Download as ODP, PPTX






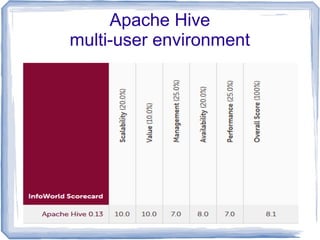

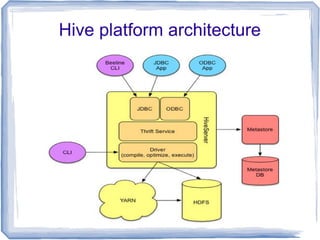












Apache Hive is a tool for analyzing large, unstructured data sets using SQL-like syntax on the Hadoop platform, acting as an operational data store that enhances existing data warehouses. It allows analysts to project database structures on unstructured data and run queries, although it has limitations compared to traditional SQL databases, such as the lack of transactions and real-time updates. Hive's performance has improved significantly with the introduction of the Tez execution framework, enabling faster query times and making it a cost-effective solution for data analytics.




























































































