Download as PDF, PPTX













![Регулярные выражения в proxy_redirect
• Директиву
proxy_redirect
теперь
можно
использовать
с
регулярными
выражениями:
proxy_redirect ~/user/([^/]+)/(.+)$
http://$1.example.com/$2;
• Директивы
proxy_cookie_path,
proxy_cookie_domain
для
изменения
кук
при
проксировании:
proxy_cookie_domain localhost example.org;
proxy_cookie_path
/two/
/;](https://image.slidesharecdn.com/4-131107082446-phpapp01/85/Nginx-Inc-15-320.jpg)































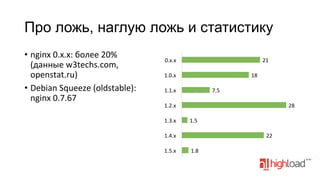
Документ обсуждает обновления и новые функции в различных версиях nginx, включая улучшения в кэшировании, поддержку криптографии, оптимизации для работы с SSL, а также возможности для управления соединениями и запросами. Основные новшества затрагивают версии 1.1.x, 1.3.x и 1.5.x, включая поддержку WebSocket, Etag, и небуферизированную работу с fastcgi. Документ также упоминает о коммерческой версии nginx Plus с дополнительной функциональностью.









































































