Download as PDF, PPTX


























![Self-Attention Layer
• Inputs: X = [x1, x2, … xm]
• Parameters: WQ, WK, WV (don’t share parameters)
28
This is called single-head self-attention](https://image.slidesharecdn.com/5bert-220609073059-7de45f84/85/5_BERT-pdf-28-320.jpg)















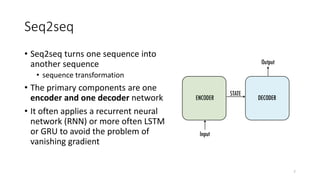
This document provides an introduction and overview of sequence-to-sequence (seq2seq) models, transformer models, attention mechanisms, and BERT for natural language processing. It discusses applications of seq2seq models like language translation and text summarization. Key aspects covered include the encoder-decoder architecture of seq2seq models, how attention improves seq2seq by allowing the model to focus on relevant parts of the context, and the transformer architecture using self-attention rather than recurrent layers. BERT is introduced as a bidirectional transformer model pre-trained on large unlabeled text that achieves state-of-the-art results for a range of NLP tasks. Code examples and homework suggestions are also provided.



































































