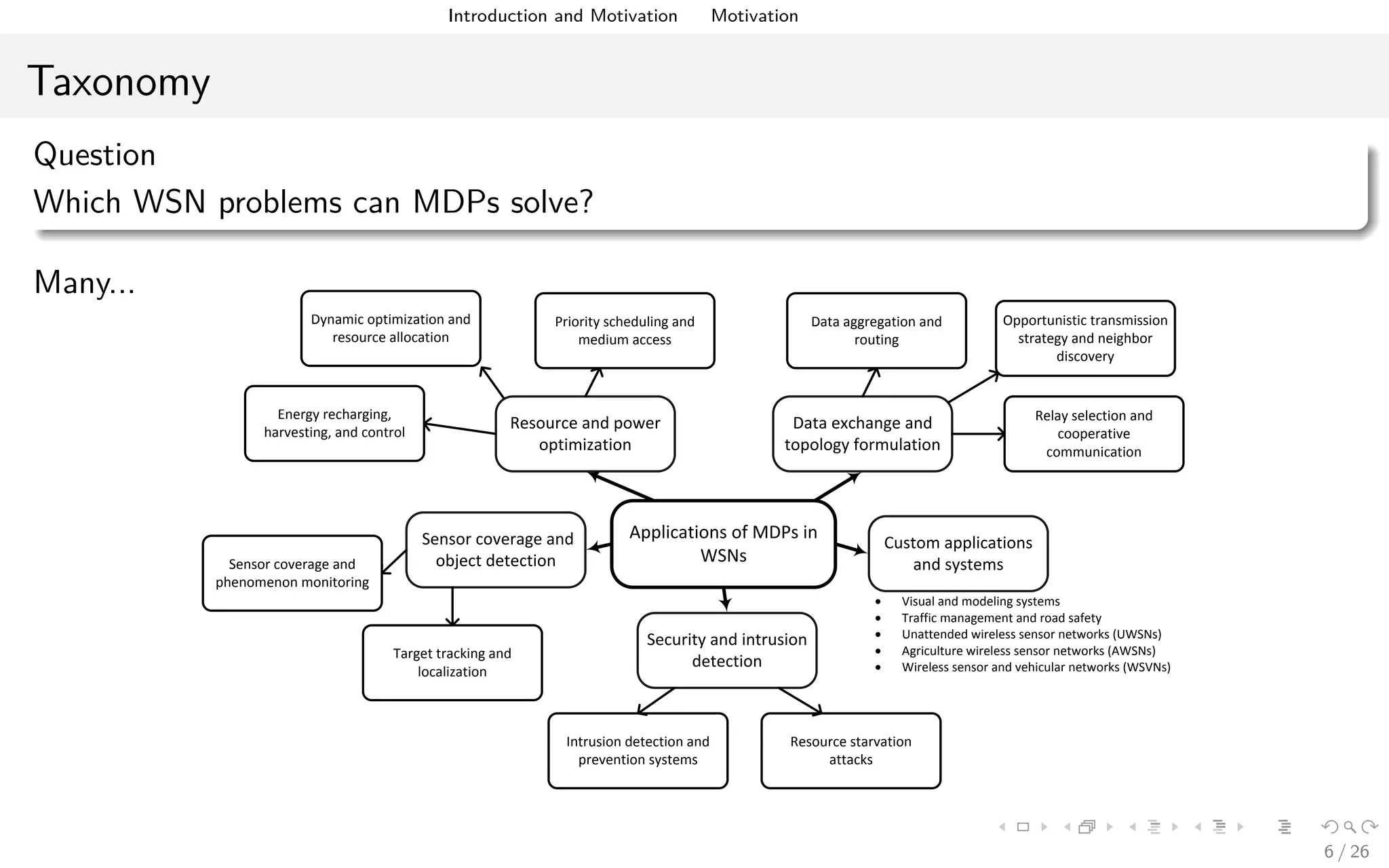
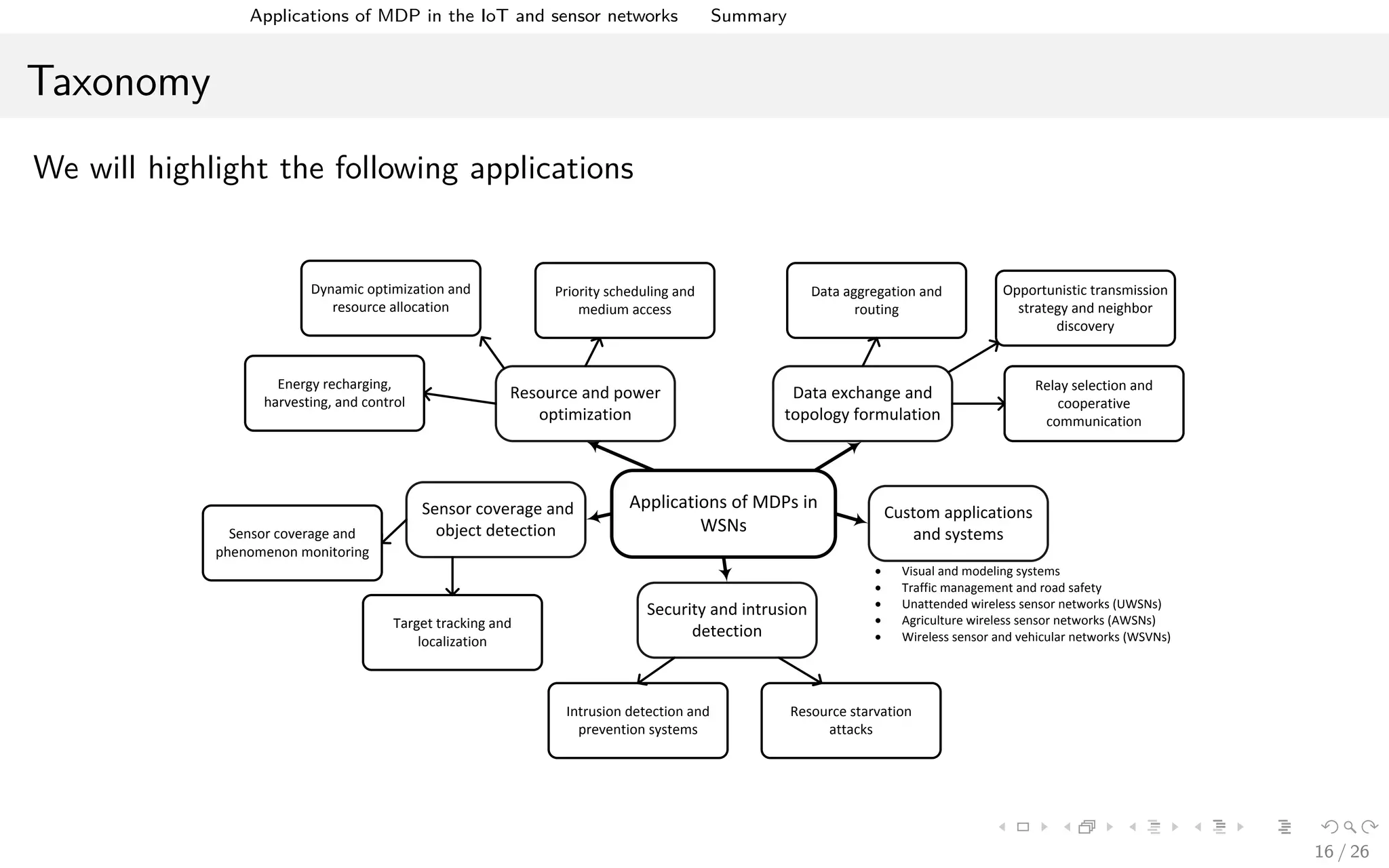
The document discusses the application of Markov Decision Processes (MDPs) in the Internet of Things (IoT) and wireless sensor networks (WSNs), highlighting their role in resource optimization, network adaptation, and security enhancements. It outlines the benefits, various applications, and specific use cases of MDPs, such as energy management, data routing, and intrusion detection. Additionally, it addresses challenges in implementing MDPs and notes the need for further research in areas such as time synchronization and handling large state spaces.








![Markov Decision Processes (MDPs): Overview The Markov Decision Process Framework
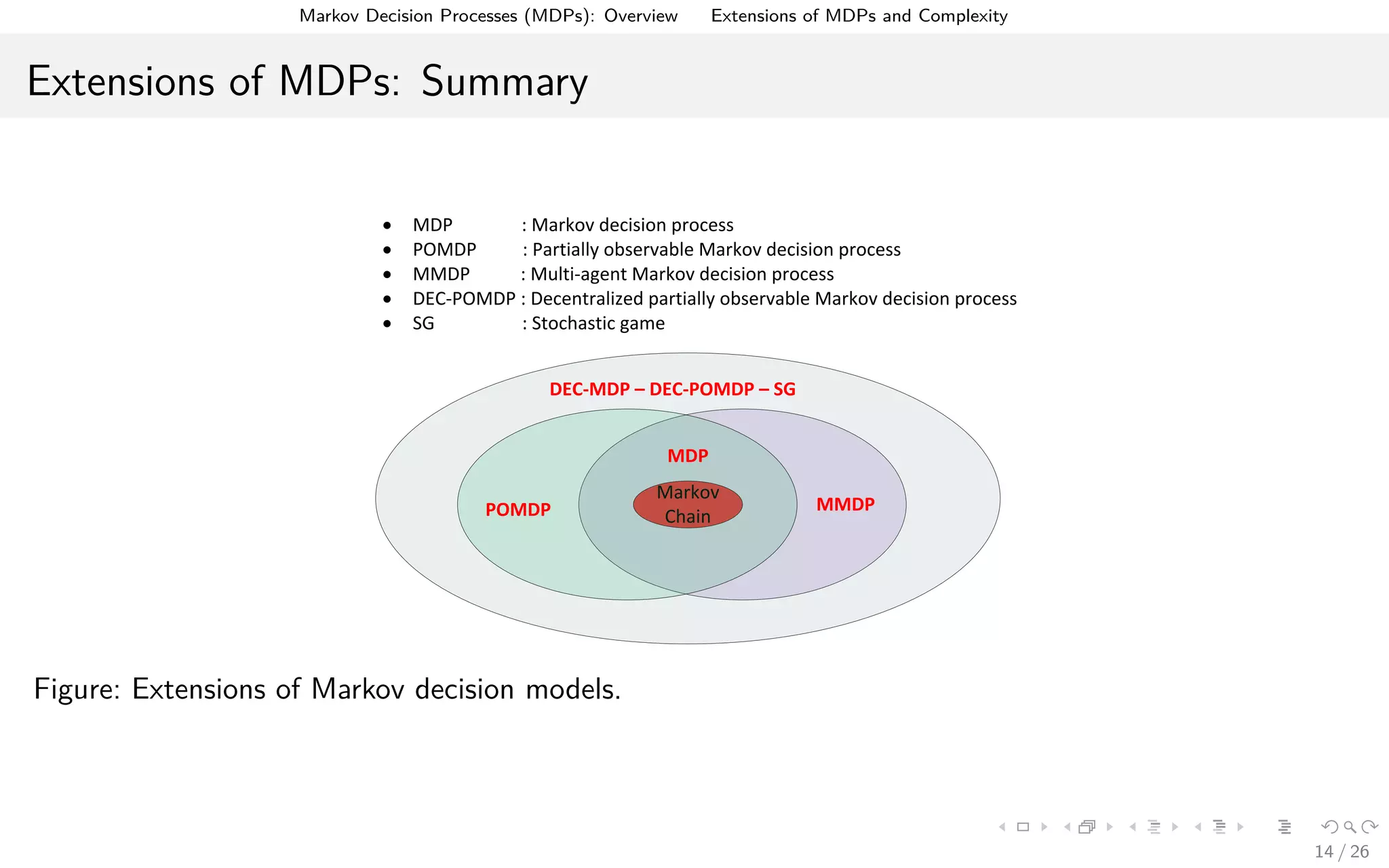
MDP Types (Time Horizon)
For the finite time horizon MDP, an optimal policy π∗ to maximize the expected total
reward is defined as follows:
max Vπ(s) = Eπ,s
T
t=1
R st|st, π(at) (1)
where st and at are the state and action at time t, respectively.
For the infinite time horizon MDP, the objective can be to maximize the expected
discounted total reward or to maximize the average reward. The former is defined as
follows:
max Vπ(s) = Eπ,s
T
t=1
γt
R st|st, π(at) , (2)
while the latter is expressed as follows:
max Vπ(s) = lim inf
T→∞
1
T
Eπ,s
T
t=1
R st|st, π(at) . (3)
Here, γ is the discounting factor and E[·] is the expectation function.
10 / 26](https://image.slidesharecdn.com/mdpwsnssummary-160526093543/75/Applications-of-Markov-Decision-Processes-MDPs-in-the-Internet-of-Things-IoT-and-Sensor-Networks-10-2048.jpg)























![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)

























































