Download as PDF, PPTX



























![Создаём кластер PostgreSQL
29/36
Решаем проблемы с помощью PgBouncer:
pgbouncer.ini:
[databases]
main = host=db-main pool_size=5 connect_query=
'select prepare_statements_and_stuff()'
[pgbouncer]
listen_port = 6432
listen_addr = *
pool_mode = transaction
max_client_conn = 1024](https://image.slidesharecdn.com/avito-160610191033/85/Avito-29-320.jpg)




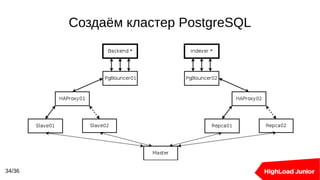



Документ описывает создание и управление кластерами баз данных, включая Redis, Memcached и PostgreSQL. Основные темы включают балансировку нагрузки, методы масштабирования, репликацию, а также шардирование с использованием различных инструментов и стратегий. Он также предоставляет статистику и примеры конфигурации для оптимизации работы с высоконагруженными системами.























































































