Download as PDF, PPTX




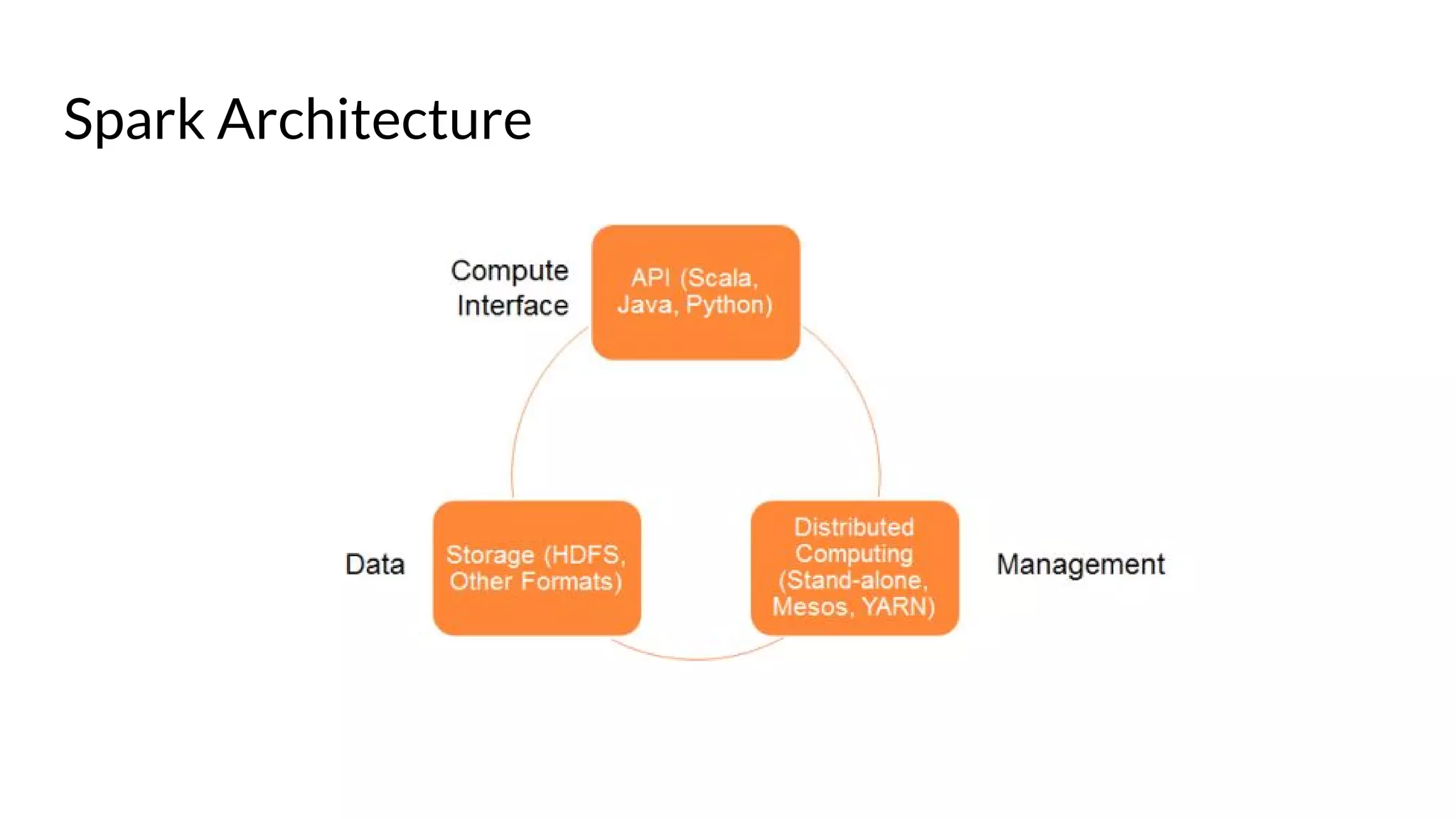
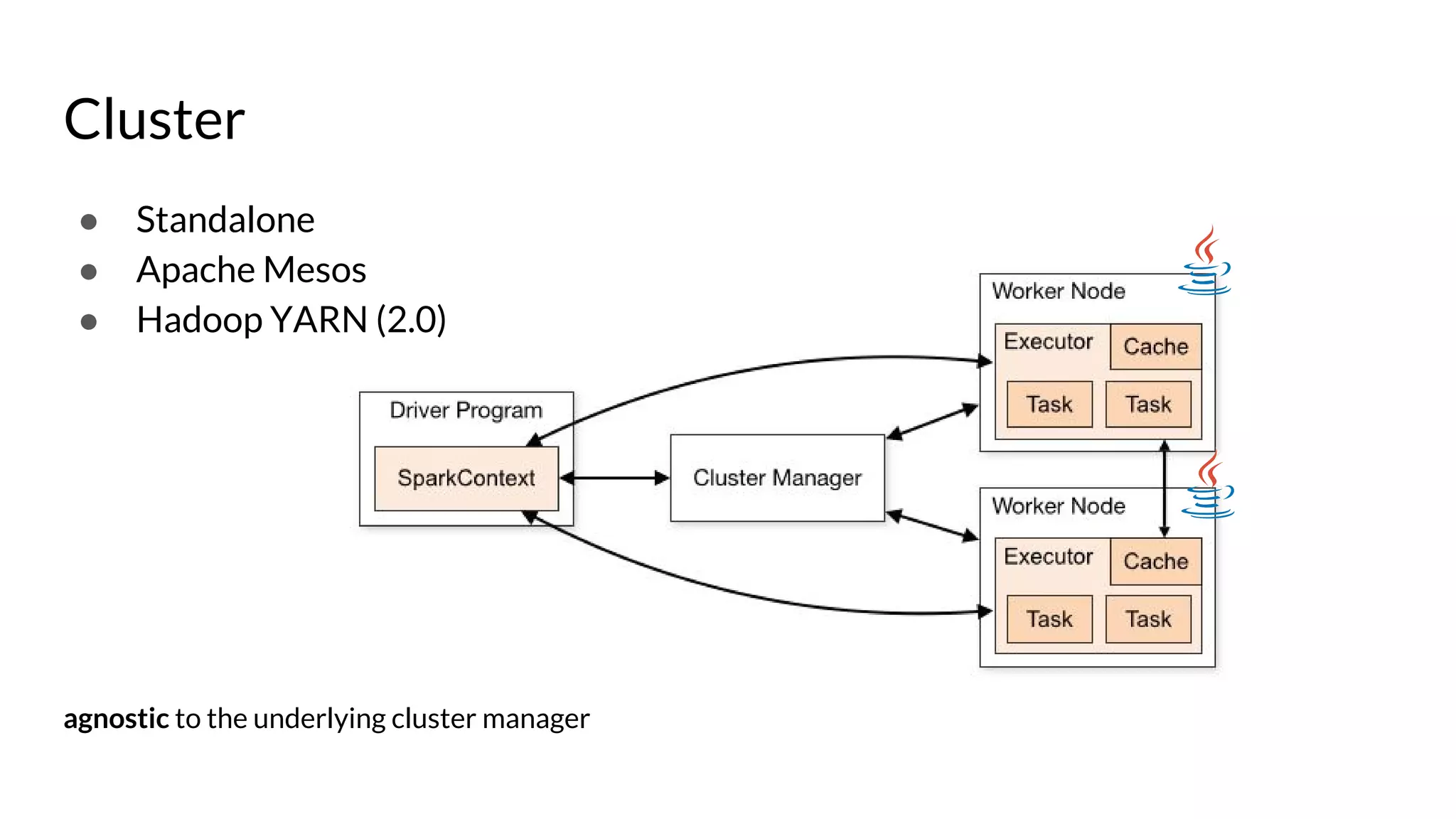

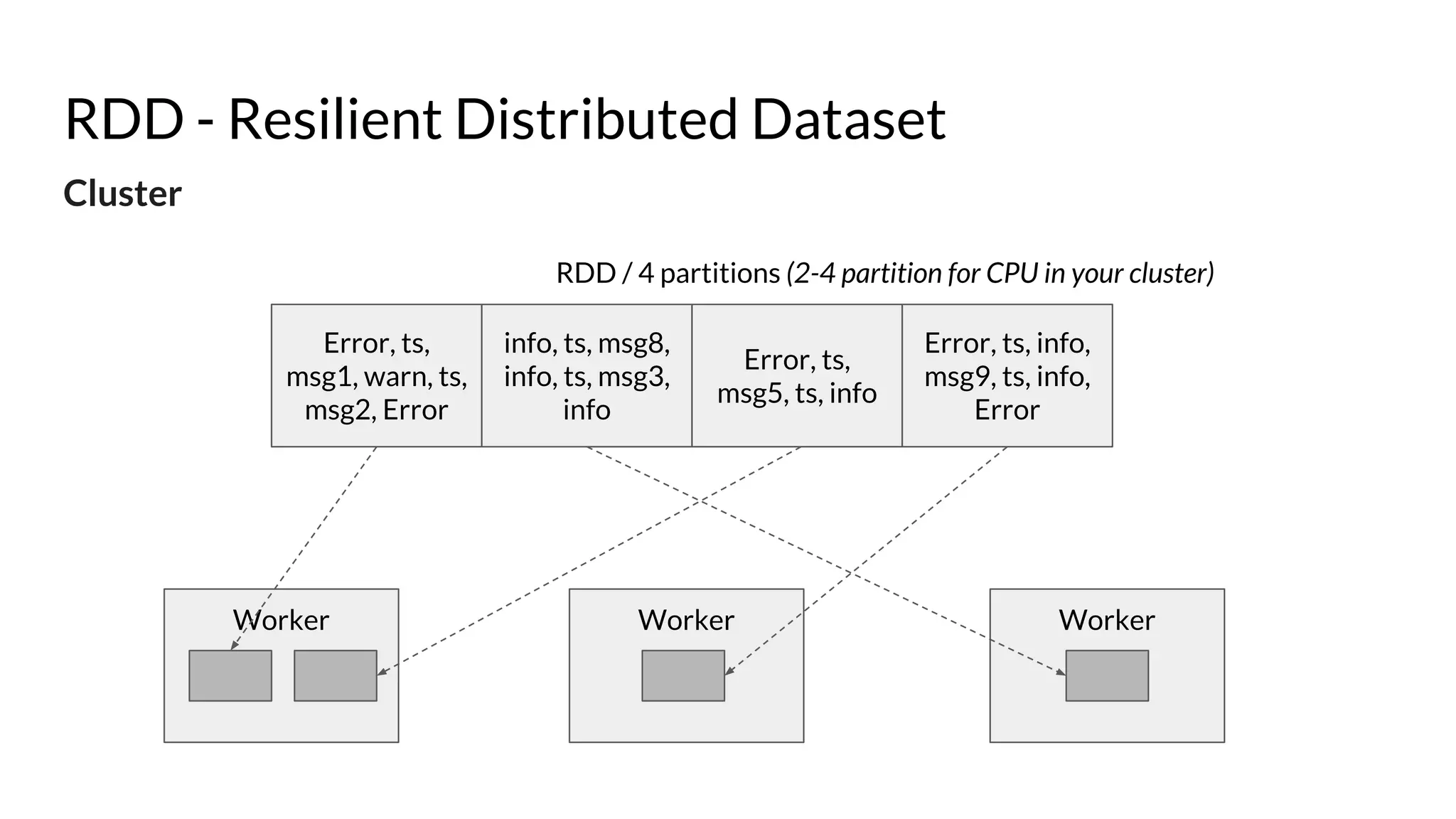
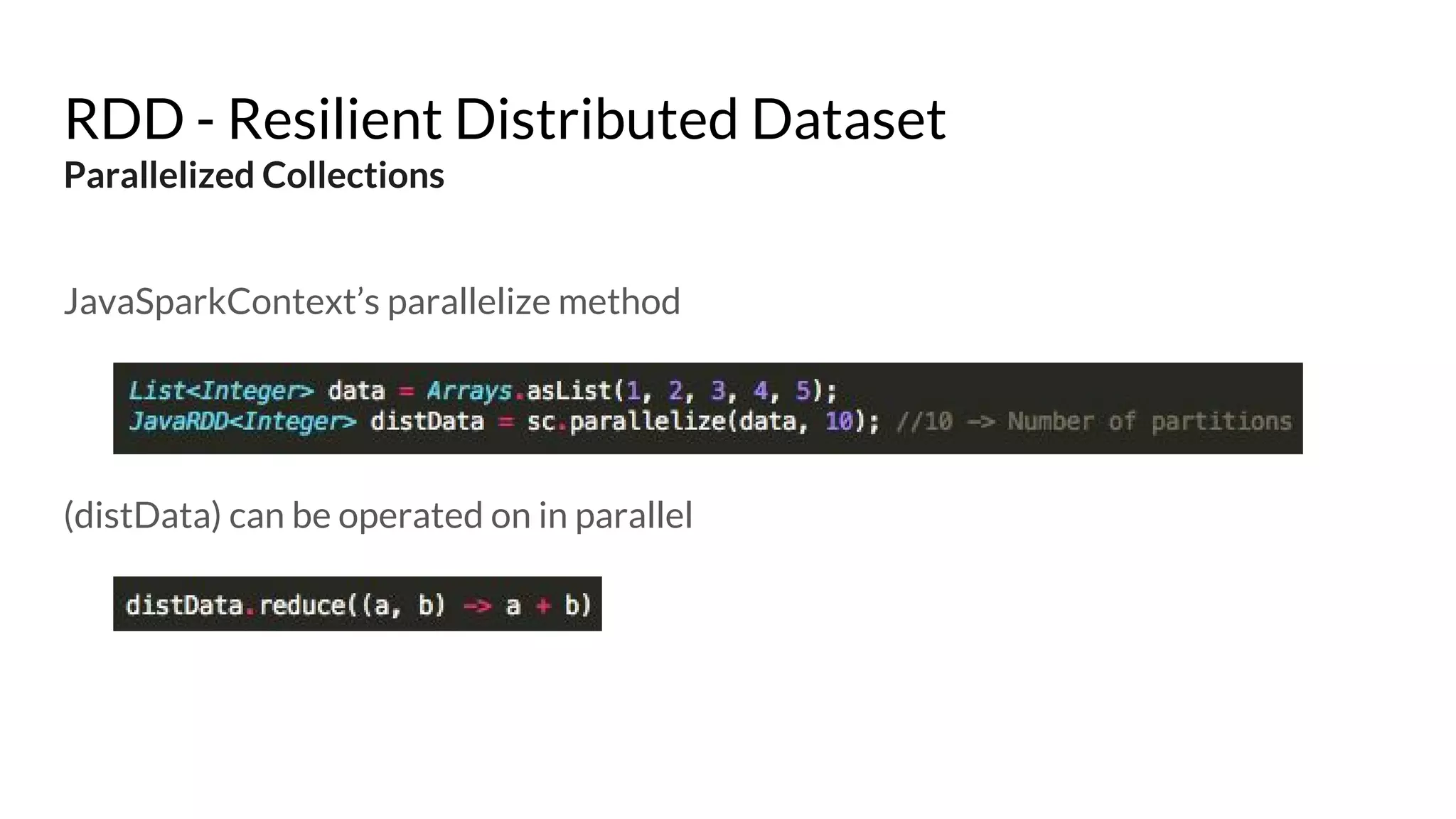

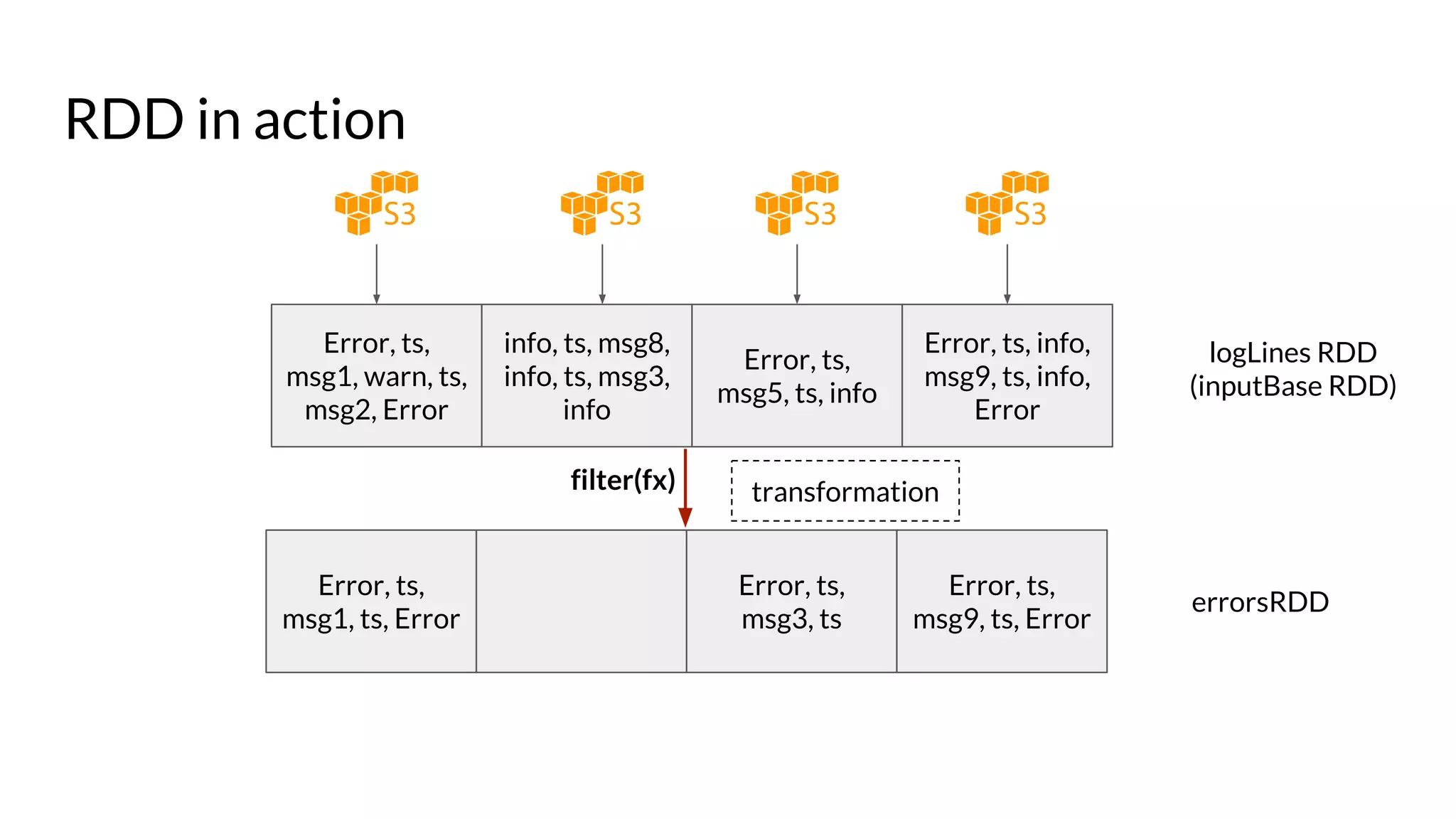
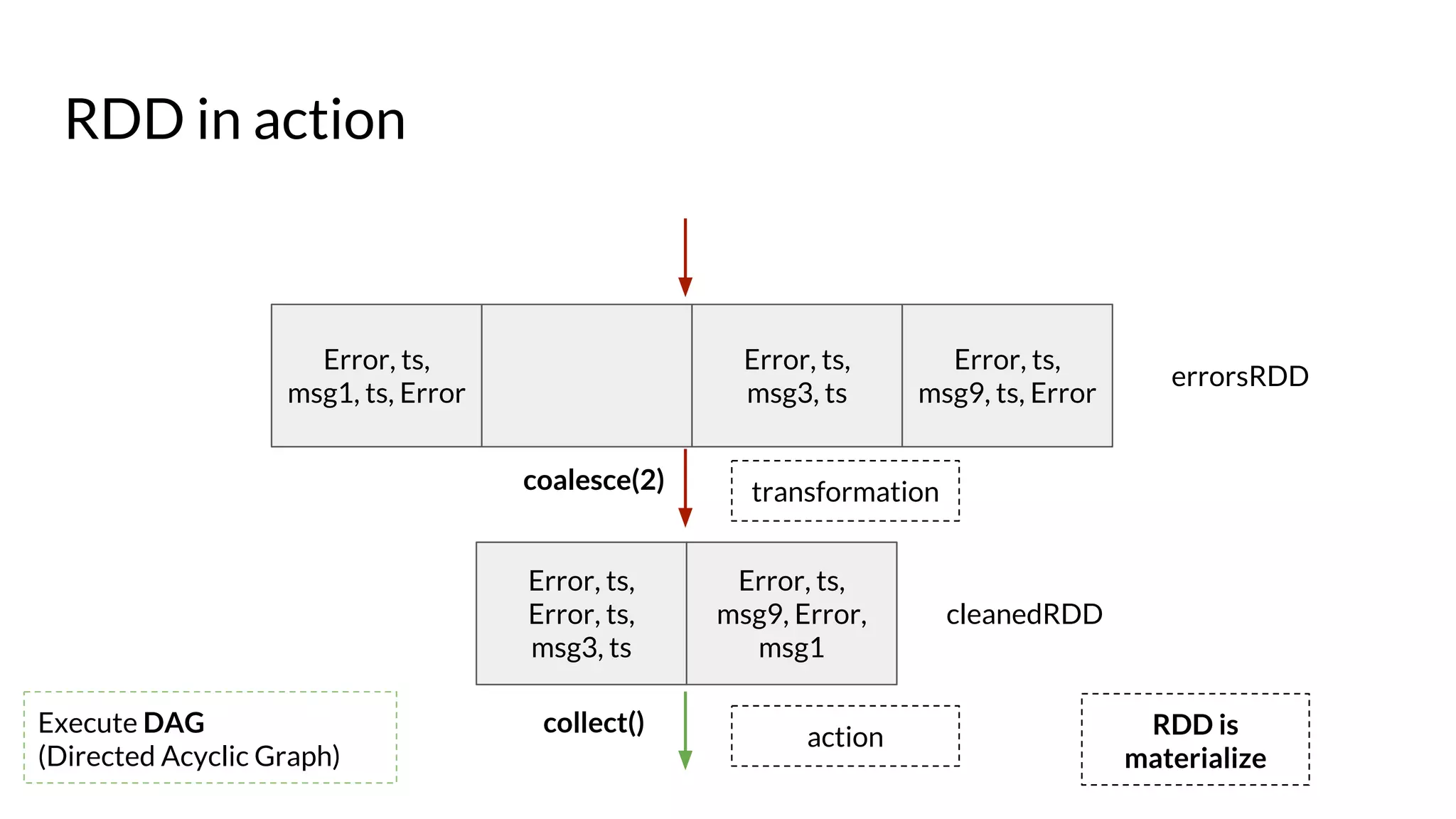
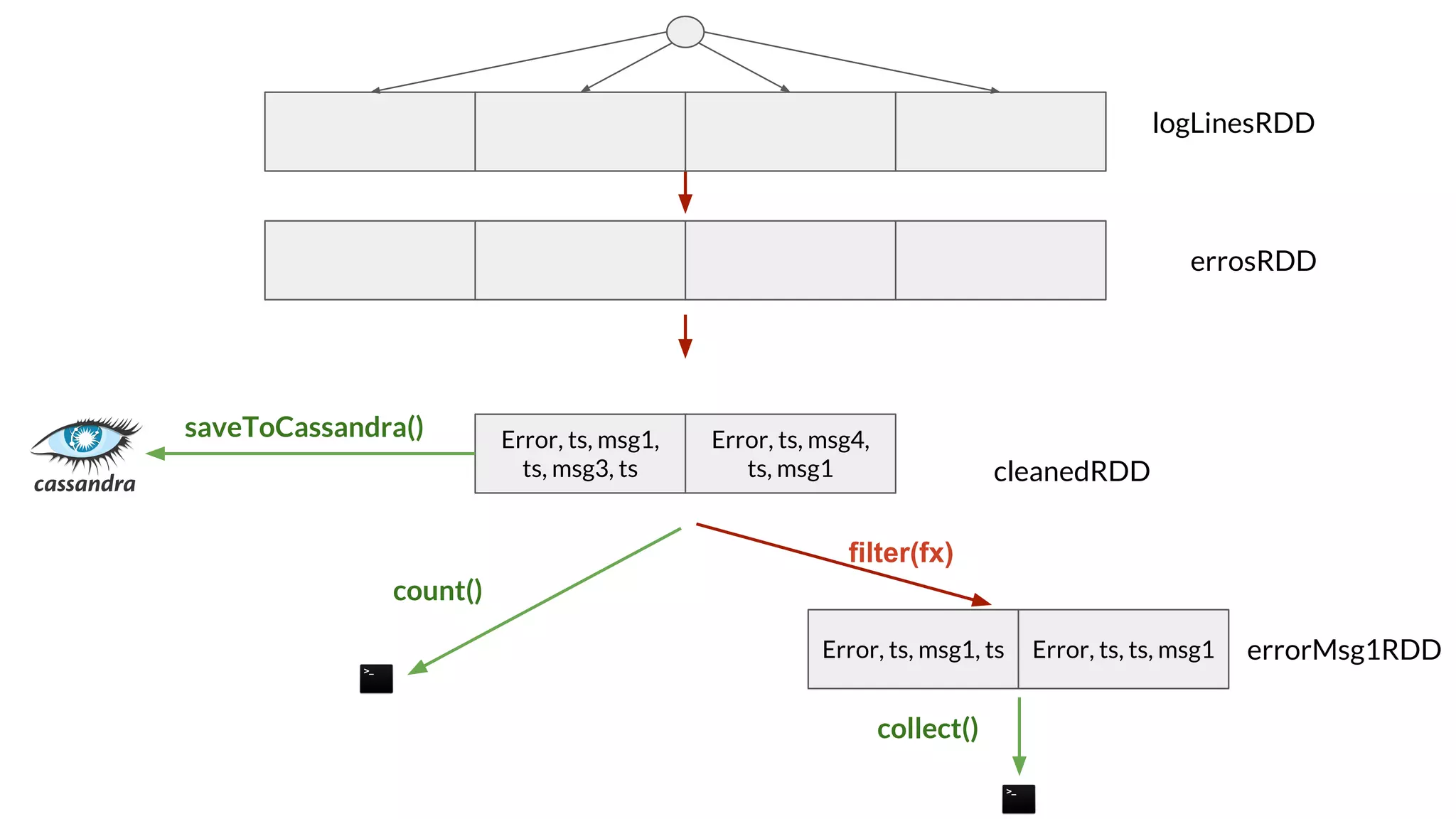
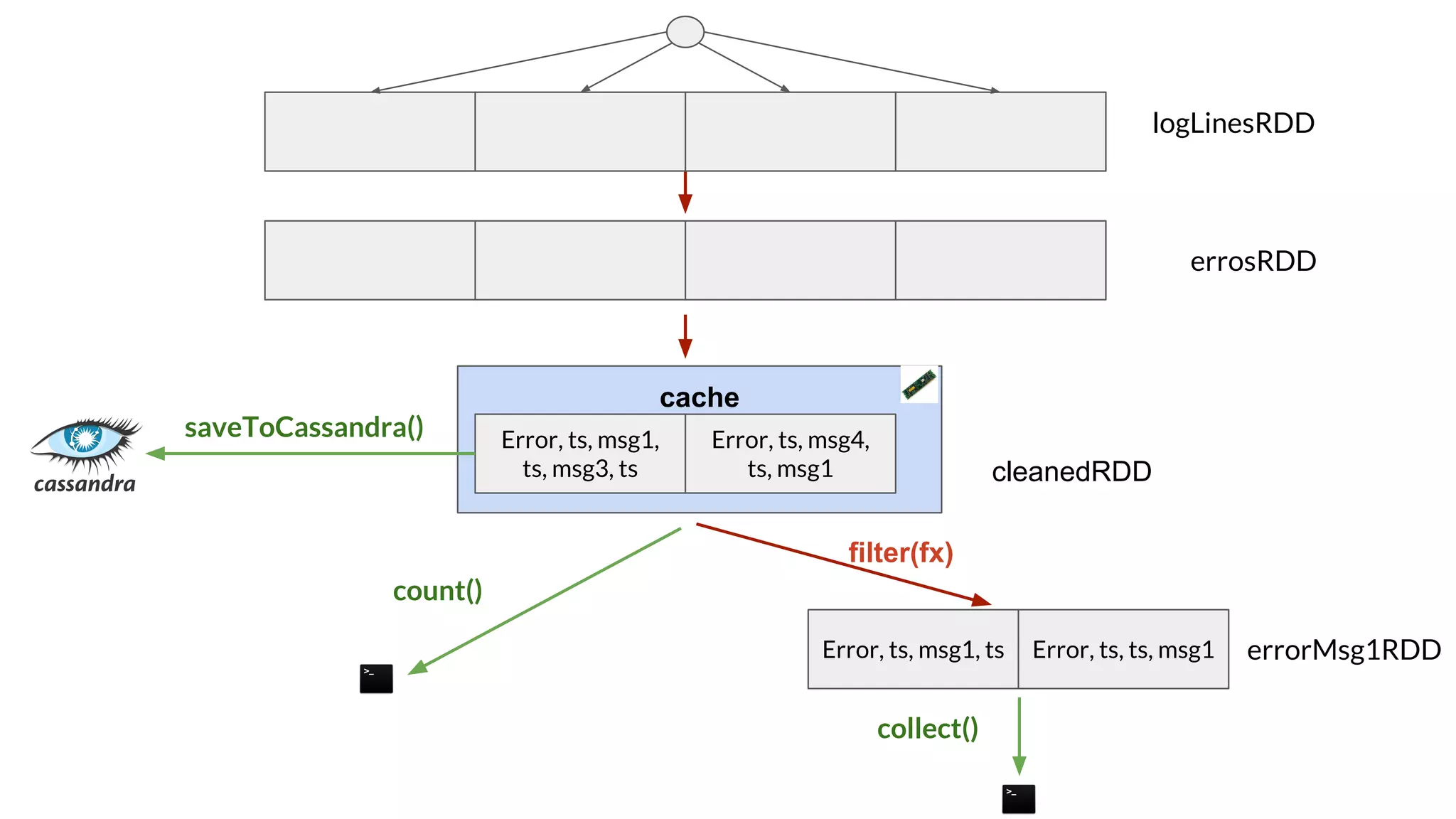





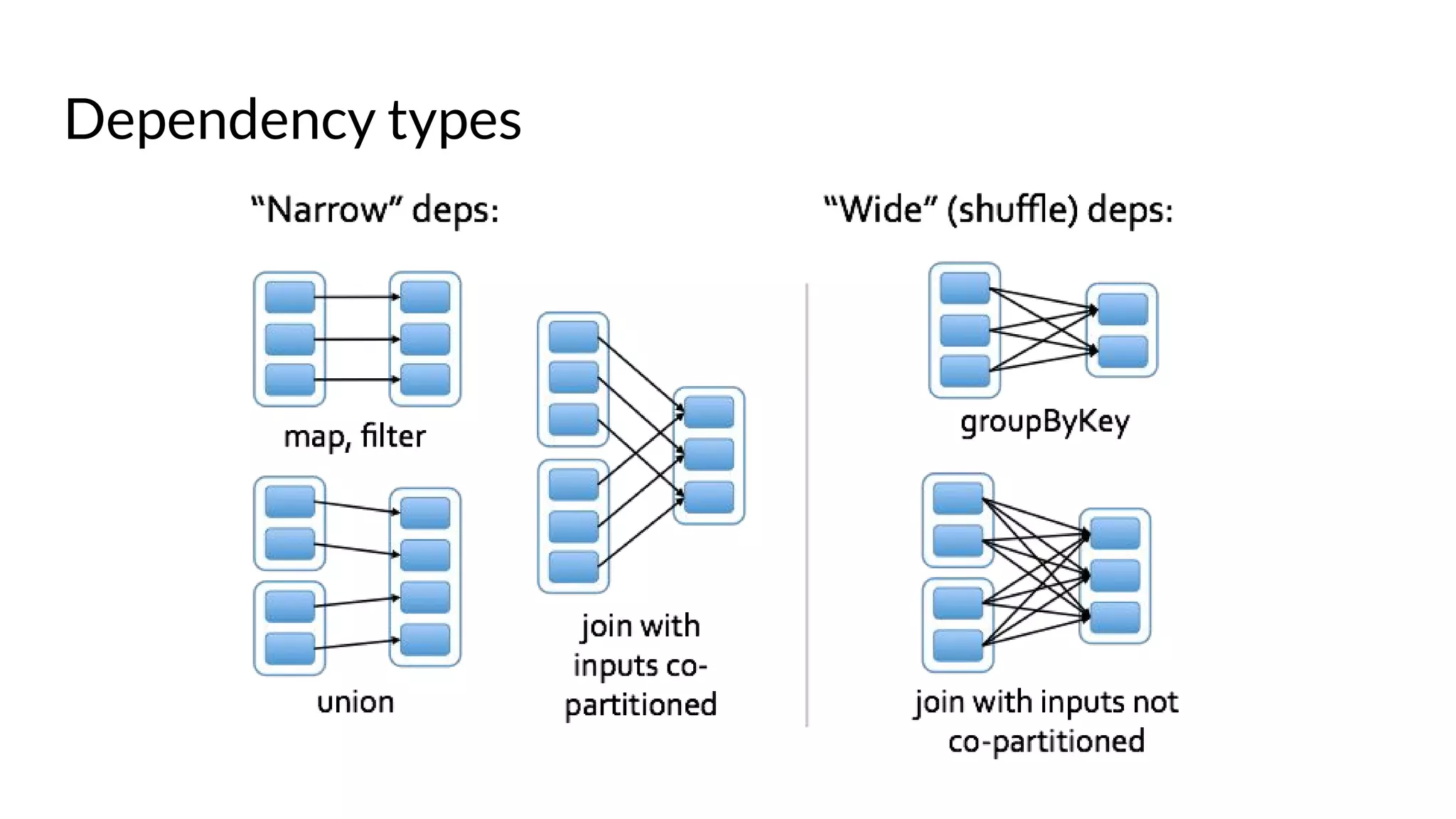
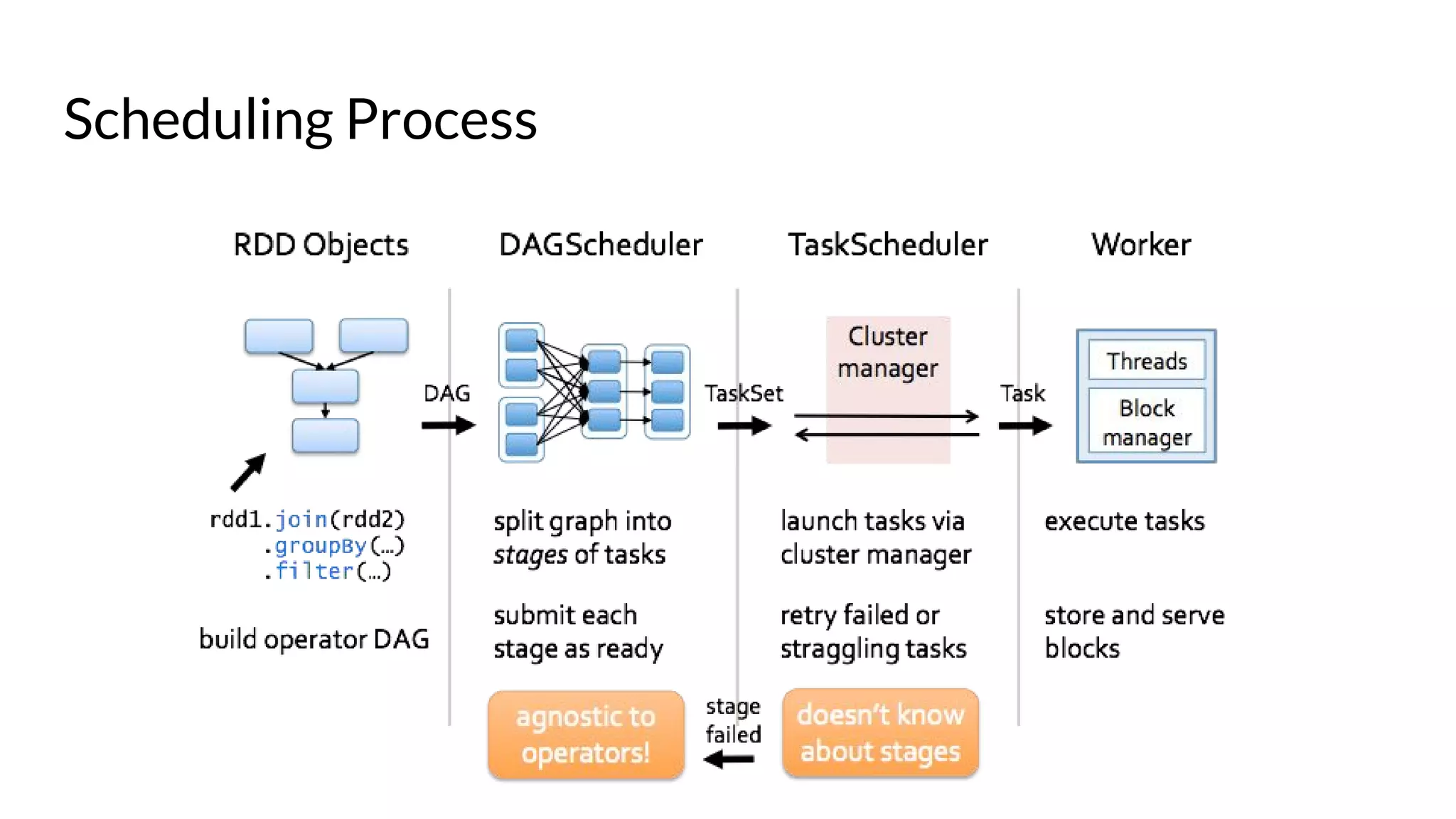
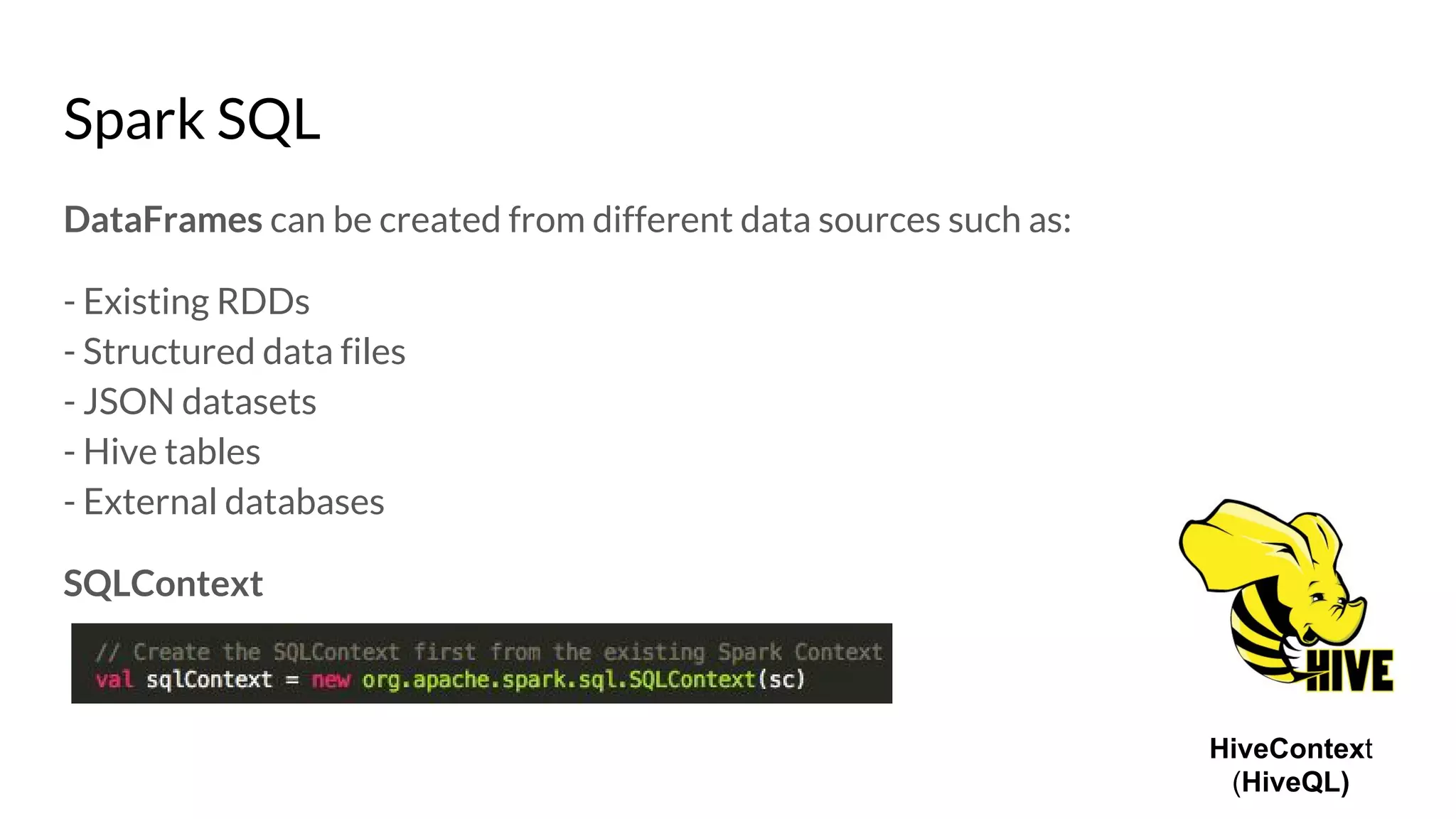
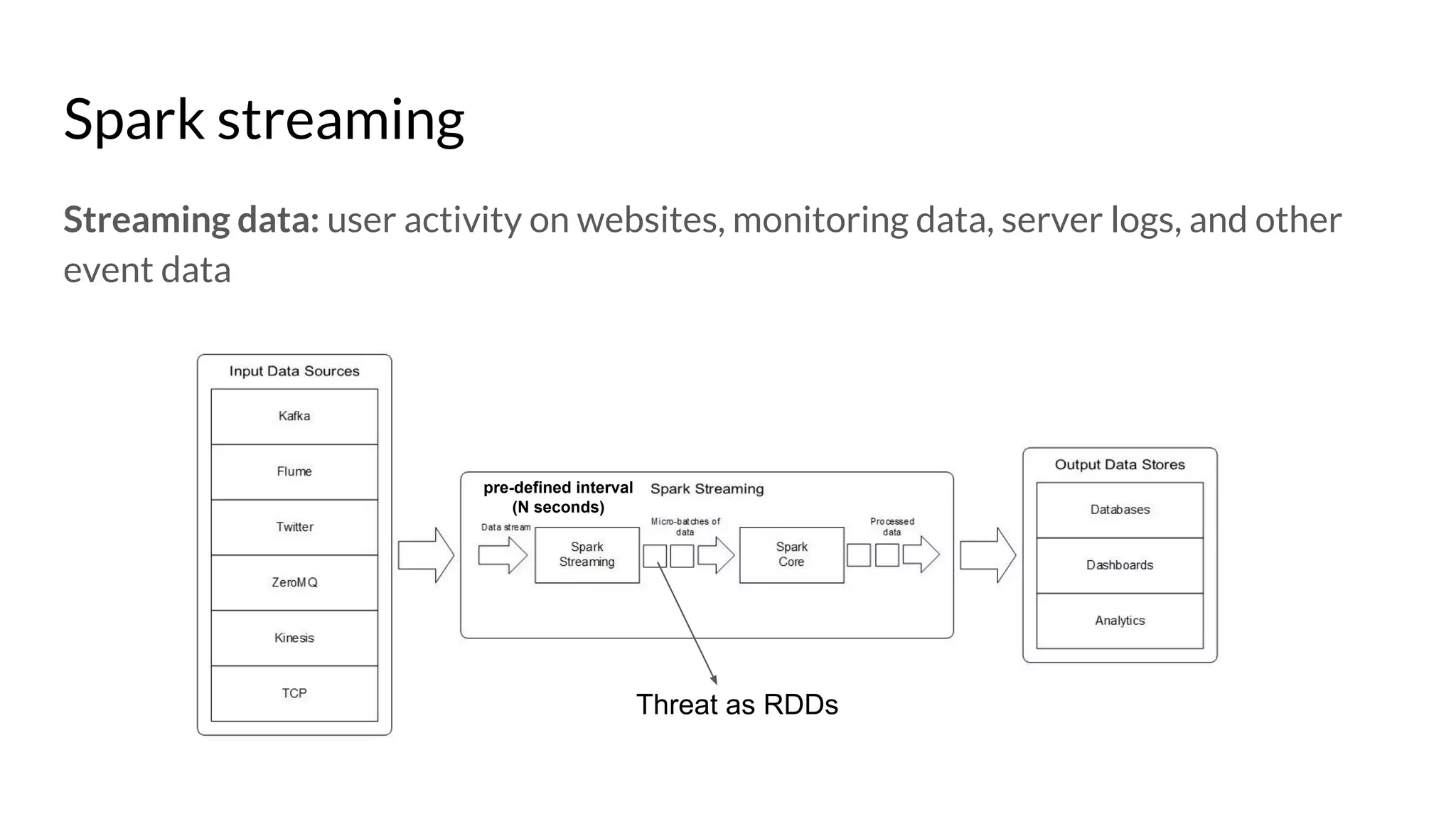






The document compares Apache Spark and Hadoop, highlighting Spark's advantages in speed and flexibility for cluster computing while addressing maintenance and integration challenges of Hadoop. It elaborates on Spark's architecture and utilization of Resilient Distributed Datasets (RDDs) for efficient data processing. Additionally, it outlines the lifecycle of a Spark program, various data sources for Spark SQL DataFrames, and mentions Spark's additional libraries and monitoring capabilities.























































































