Downloaded 15 times






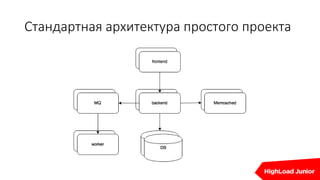





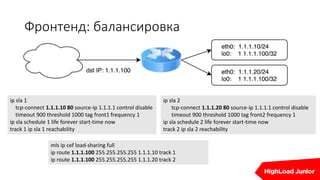

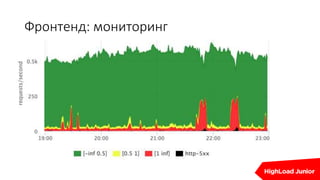









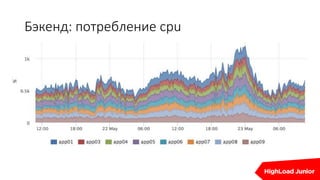
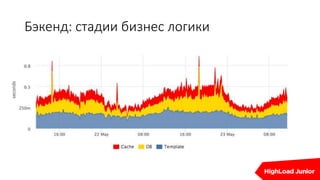









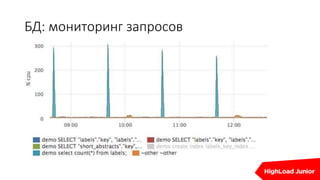






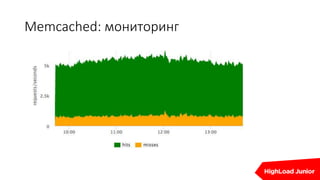






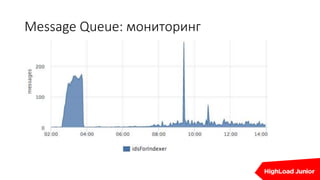
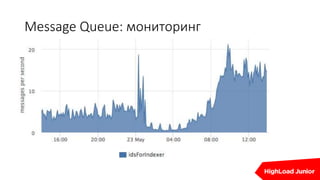







Документ описывает стратегии отказоустойчивости и мониторинга системы на примере сайта, который приносит доход. Рассматриваются аспекты работы дата-центров, серверов, фронтенда, бэкенда, баз данных и кэширования, также акцентируется внимание на потенциальных проблемах и методах их решения. В конце представлен план действий на случай отказа и рекомендации по оптимизации.























































































