Download as PDF, PPTX




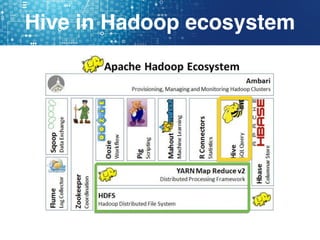



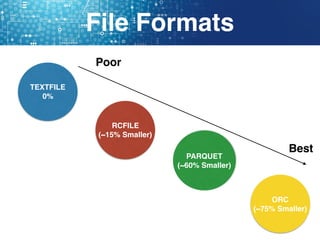






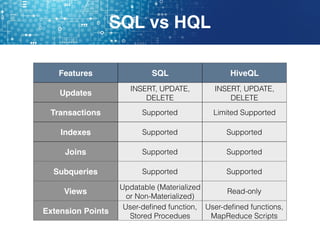

Hive is a data warehouse software that allows users to query and manage large datasets stored in Hadoop using SQL-like language called HiveQL. It facilitates reading, writing, and managing large datasets in distributed storage. Hive is best used for batch processing jobs rather than online transactions due to limitations in updating and deleting data. Common file formats used in Hive include textfiles, RCFiles, Parquet and ORC, with Parquet and ORC being preferred due to smaller file sizes.





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




