Download as PDF, PPTX









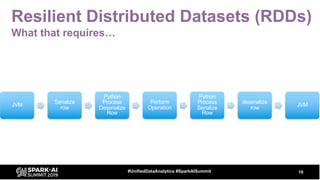
![Resilient Distributed Datasets (RDDs)
rdd = sc.parallelize(range(1000), 5)
rdd.map(lambda x: (x, x * 10)).take(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[(0, 0), (1, 10), (2, 20), (3, 30), (4, 40), (5, 50), (6, 60), (7, 70), (8,
80), (9, 90)]
9#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/billchambers-191031204530/85/Tactical-Data-Science-Tips-Python-and-Spark-Together-9-320.jpg)

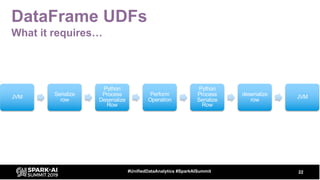
![DataFrames
12#UnifiedDataAnalytics #SparkAISummit
df = spark.range(1000)
print(df.limit(10).collect())
df = df.withColumn("col2", df.id * 10)
print(df.limit(10).collect())
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4), Row(id=5), Row(id=6),
Row(id=7), Row(id=8), Row(id=9)]
[Row(id=0, col2=0), Row(id=1, col2=10), Row(id=2, col2=20), Row(id=3,
col2=30), Row(id=4, col2=40), Row(id=5, col2=50), Row(id=6, col2=60),
Row(id=7, col2=70), Row(id=8, col2=80), Row(id=9, col2=90)]](https://image.slidesharecdn.com/billchambers-191031204530/85/Tactical-Data-Science-Tips-Python-and-Spark-Together-12-320.jpg)
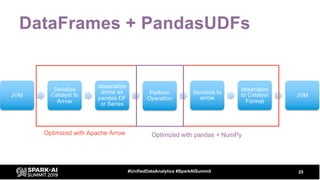
![DataFrames
13#UnifiedDataAnalytics #SparkAISummit
df = spark.range(1000)
print(df.limit(10).collect())
df = df.withColumn("col2", df.id * 10)
print(df.limit(10).collect())
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4), Row(id=5), Row(id=6),
Row(id=7), Row(id=8), Row(id=9)]
[Row(id=0, col2=0), Row(id=1, col2=10), Row(id=2, col2=20), Row(id=3,
col2=30), Row(id=4, col2=40), Row(id=5, col2=50), Row(id=6, col2=60),
Row(id=7, col2=70), Row(id=8, col2=80), Row(id=9, col2=90)]](https://image.slidesharecdn.com/billchambers-191031204530/85/Tactical-Data-Science-Tips-Python-and-Spark-Together-13-320.jpg)


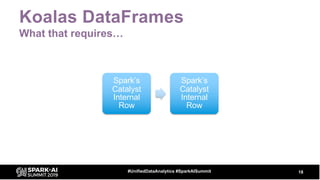
![Koalas DataFrames
16#UnifiedDataAnalytics #SparkAISummit
import databricks.koalas as ks
kdf = ks.DataFrame(spark.range(1000))
kdf['col2'] = kdf.id * 10 # note pandas syntax
kdf.head(10) # returns pandas dataframe](https://image.slidesharecdn.com/billchambers-191031204530/85/Tactical-Data-Science-Tips-Python-and-Spark-Together-16-320.jpg)










![3 Key Dimensions
How many input rows do you have? [n]
Large (10M) vs small (10K)
How many input features do you have? [k]
Large (1M) vs small (100)
How many models do you need to produce? [m]
Large (1K) vs small (1)
30#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/billchambers-191031204530/85/Tactical-Data-Science-Tips-Python-and-Spark-Together-30-320.jpg)








This document summarizes a talk given by Bill Chambers on processing data with Spark and Python. It discusses 5 ways to process data: RDDs, DataFrames, Koalas, UDFs, and pandasUDFs. It then covers two data science use cases - growth forecasting and churn prediction - and how they were implemented using these different processing methods based on characteristics like the number of input rows, features, and required models. The talk emphasizes using DataFrames and pandasUDFs for optimal performance and flexibility. It also highlights tracking models with MLFlow for consistency in production.



















































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)



