Download as PDF, PPTX








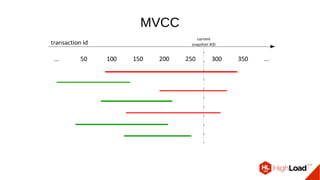
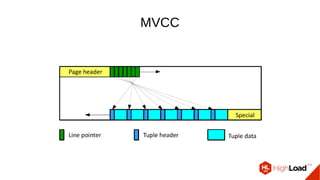
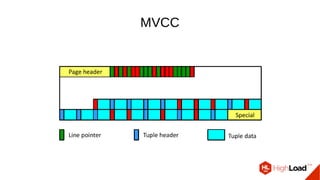
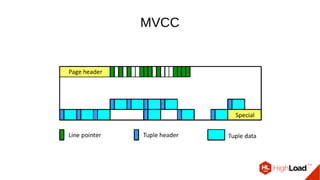
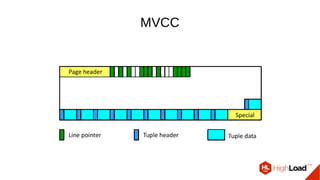





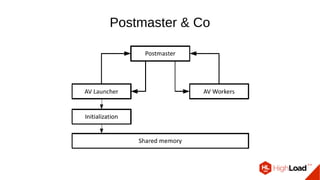




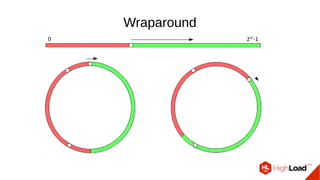








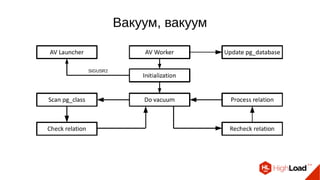
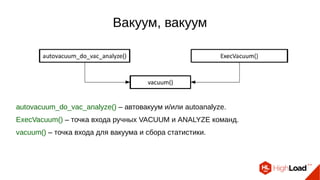















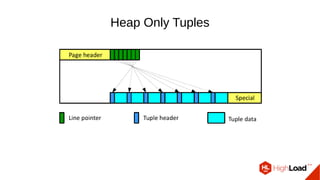
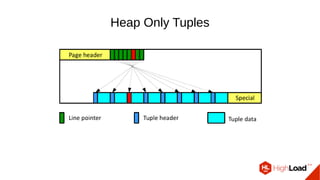
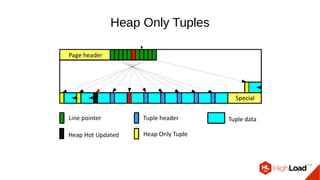
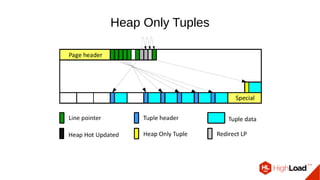
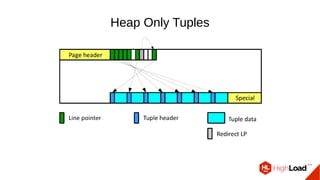












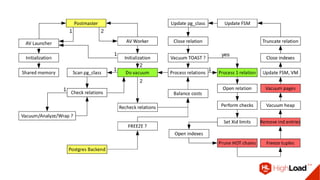


Документ обсуждает важность процесса вакуума в PostgreSQL, указывая на его влияние на производительность системы. Приводятся детали настройки вакуума, включая параметры, которые влияют на эффективность команды и настройки автоматического вакуума. Описываются аспекты работы MVCC, фоновых процессов и стратегий обработки таблиц для оптимизации управления пространством.























































































