Downloaded 193 times


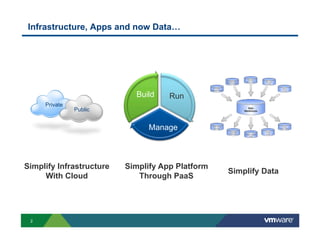
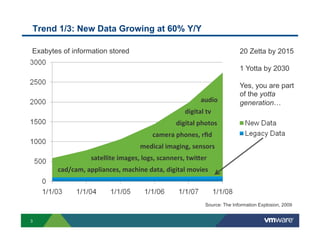
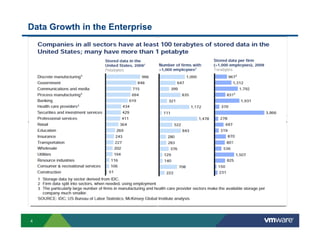


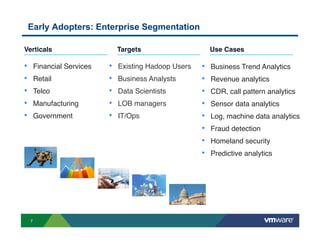

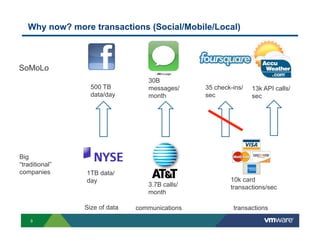
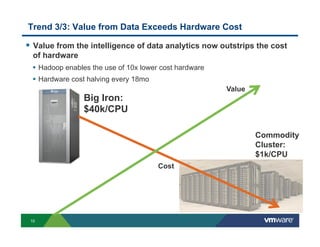
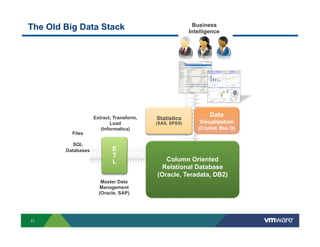
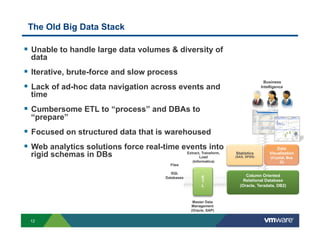
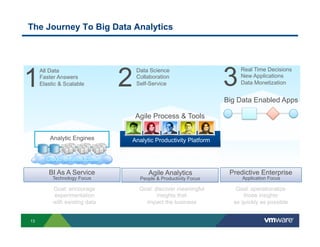
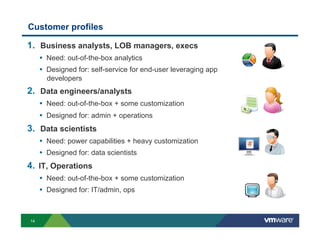
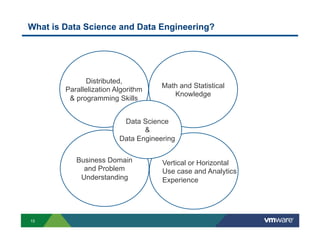
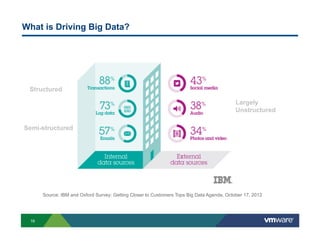
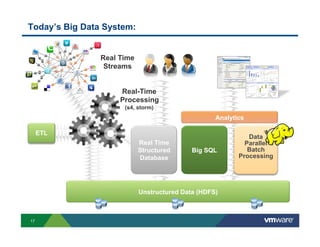
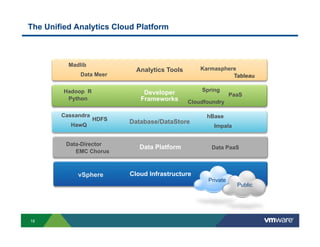
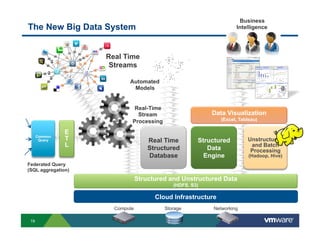
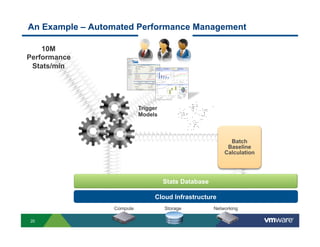

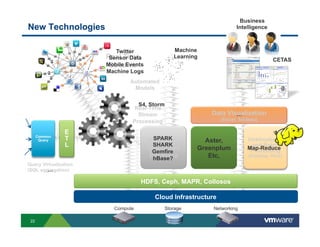

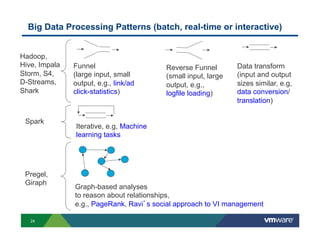

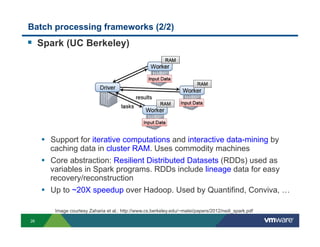
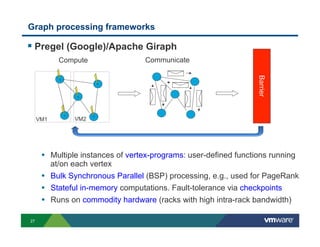
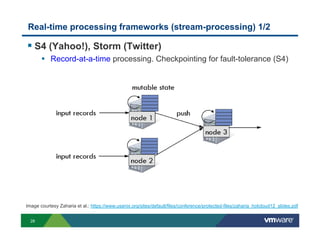
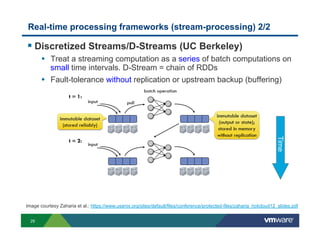
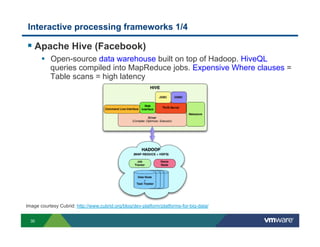

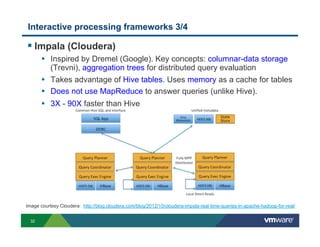


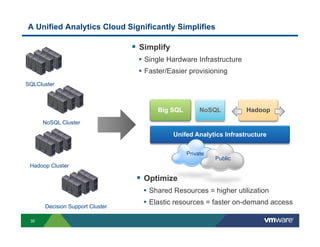
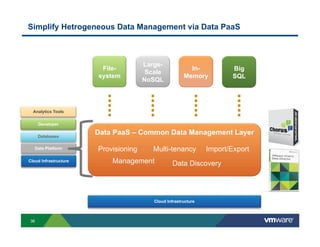
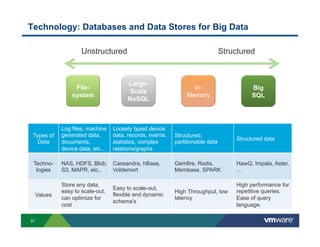
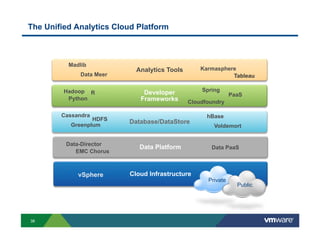



Richard McDougall discusses trends in big data and frameworks for building big data applications. He outlines the growth of data, how big data is driving real-world benefits, and early adopter industries. McDougall also summarizes batch processing frameworks like Hadoop and Spark, graph processing frameworks like Pregel, and real-time processing frameworks like Storm. Finally, he discusses interactive processing frameworks such as Hive, Impala, and Shark and how to unify the big data platform using virtualization.






















































































