Download as PDF, PPTX
















![Code snippet
targetDistroMap.foreach {
case (samplingExpr, freq @ TargetPercent(percent)) =>
val relevantRegions: Seq[Region] =
existingDistroRegionMap.keys.filter(_.contains(samplingExpr)).toSeq
val lpExpression = relevantRegions.map(regionVariables).foldLeft[Expression](Zero)(_ + _)
val leftErrorMargin = MPFloatVar(samplingExpr.toString + "_leftErrorMargin", 0,
existingDistro.totalCount)
val rightErrorMargin = MPFloatVar(samplingExpr.toString + "_rightErrorMargin", 0,
existingDistro.totalCount)
val toleranceMargin = freq.toleranceMargin.getOrElse(targetToleranceMargin)
add(leftErrorMargin <:= overallSizeVariable * Const(0.01 * percent * toleranceMargin/100.0))
add(rightErrorMargin <:= overallSizeVariable * Const(0.01 * percent * toleranceMargin/100.0))
add(lpExpression := overallSizeVariable * Const(0.01 * percent) - leftErrorMargin +
rightErrorMargin)
leftErrorMarginsSum = leftErrorMarginsSum ++ Seq(leftErrorMargin)
rightErrorMarginsSum = rightErrorMarginsSum ++ Seq(rightErrorMargin)
}](https://image.slidesharecdn.com/2shivachaitanya-180613191521/75/Apache-Spark-Based-Stratification-Library-for-Machine-Learning-Use-Cases-at-Netflix-with-Shiva-Chaitanya-22-2048.jpg)


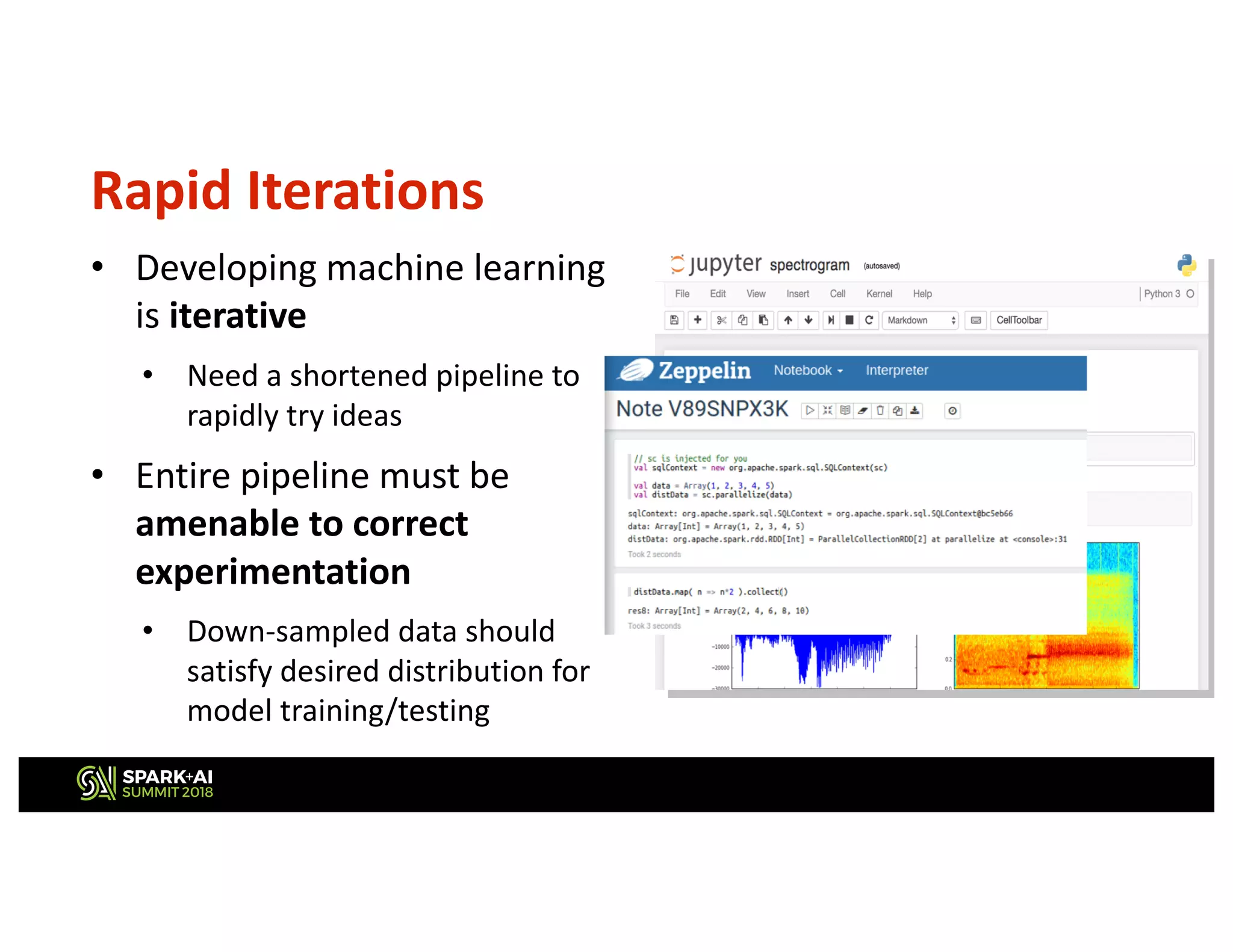
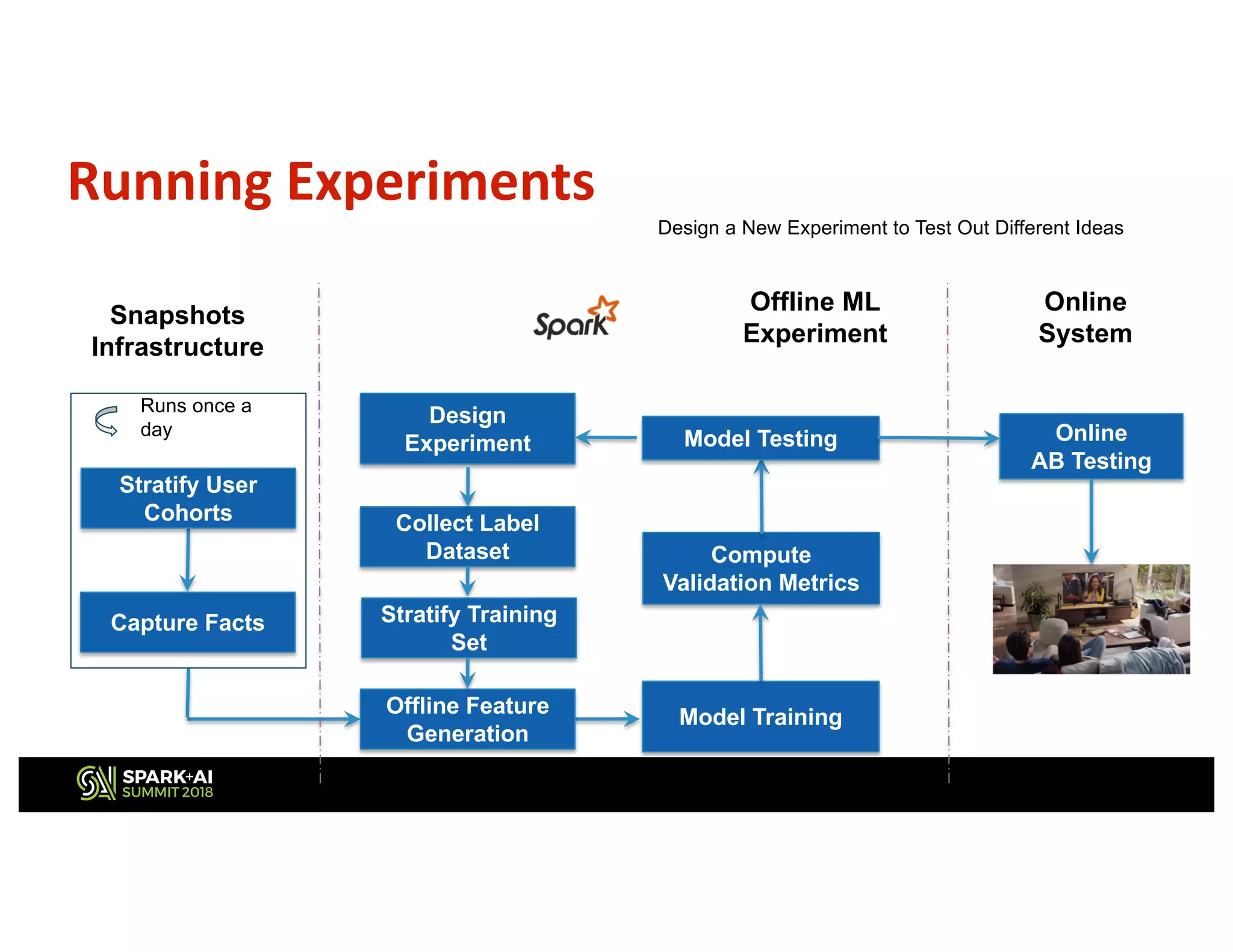
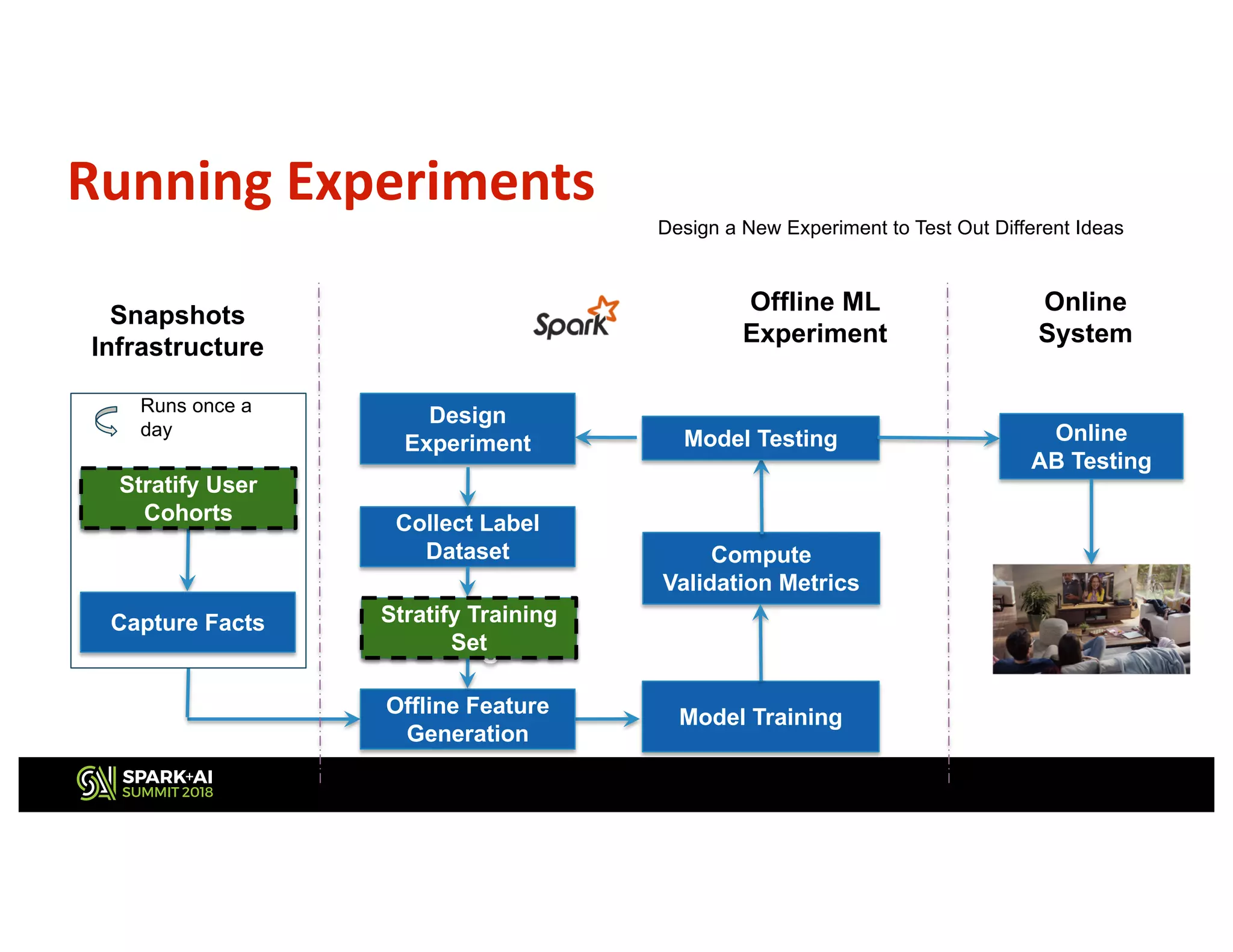
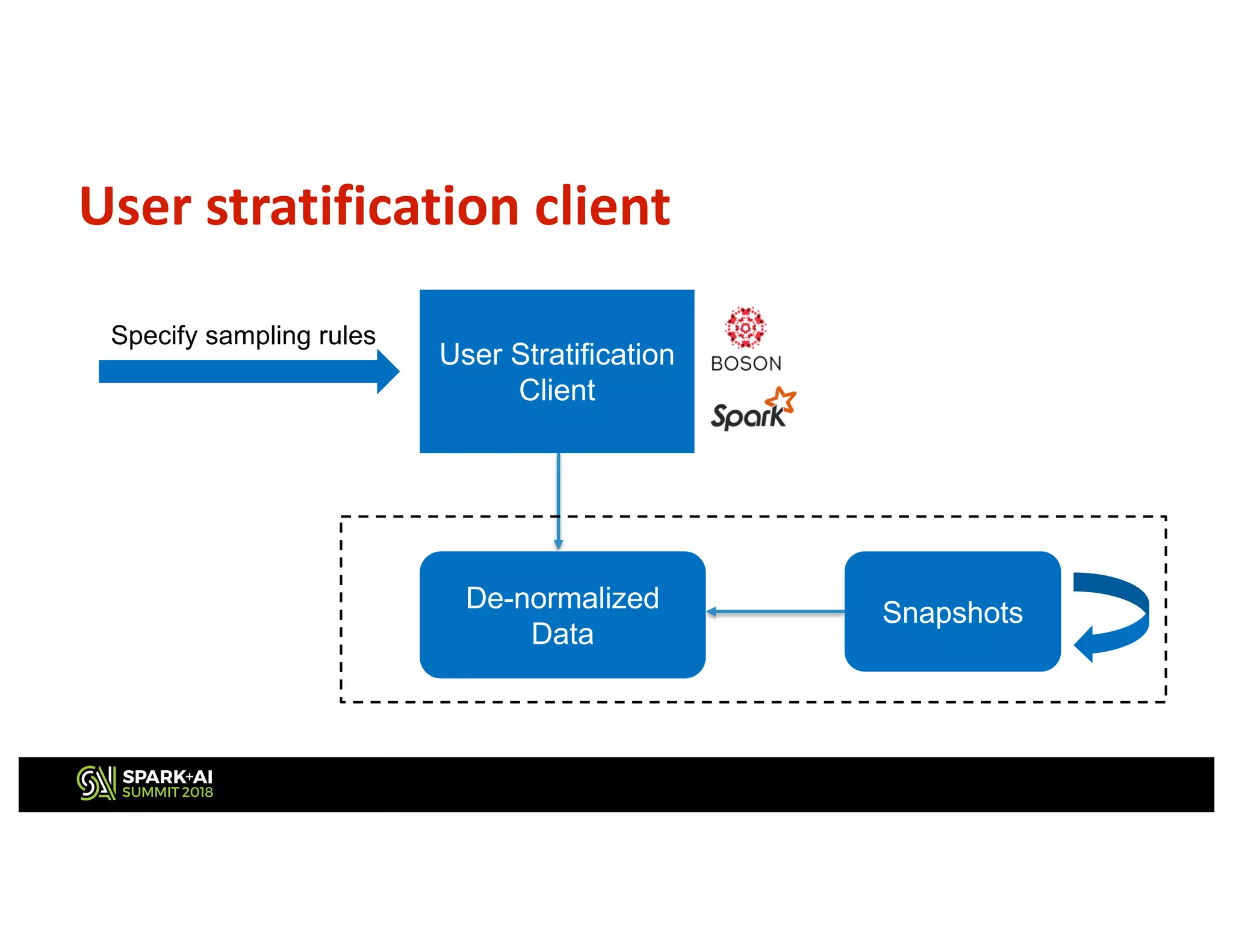
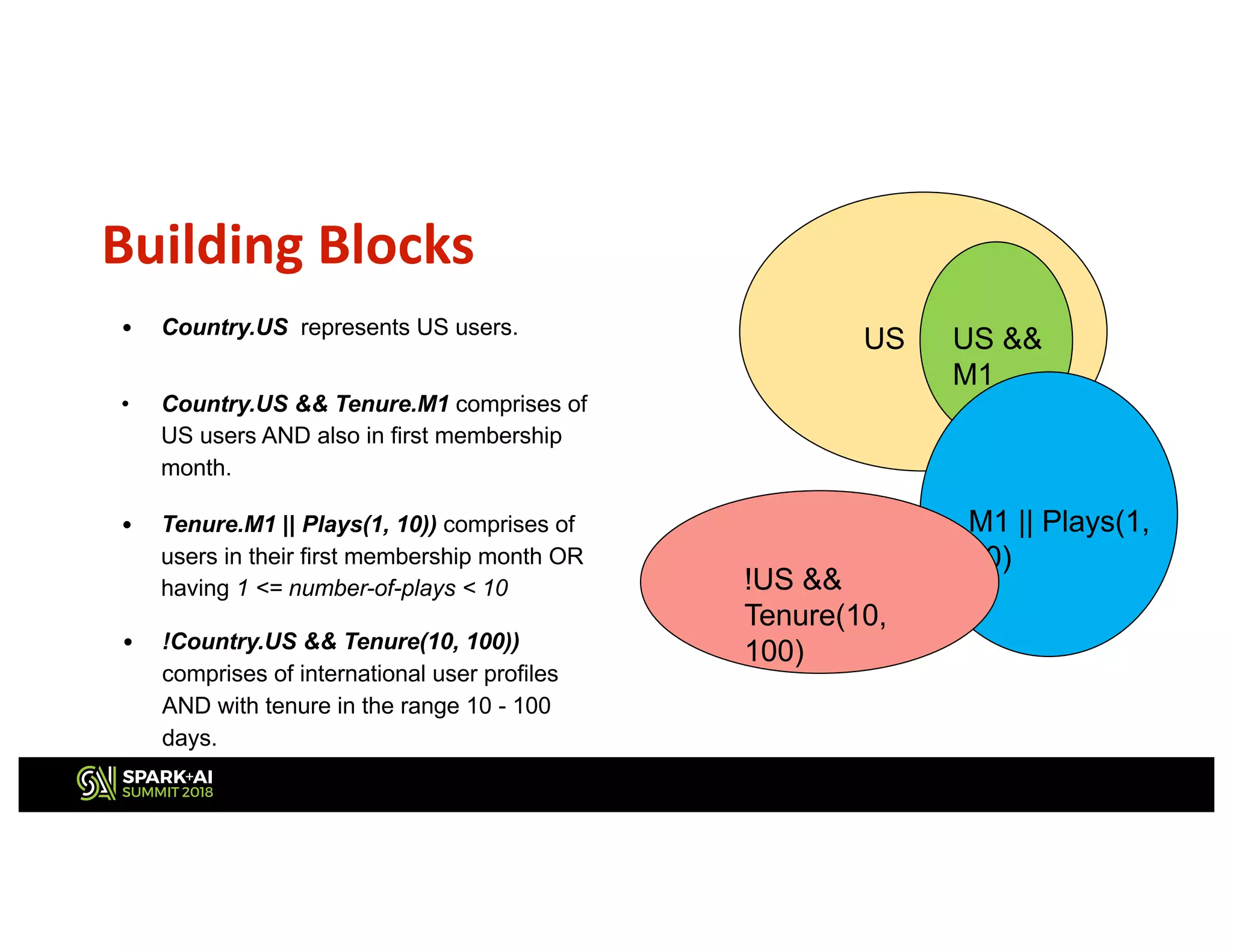
This document describes Netflix's use of data stratification for machine learning experimentation and model training. It discusses how Netflix uses the Boson library and its stratification API to: 1) Downsample datasets while meeting a desired distribution of users based on attributes like country, tenure, number of plays, etc. 2) Allow ML researchers to rapidly iterate on ideas by experimenting on stratified subsets of data offline before testing models online. 3) Ensure models are trained on data that sufficiently represents important user demographics through constraints placed during stratified sampling. The API provides flexible and declarative rules for stratifying user cohorts that inform the library how to sample data rather than specifying implementation details.