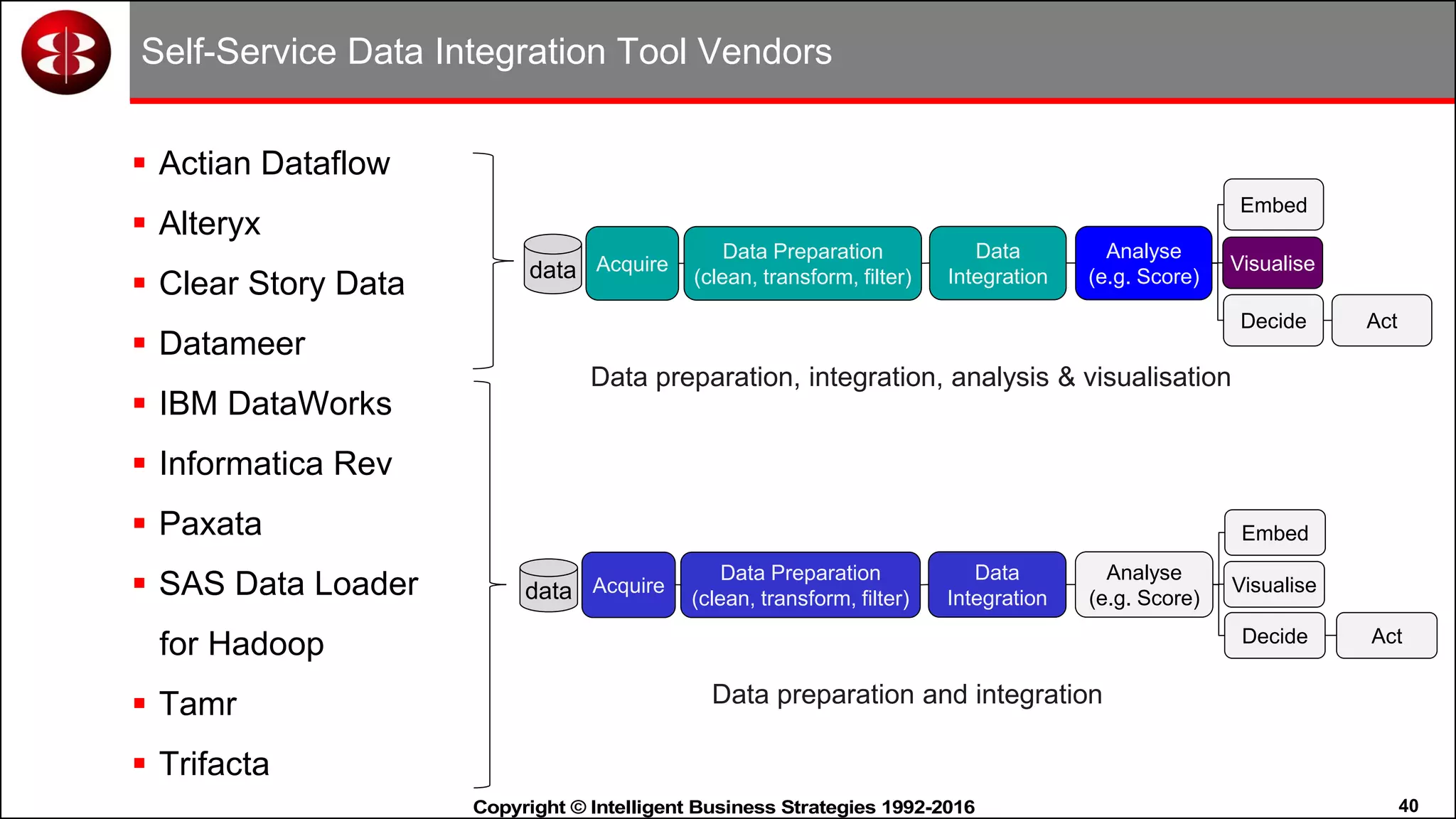
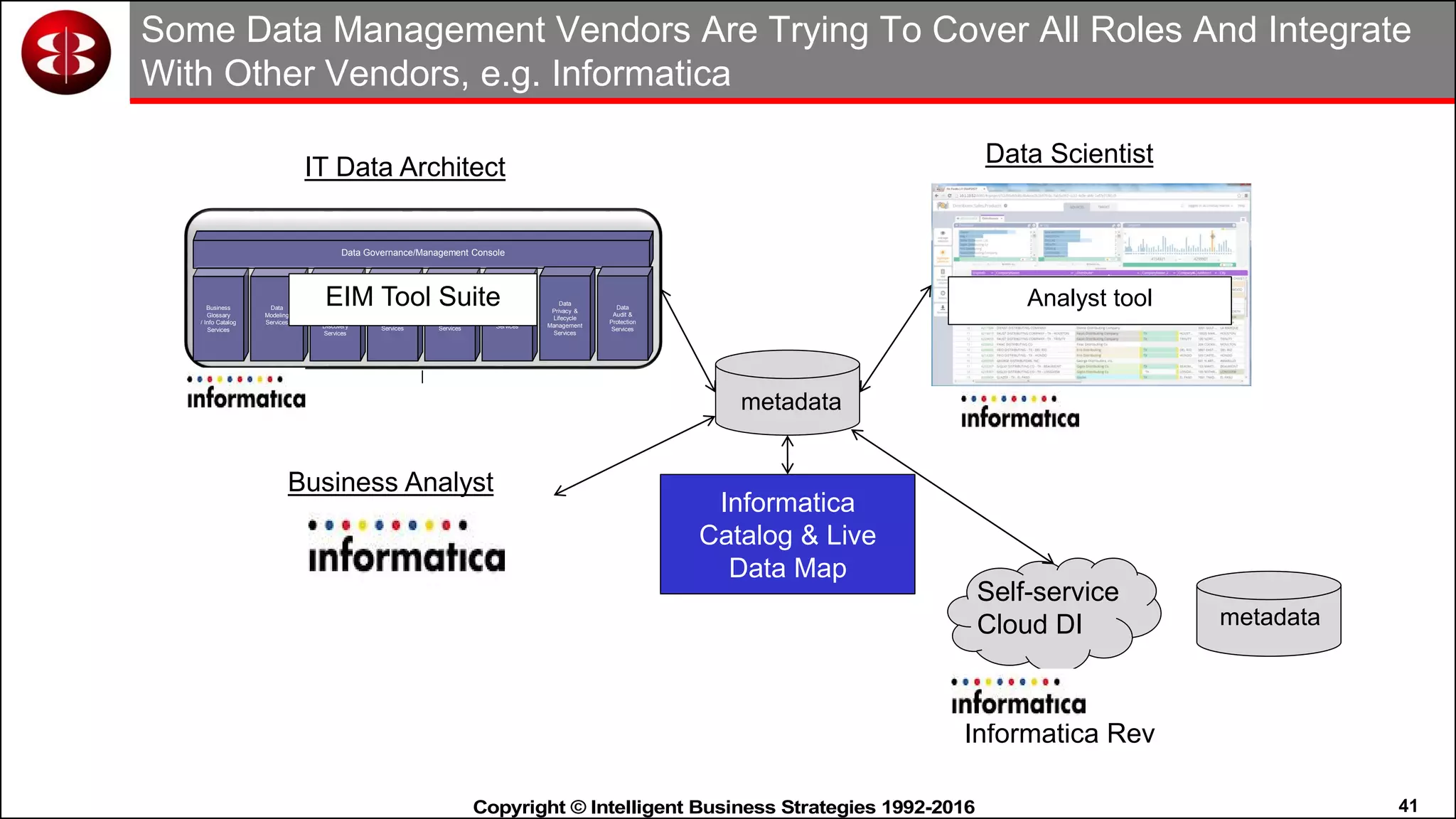
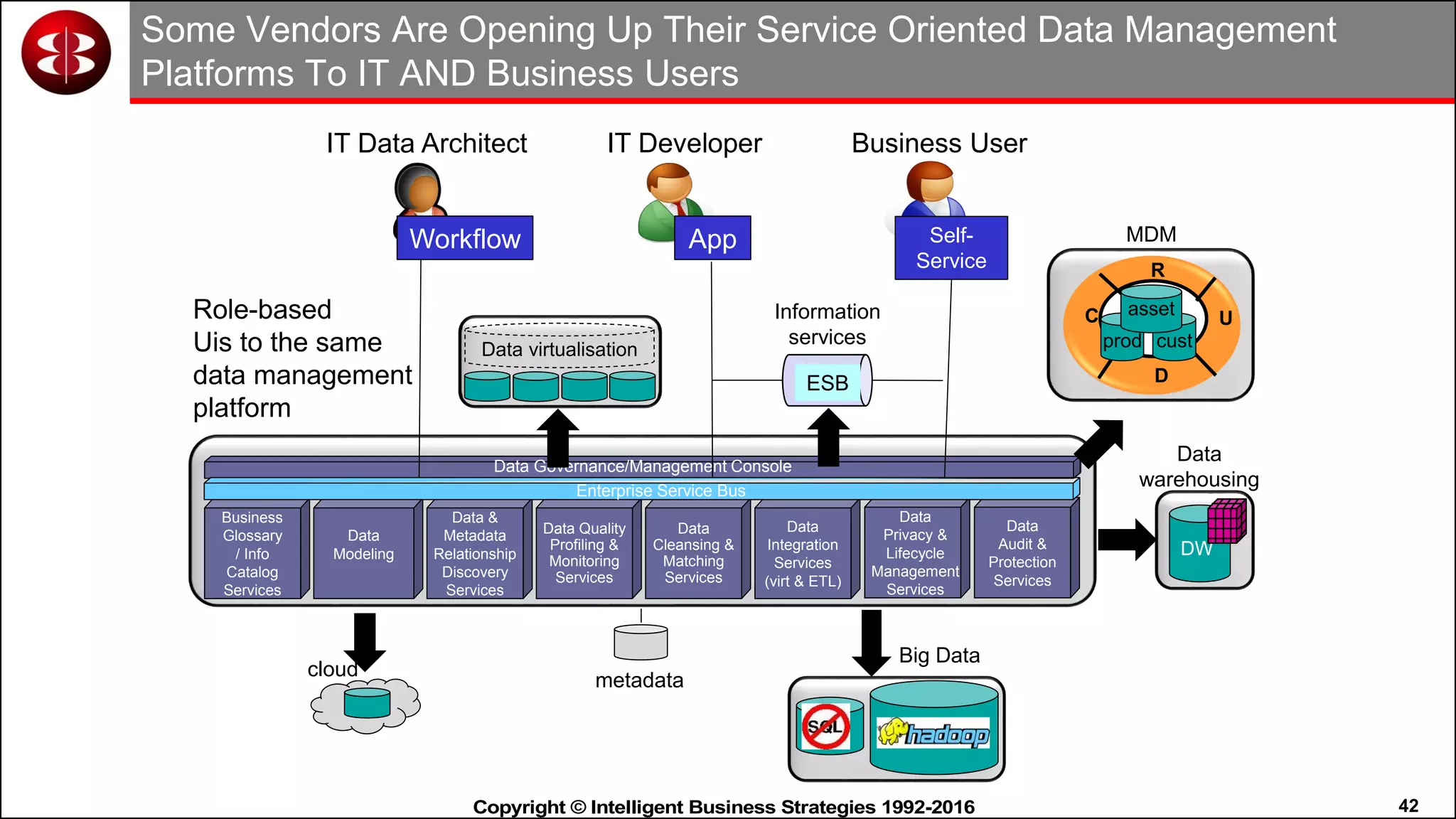













This document discusses organizing data in a data lake or "data reservoir". It describes the changing data landscape with multiple platforms for different analytical workloads. It outlines issues with the current siloed approach to data integration and management. The document introduces the concept of a data reservoir - a collaborative, governed environment for rapidly producing information. Key capabilities of a data reservoir include data collection, classification, governance, refinery, consumption, and virtualization. It describes how a data reservoir uses zones to organize data at different stages and uses workflows and an information catalog to manage the information production process across the reservoir.




































































































