Downloaded 11 times


























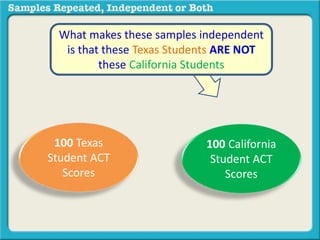









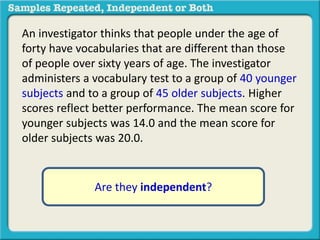


















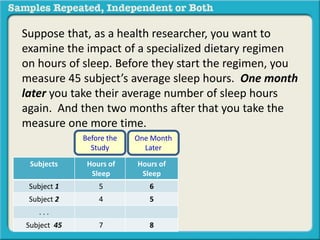

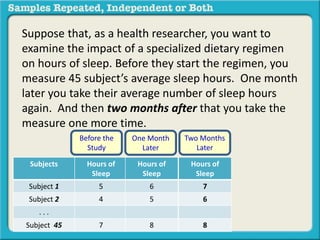
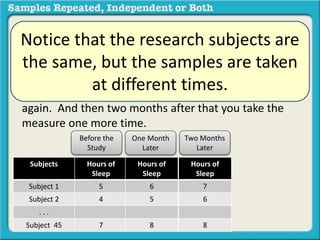

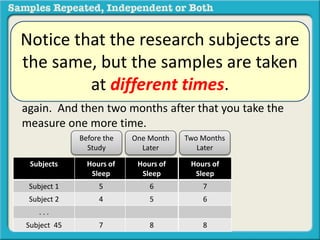
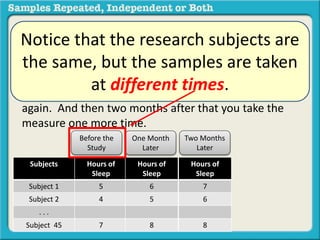
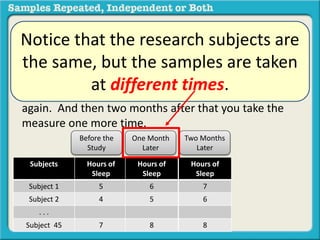




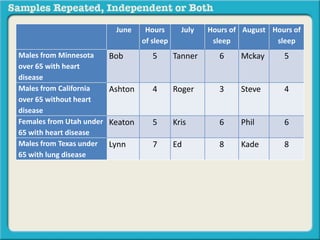
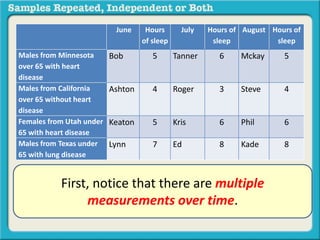
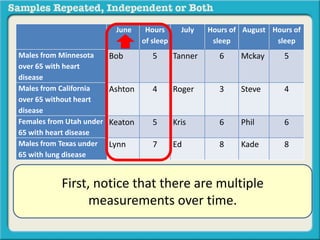
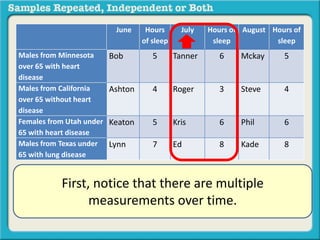
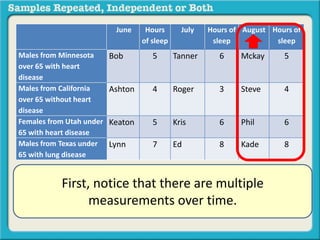
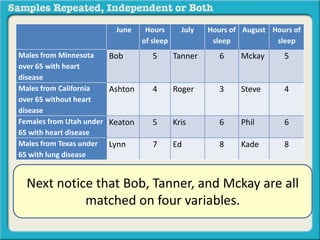
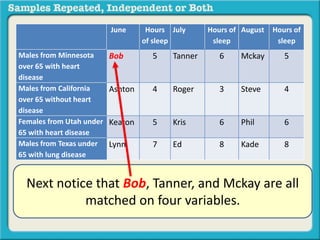
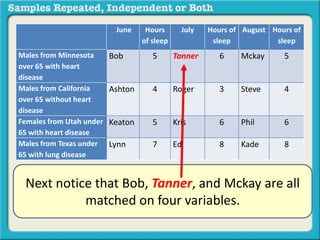
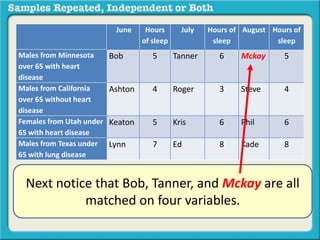
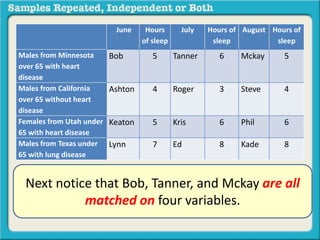
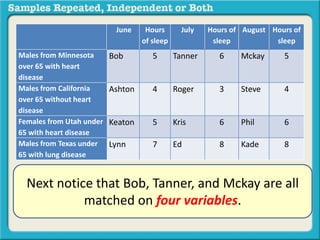




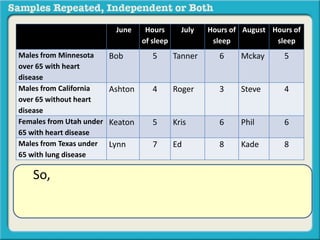
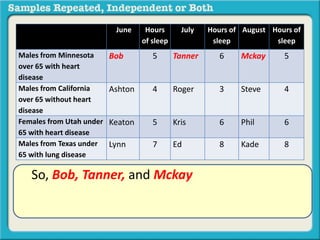
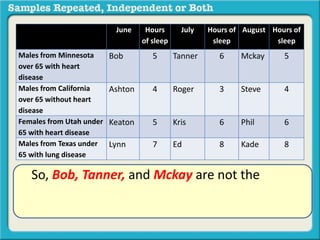
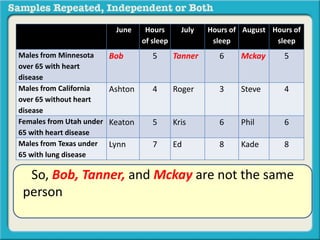
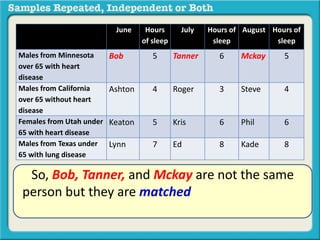
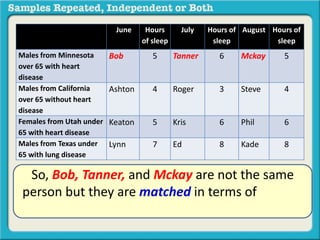
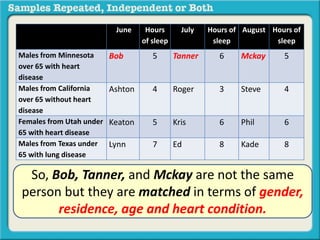
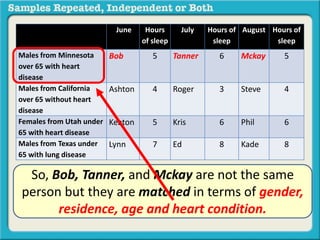
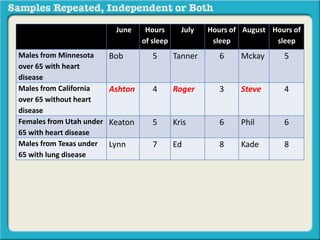
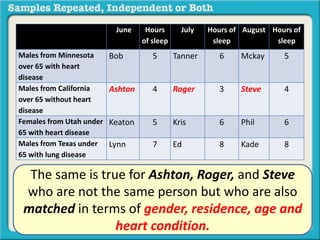
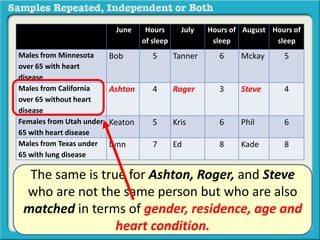
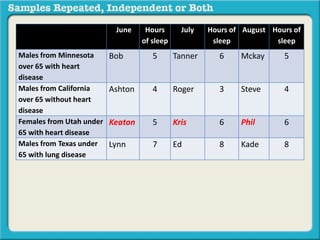
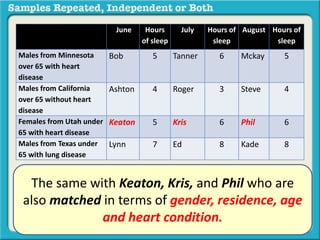

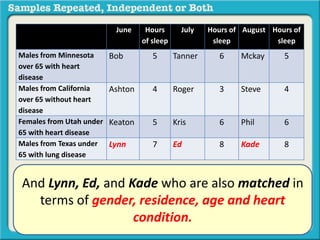
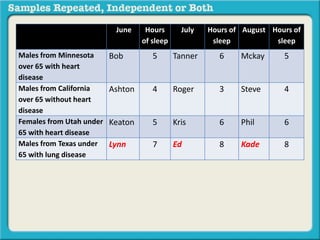
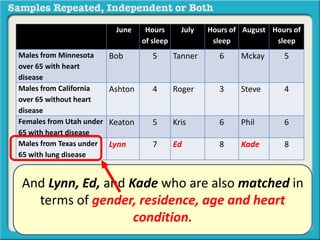































The document discusses independent and repeated samples. An independent sample involves subjects or observations from one sample that have no relationship with subjects or observations from another sample. A repeated sample involves measuring the same subjects or matched subjects more than once. An example is given of a study measuring sleep hours in the same subjects before and after starting a dietary regimen to examine the impact of the regimen over time. This uses a repeated sample as the same subjects are measured on multiple occasions.























































































