Downloaded 20 times





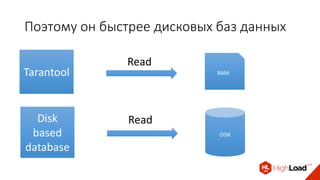

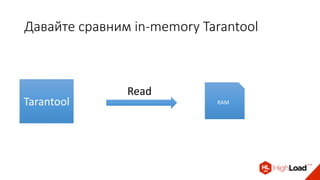
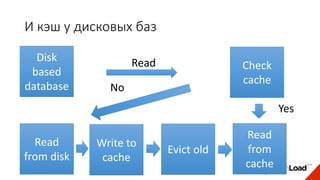



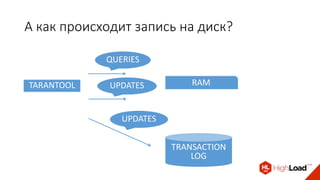

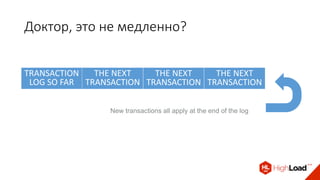



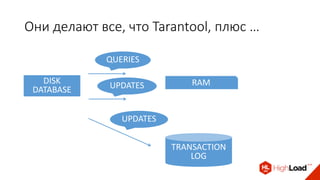

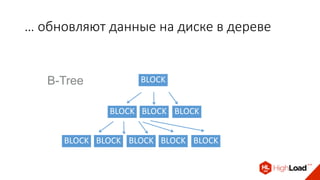

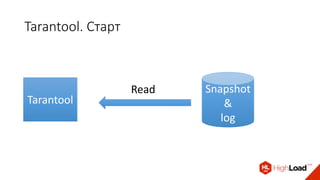
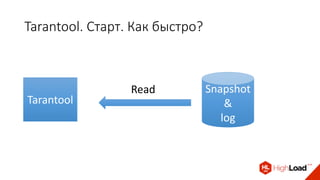
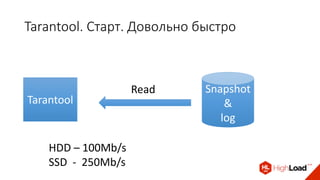







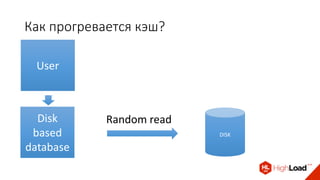
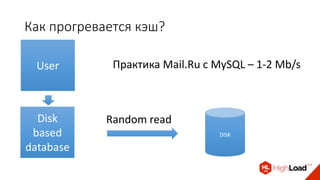



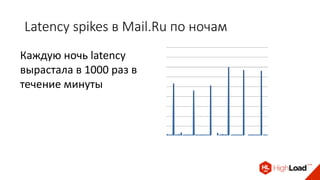
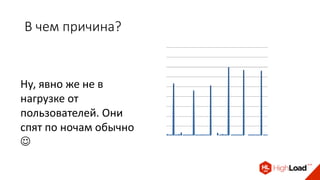


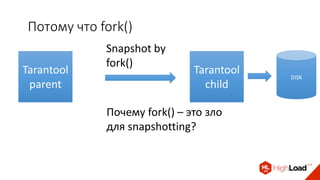
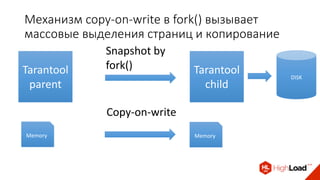
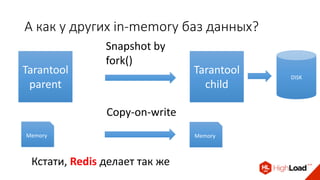
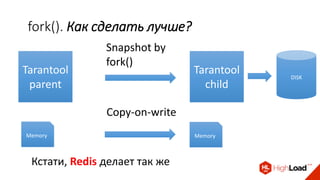
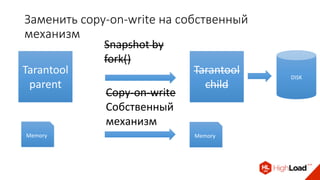

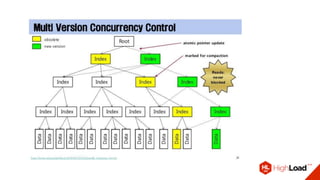









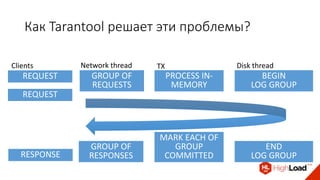





Доклад Дениса Аникина, технического директора mail.ru, описывает оптимальность Tarantool по сравнению с другими СУБД благодаря хранению данных в памяти и минимизации операций записи на диск. Он выделяет использование логов транзакций и асинхронных протоколов как ключевые аспекты повышения производительности, а также обсуждает механизмы управления латентностью. Tarantool способен быстрее обрабатывать запросы и значительно снижает затраты на системные вызовы, что делает его эффективным инструментом для работы с данными.



































































