Download as PDF, PPTX







![● Isolation — выполнение параллельных транзакций имеет
тот же эффект что и их последовательное применение
● Consistency без isolation не достижим
● Пусть есть x, y, z – данные к которым осуществляется
совместный доступ
● Расписание (schedule) — возможная история
выполнения транзакций, конкретный порядок операций
чтения и записи относительно друг друга
E = r1[x] w1[x] w2[y] r2[z]
Isolation](https://image.slidesharecdn.com/2-160115110522/75/Tarantool-org-8-2048.jpg)

![● Мы говорим, что история выполнения транзакций
последовательна, если их действия в истории не
пересекаются:
E = r1[x] w1[y] commit1 w2[y] r2[z] commit2
● Принцип two phase locking — локи захваченные
транзакцией не должны освобождаться до commit
● Насколько это строгое требование? Предположим
обратное:
E = r1[x] r2[y] w2[x] w1[y]
- не существует сериального выполнения t1 и t2 (их всего
два — t1 t2 или t2 t1) с тем же эффектом
Формализация: serial history](https://image.slidesharecdn.com/2-160115110522/75/Tarantool-org-10-2048.jpg)

























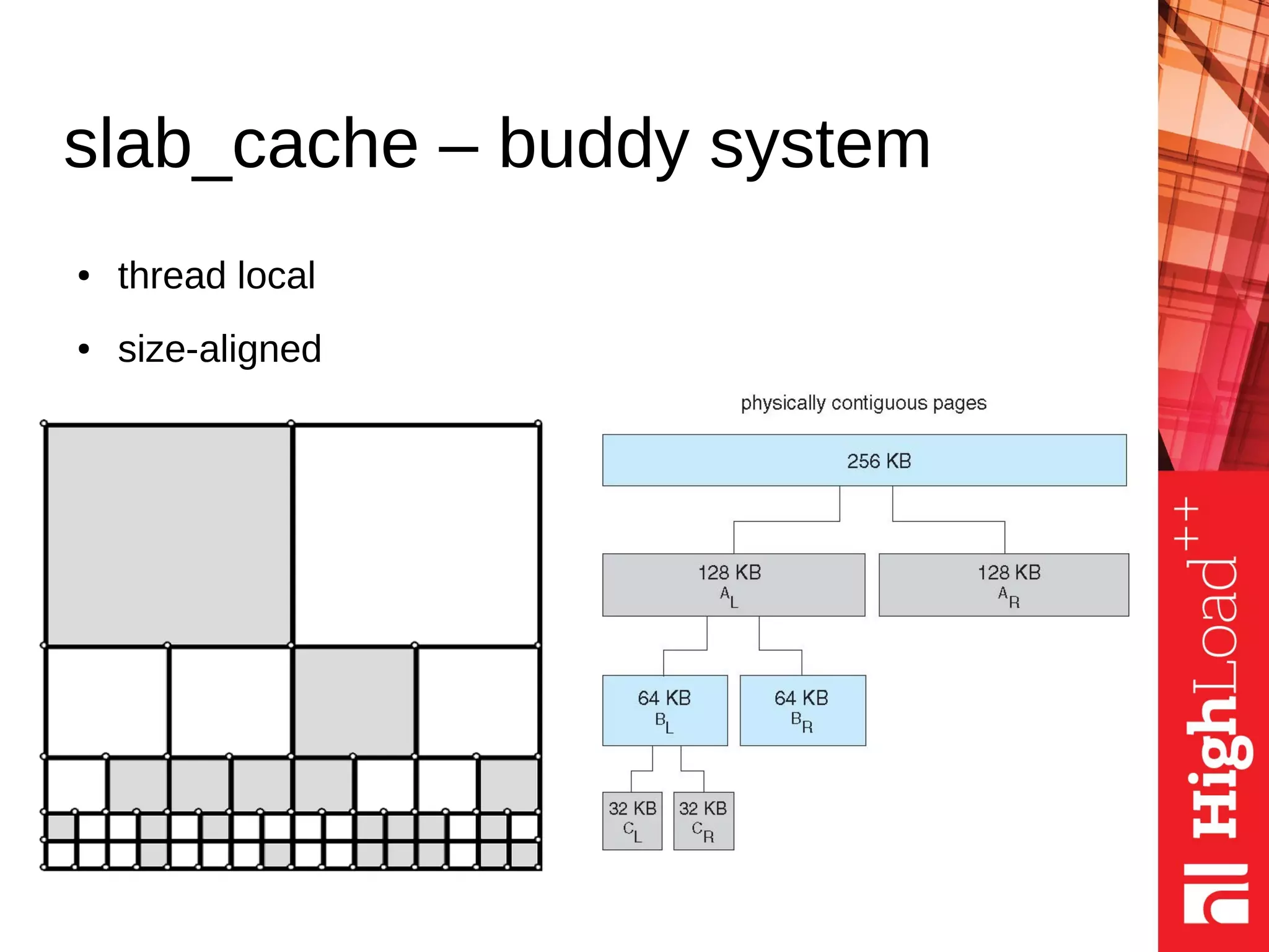





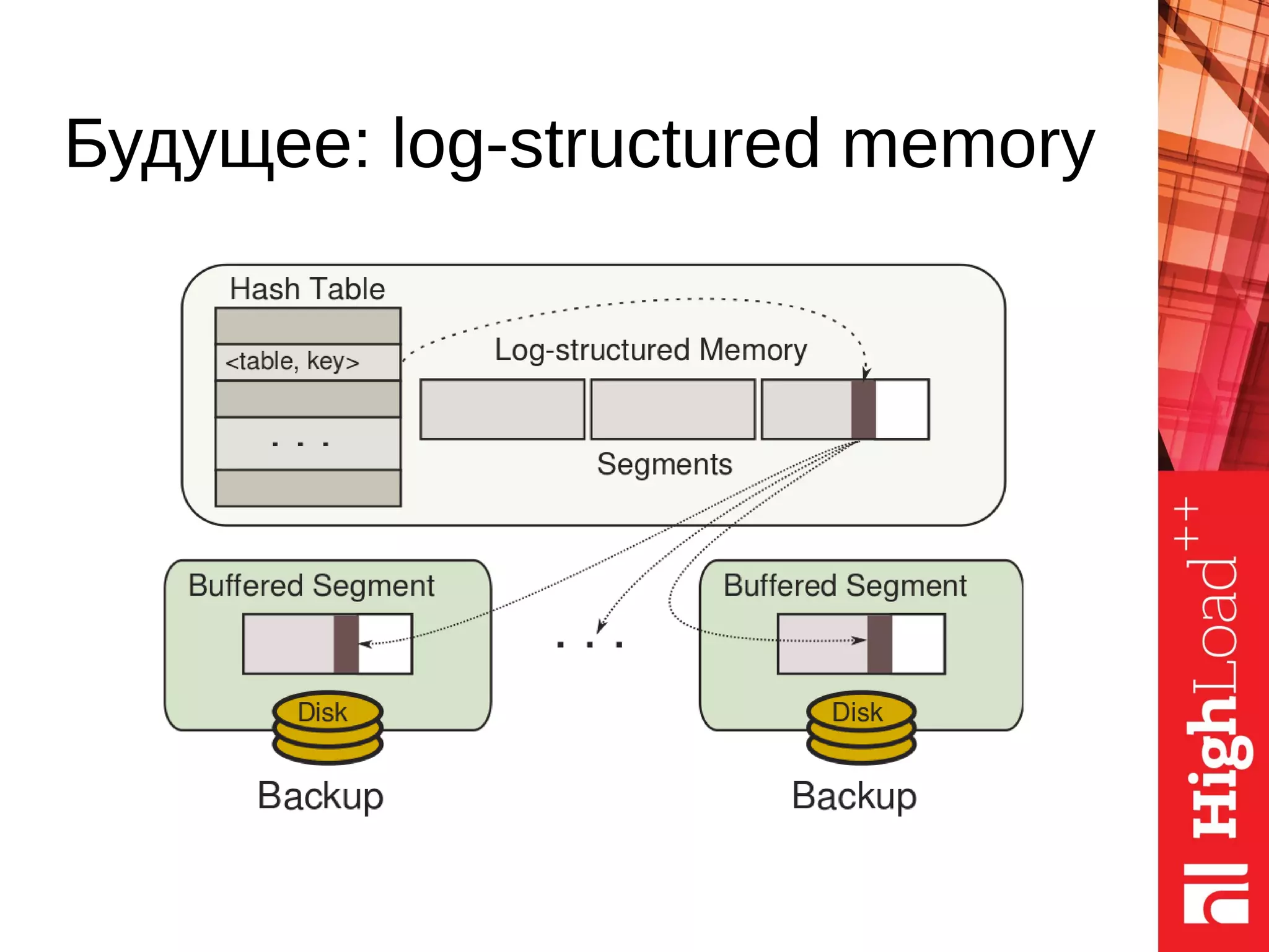



![Inner nodes
Leaf nodes
● K-ary (k-way) tree
● well balanced
● same size for leafs and
inner nodes (512 B)
● non-root nodes are filled
[2M/3..M]
● root may be filled [1..M]
bps_tree](https://image.slidesharecdn.com/2-160115110522/75/Tarantool-org-47-2048.jpg)
![Leaf node
Header Tuple[0] Tuple[1] Tuple[2] ...
Up to 62 pointers to tuples, sorted by key definition
Inner node
Header MaxTuple[0] MaxTuple[1] ... Id[0] Id[1] Id[2] ...
Matras IDs of subtrees
MaxTuple[i - 1] < {All tuples in subtree i} ≤ MaxTuple[i + 1]
Up to 42 subtrees with their maximal tuples (except last subtree)
Subtrees are sorted by their maximal tuples
Maximal tuple of maximal subtree is stored in upper node
Maximal tuple of maximal subtree in root is stored in special place of tree
Maximal tuple pointer in leaf node is copied exactly once somewhere in
upper nodes of the tree, except of last tuple, that stored in special place
bps_tree](https://image.slidesharecdn.com/2-160115110522/75/Tarantool-org-48-2048.jpg)





Документ обсуждает алгоритмы и структуры данных, применяемые в системах управления базами данных (СУБД) в оперативной памяти. Основное внимание уделяется принципам ACID, блокировке транзакций и специализированным аллокаторам памяти для повышения производительности. Описаны модели конкурентного выполнения и их влияние на структуру данных, включая подробности о b-деревьях и возможностях логической памяти.























































































