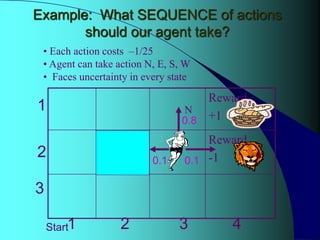
This presentation discusses Markov decision processes (MDPs) for solving sequential decision problems under uncertainty. An MDP is defined by a tuple containing states, actions, transition probabilities, and rewards. The objective is to find an optimal policy that maximizes expected long-term rewards by choosing the best sequence of actions. Value iteration is introduced as an algorithm for computing optimal policies by iteratively updating the value of each state. The presentation also discusses MDP terminology, stationary policies, influence diagrams, and methods for solving large MDP problems incrementally using decision trees.
















![Value Iteration: Key Idea
• Iterate: update utility of state “I” using old utility of
neighbor states “J”; given actions “A”
– U t+1 (I) = max [R(I,A) + S P(J|I,A)* U t (J)]
A J
– P(J|I,A): Probability of J if A is taken in state I
– max F(A) returns highest F(A)
– Immediate reward & longer term reward taken into
account](https://image.slidesharecdn.com/sohail-221005032020-479569e7/85/RL-intro-18-320.jpg)
![Value Iteration: Algorithm
• Initialize: U0 (I) = 0
• Iterate:
U t+1 (I) = max [ R(I,A) + S P(J|I,A)* U t (J) ]
A J
– Until close-enough (U t+1, Ut)
At the end of iteration, calculate optimal policy:
Policy(I) = argmax [R(I,A) + S P(J|I,A)* U t+1 (J) ]
A J](https://image.slidesharecdn.com/sohail-221005032020-479569e7/85/RL-intro-19-320.jpg)



























































