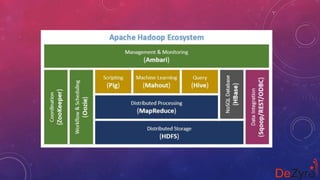
The document outlines the essential components and architecture of the Hadoop ecosystem, necessary for mastering Apache Hadoop skills in big data training. Key components include Hadoop Common, HDFS, MapReduce, YARN, Pig, Hive, Sqoop, Flume, HBase, Oozie, and Zookeeper, each serving specific roles in data processing, storage, and management. Understanding these components is crucial for efficient data analysis and processing within the Hadoop framework.