Download as PDF, PPTX





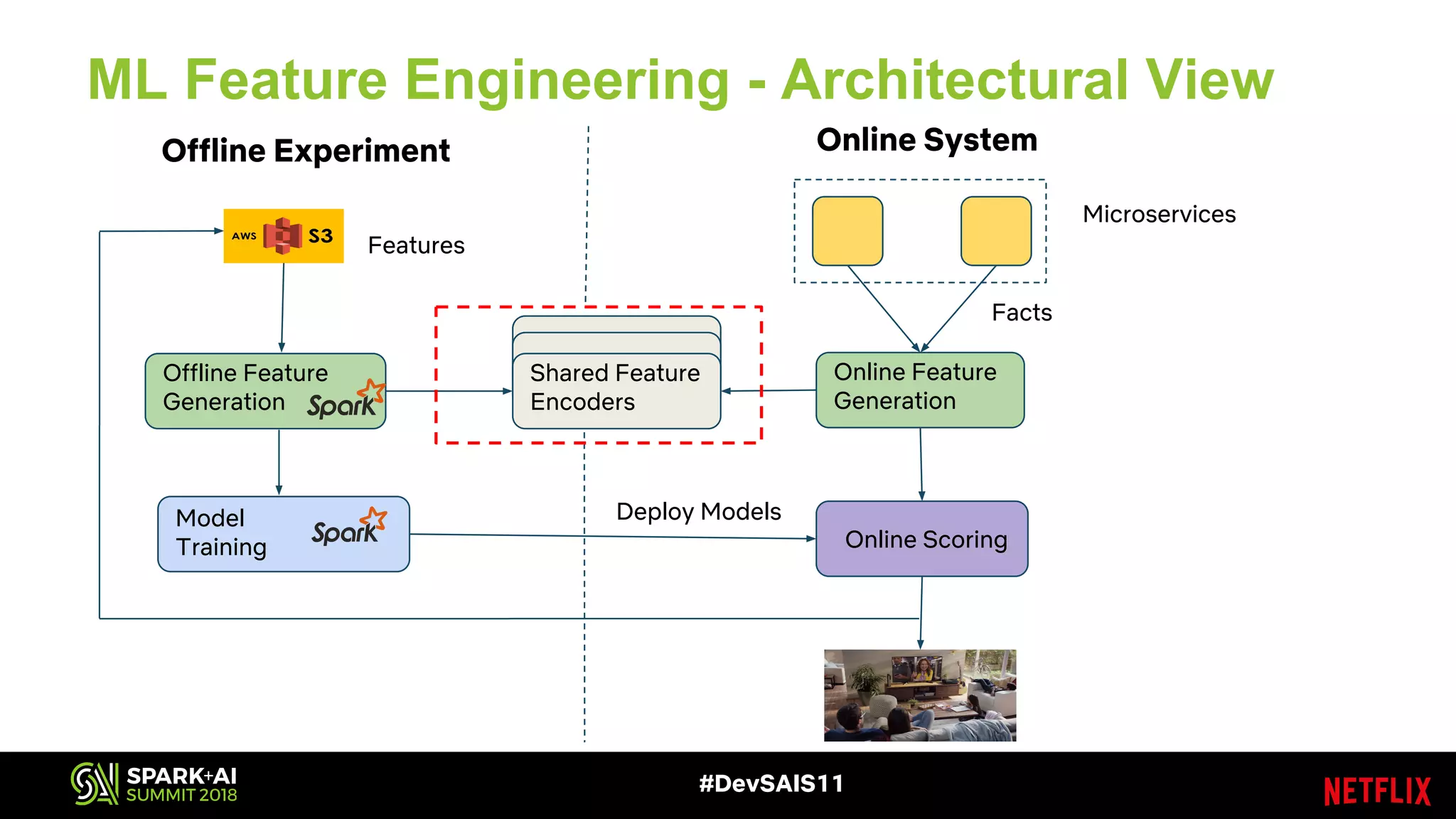


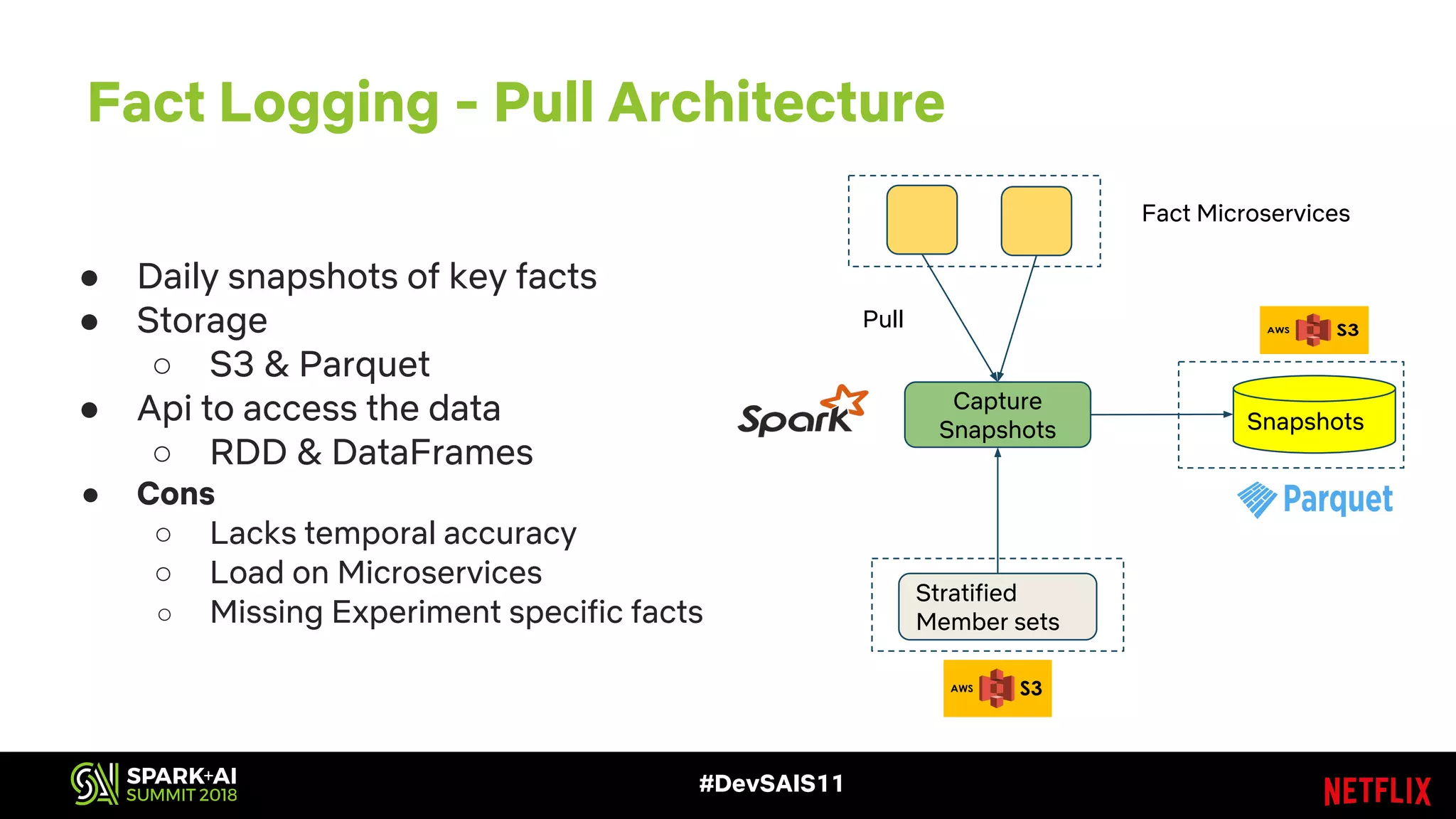

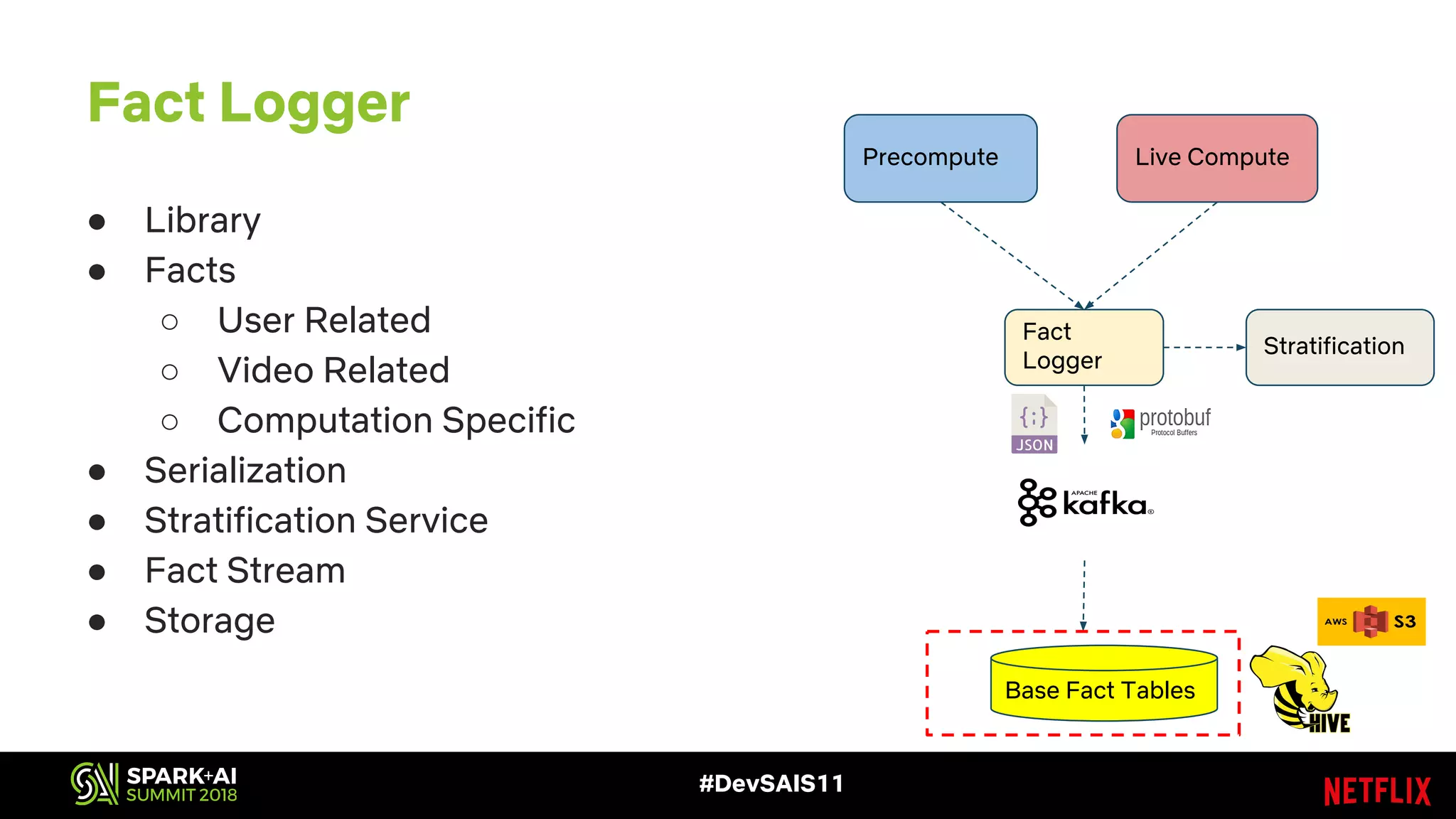

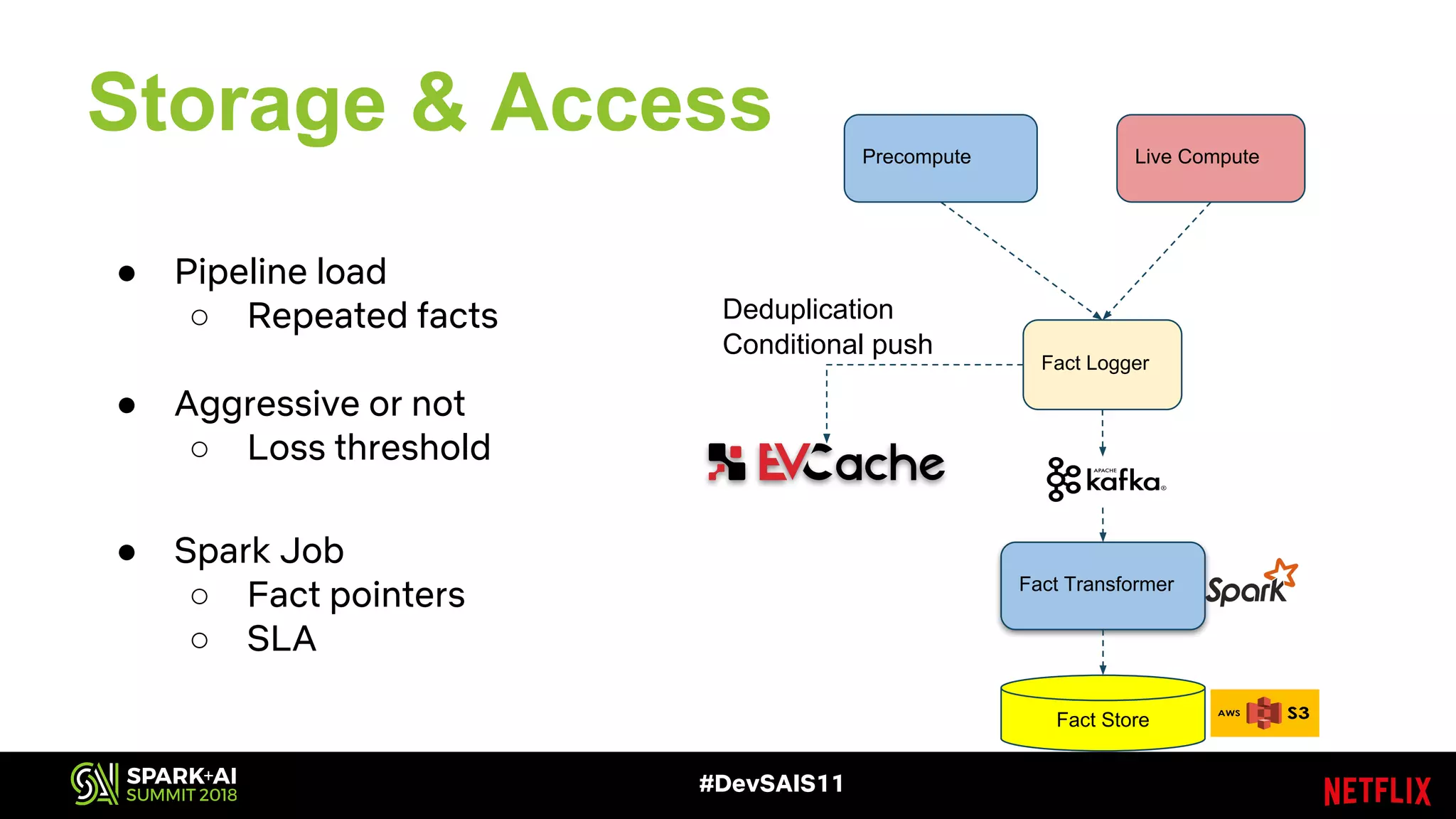

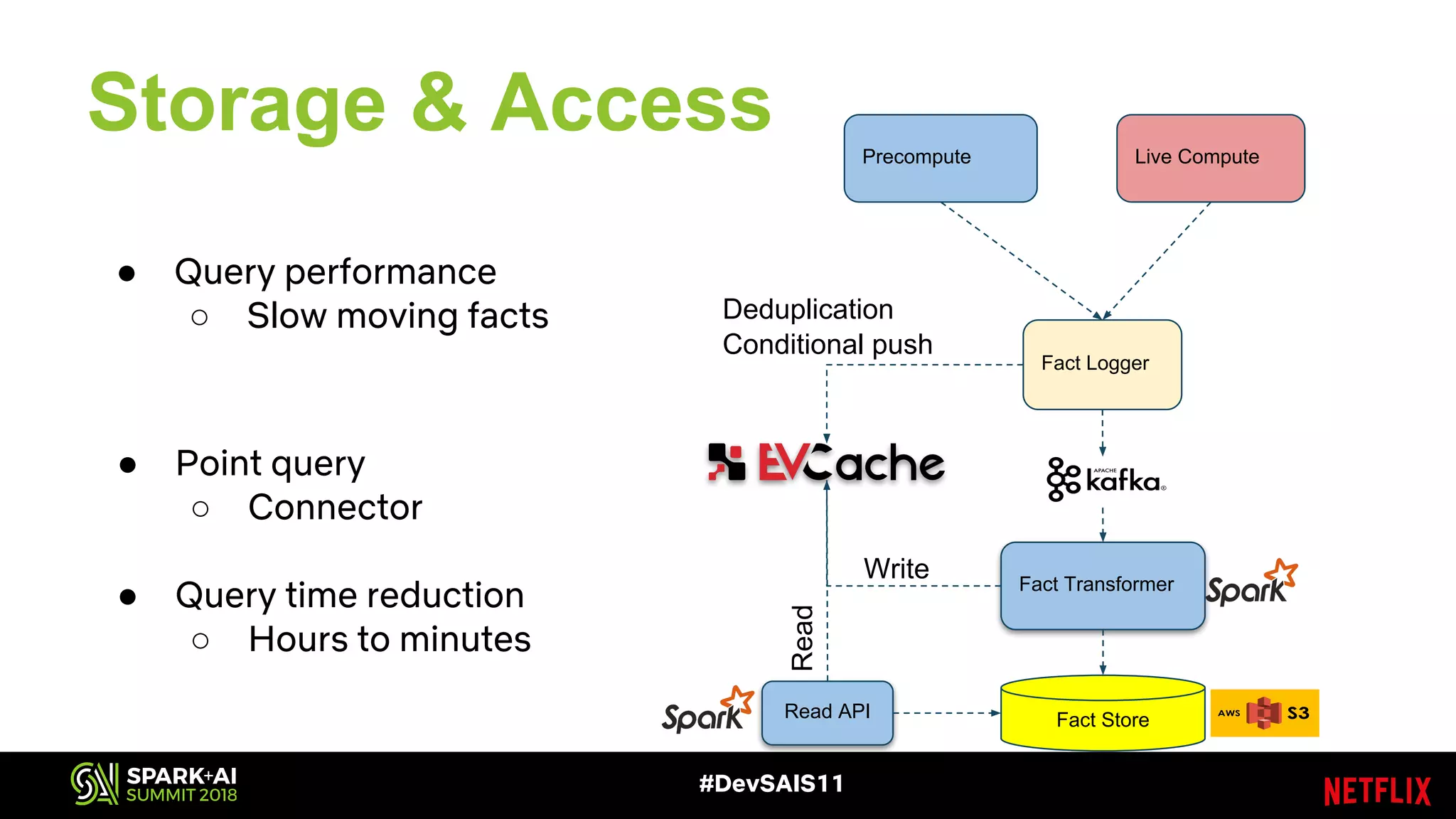




This document discusses recommendations and machine learning at Netflix. It provides an overview of: - How Netflix provides personalized recommendations on member homepages to help them find content to watch. - Netflix's experimentation cycle of designing experiments, collecting data, generating features, training models, and doing A/B testing. - How Netflix handles "facts" or input data for recommendations, including how facts change over time and how they are logged and stored at scale. - The challenges of logging and accessing facts at Netflix's scale, and how they are addressing issues like deduplication, performance, and supporting different access patterns.




















![[WSO2Con USA 2018] Deploying Applications in K8S and Docker](https://cdn.slidesharecdn.com/ss_thumbnails/deployingapplicationsink8sanddocker-wso2conusa2018-180723073457-thumbnail.jpg?width=640&height=640&fit=bounds)











































