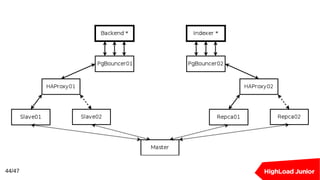
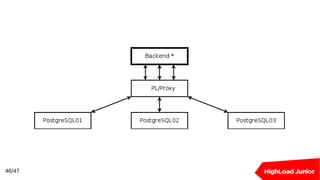
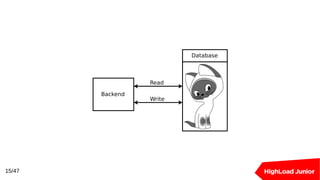
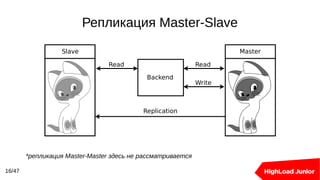
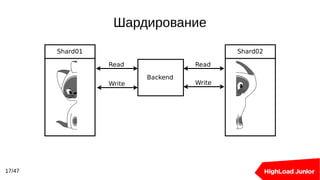
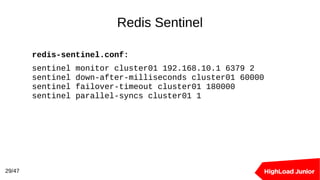
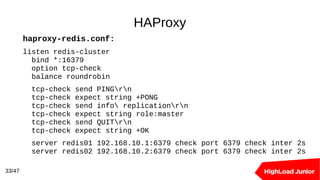
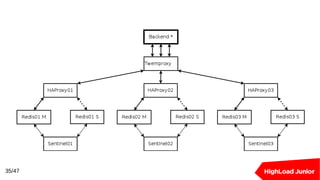
Документ рассматривает подходы к созданию кластеров баз данных для обработки высоких нагрузок. В нем освещаются методы балансировки, масштабирования и обеспечения отказоустойчивости для Redis и PostgreSQL, включая использование прокси-серверов и репликации. Ключевыми темами являются шардирование, автоматическое переключение при отказах и оптимизация подключения к базе данных.




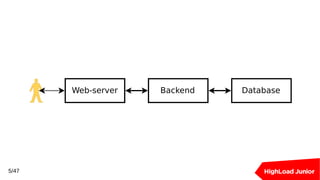
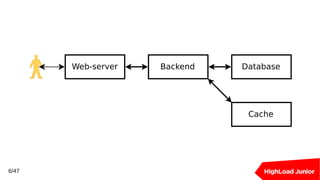





















![Решаем проблемы с помощью PgBouncer
39/47
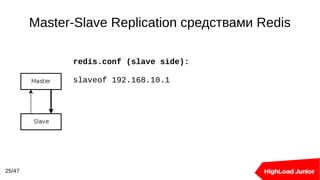
pgbouncer.ini:
[databases]
main = host=db-main pool_size=5 connect_query=
'select prepare_statements_and_stuff()'
[pgbouncer]
pool_mode = transaction
max_client_conn = 1024](https://image.slidesharecdn.com/hlj2016-160607084049/85/Avito-39-320.jpg)