Download as PDF, PPTX



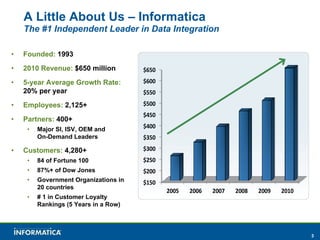
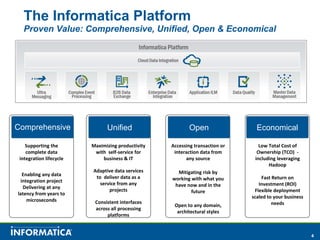

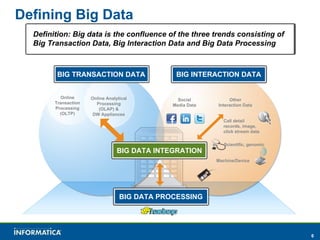



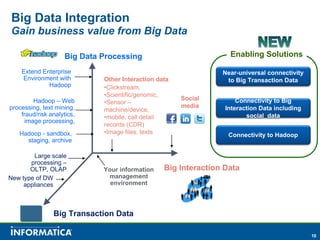
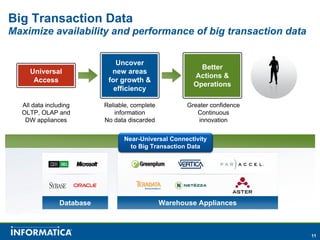
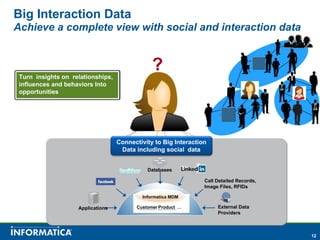
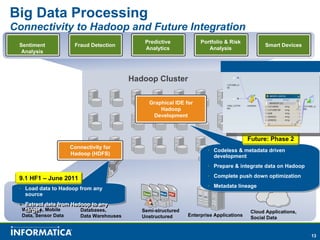

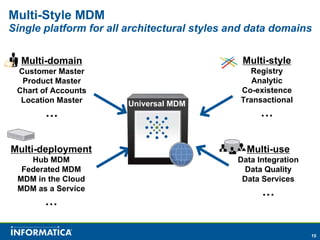


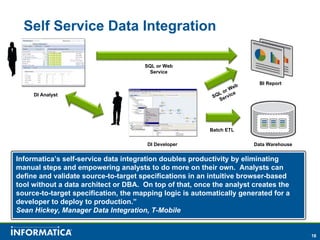
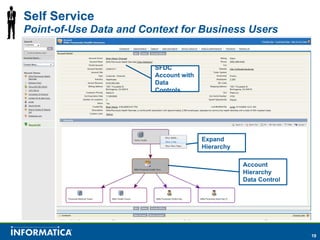


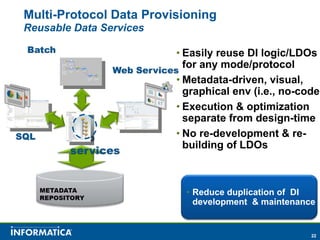

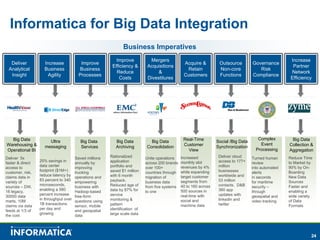




Informatica, a leader in data integration, focuses on transforming big data challenges into opportunities through comprehensive, unified, and economical solutions. The company's platform provides adaptive data services, self-service integration, and multi-style master data management to empower businesses with trustworthy and authoritative data. By leveraging big transaction and interaction data, Informatica aims to enhance operational efficiency, drive insights, and support the data-centric enterprise.



































































