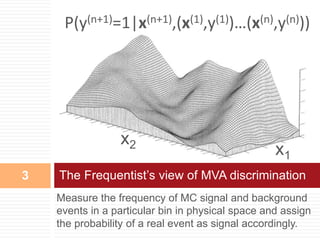
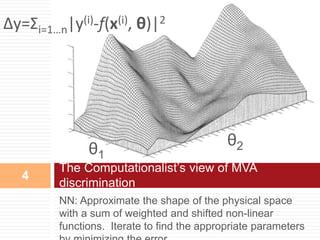
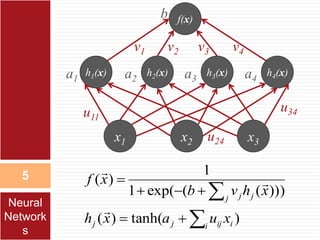
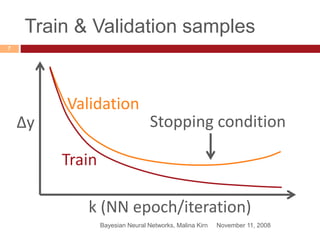
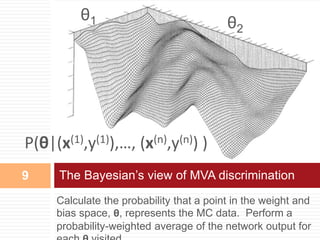
This document provides an introduction to Bayesian neural networks. It discusses how Bayesian neural networks approximate probabilities by performing a probability-weighted average over multiple neural networks, where each network's weights and biases are sampled from the posterior probability distribution. This allows the model to capture uncertainty in the network parameters rather than providing a single point estimate. The document outlines how to define prior distributions over the network weights, use Markov chain Monte Carlo methods to sample the posterior, and check for convergence using a held-out validation dataset. Bayesian neural networks are claimed to produce more accurate and stable results compared to a single neural network.










































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)




