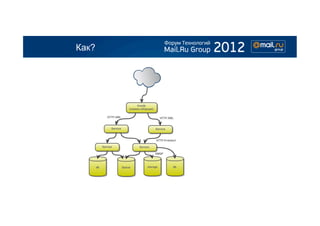
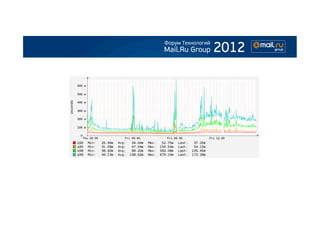
Документ обсуждает переход на сервисно-ориентированную архитектуру, рассматривая преимущества, такие как контролируемая деградация и выбор языков программирования для различных задач. Описываются сложности, связанные с виртуализацией, логированием и мониторингом, а также предлагаются решения для управления логами и деплоем сервисов. Результатом является вывод о том, что разделение монолитного приложения на сервисы может быть полезным, но требует усовершенствования инфраструктурных инструментов для поддержания контроля над системой.