Download as PDF, PPTX









![Spark + XGBoost on Ray
import ray
import raydp
ray.init(address='auto')
spark = raydp.init_spark('Spark + XGBoost',
num_executors=2,
executor_cores=4,
executor_memory='8G')
df = spark.read.csv(...)
...
train_df, test_df = random_split(df, [0.9, 0.1])
train_dataset = RayMLDataset.from_spark(train_df, ...)
test_dataset = RayMLDataset.from_spark(test_df, ...)
from xgboost_ray import RayDMatrix, train, RayParams
dtrain = RayDMatrix(train_dataset, label='fare_amount')
dtest = RayDMatrix(test_dataset, label='fare_amount’)
…
bst = train(
config,
dtrain,
evals=[(dtest, "eval")],
evals_result=evals_result,
ray_params=RayParams(…)
num_boost_round=10)
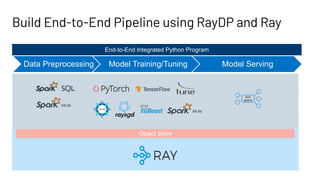
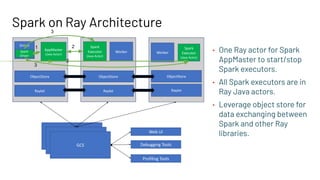
Data Preprocessing Model Training
End-to-End Integrated Python Program
RayD
P
RayD
P](https://image.slidesharecdn.com/176wangliu-210608234541/85/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-20-320.jpg)
![Spark + Horovod on Ray
import ray
import raydp
ray.init(address='auto')
spark = raydp.init_spark('Spark + Horovod',
num_executors=2,
executor_cores=4,
executor_memory=‘8G’)
df = spark.read.csv(...)
...
torch_ds= RayMLDataset.from_spark(df, …)
.to_torch(...)
#PyTorch Model
class My_Model(nn.Module):
…
#Horovod on Ray
def train_fn(dataset, num_features):
hvd.init()
rank = hvd.rank()
train_data = dataset.get_shard(rank)
...
from horovod.ray import RayExecutor
executor = RayExecutor(settings, num_hosts=1,
num_slots=1, cpus_per_slot=1)
executor.start()
executor.run(train_fn, args=[torch_ds, num_features])
Data Preprocessing Model Training
End-to-End Integrated Python Program
RayD
P
RayD
P](https://image.slidesharecdn.com/176wangliu-210608234541/85/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-21-320.jpg)
![Spark + Horovod + RayTune on Ray
import ray
import raydp
ray.init(address='auto')
spark = raydp.init_spark(‘Spark + Horovod',
num_executors=2,
executor_cores=4,
executor_memory=‘8G’)
df = spark.read.csv(...)
...
torch_ds= RayMLDataset.from_spark(df, …)
.to_torch(...)
#PyTorch Model
class My_Model(nn.Module):
…
#Horovod on Ray + Ray Tune
def train_fn(config: Dict):
...
trainable = DistributedTrainableCreator(
train_fn, num_slots=2, use_gpu=use_gpu)
analysis = tune.run(
trainable,
num_samples=2,
config={
"epochs": tune.grid_search([1, 2, 3]),
"lr": tune.grid_search([0.1, 0.2, 0.3]),
}
)
print(analysis.best_config)
Data Preprocessing Model Training/Tuning
End-to-End Integrated Python Program
RayD
P
RayD
P](https://image.slidesharecdn.com/176wangliu-210608234541/85/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-22-320.jpg)



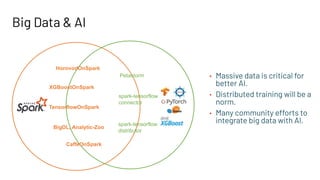
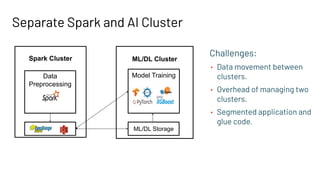
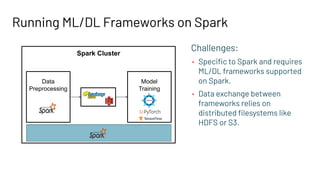
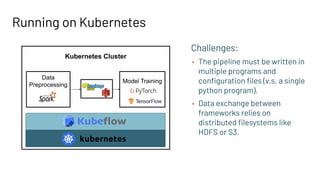
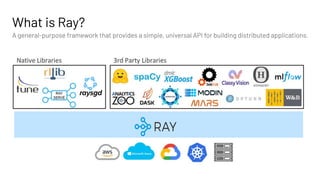
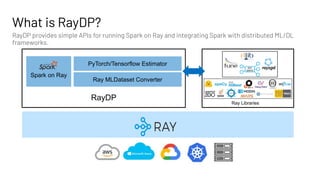
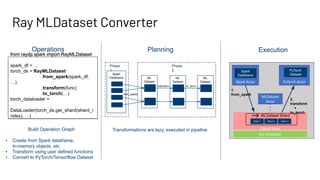
The document discusses building large-scale data analytics and AI pipelines using RayDP, a framework that integrates Spark with distributed machine learning frameworks. It highlights the benefits of RayDP, such as increased productivity, performance, and resource utilization through a seamless API for development across multiple platforms. The document also provides examples of using RayDP with various ML frameworks for end-to-end workflows in data preprocessing and model training.




































































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)