

![Conditional Intensity Function (CIF) and
the Likelihood Function
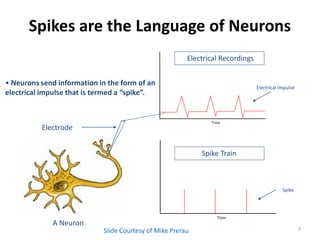
• Point Processes are modeled with CIF
Pr(Spike in (t , t + ∆t ) | H t )
λ (t | H t ) = lim = g(t, x(t), Ht; θ)
∆t → 0 ∆t
• In discrete time the log-likelihood for observing a
spike train is:
K K
log L = ∑ log[λ (tk | N1:k )∆t ]∆N k − ∑ λ (tk | N1:k )∆t
k =1 k =1
t1 t2 t3 t4 t5 t6 t7
ΔN1 ΔN2 ΔN3 ΔN4 ΔN5 ΔN6 ΔN7
0 0 1 0 0 0 1
7](https://image.slidesharecdn.com/defensepresentationyifeihuang-12722451147106-phpapp02/85/Statistical-Analysis-of-Neural-Coding-7-320.jpg)

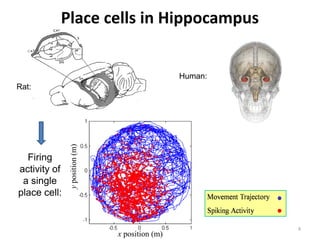
![Generalized Linear Models
• Assume that the firing activity in each neuron follows a
point process with CIF:
Spline Basis
Functions
P Q
λ (t | H t ) = exp∑ θ i g i ( x(t )) + ∑ γ j ∆N t − j
i =1 j =1
History Dependent
λ(t) Component
x(t)
• Compute the ML estimates for [θ1,…,θP, γ1,..., γQ]
10](https://image.slidesharecdn.com/defensepresentationyifeihuang-12722451147106-phpapp02/85/Statistical-Analysis-of-Neural-Coding-10-320.jpg)
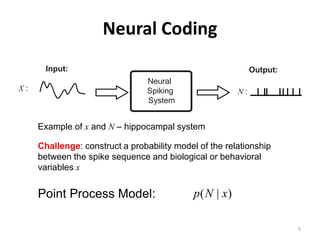
![Goodness-of-fit Results
P Q
Time-rescaling Theorem λ (t | H t ) = exp∑ θ i g i ( x(t )) + ∑ γ j ∆N t − j
(Meyer,1969 ; Papangelou,1972) i =1 j =1
λ (t | H t )dt
si +1
zi = ∫
si
~ i.i.d. exp(1)
KS Plot KS Plot
ui = 1 − exp(− zi )
~ i.i.d. Uniform [0,1]
Kolmogorov-Smirnov
Statistic
(Chakravarti et al., 1967)
KS = max Femp − F
F(u) = u Q=0 Q = 17
12](https://image.slidesharecdn.com/defensepresentationyifeihuang-12722451147106-phpapp02/85/Statistical-Analysis-of-Neural-Coding-12-320.jpg)









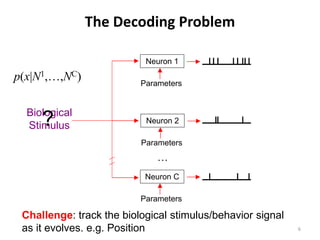
![Test Statistics for Differential Firing
• Integrated squared error statistic:
ISE = ∫
0
D
(ˆ
L
ˆ
0 ) ( ˆ
R
ˆ
0 )
λ ( x) − λ ( x) 2 + λ ( x) − λ ( x) 2 dx
• Maximum difference statistic:
MD = max λL ( x) − λR ( x)
ˆ ˆ
x∈[ 0 , D ]
• Likelihood ratio statistic:
L0
W = −2 log
L1
24](https://image.slidesharecdn.com/defensepresentationyifeihuang-12722451147106-phpapp02/85/Statistical-Analysis-of-Neural-Coding-24-320.jpg)


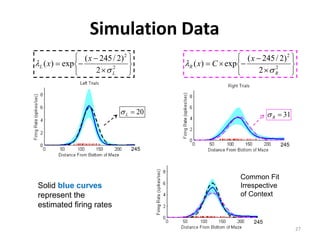








This thesis analyzes neural coding in the hippocampus using statistical modeling techniques. It summarizes experiments recording neural activity from place cells in rats navigating a T-maze. Generalized linear models are used to model each neuron's firing rate based on position and firing history. Goodness of fit tests show many neurons are well modeled. An algorithm is derived to decode position from the ensemble activity using Bayes' rule and numerical integration of the exact posterior distribution. The models and decoding algorithm are applied to analyze the hippocampal population code.











































![[IJCT-V3I2P19] Authors: Jieyin Mai, Xiaojun Li](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p19-160609061509-thumbnail.jpg?width=640&height=640&fit=bounds)



