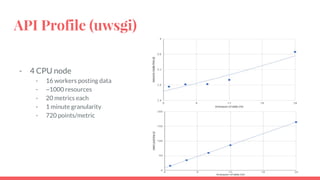
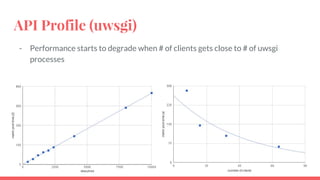
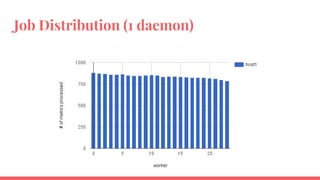
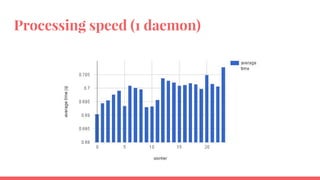
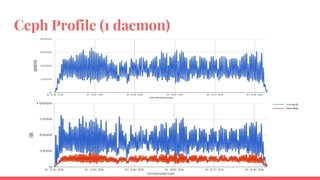
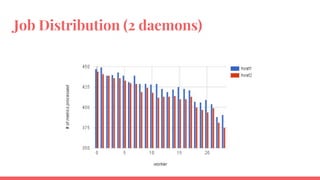
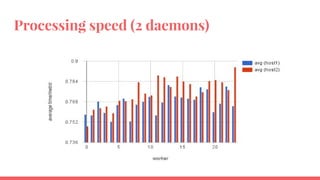
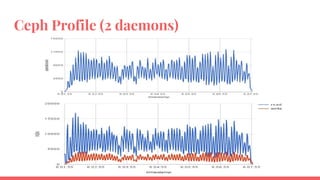
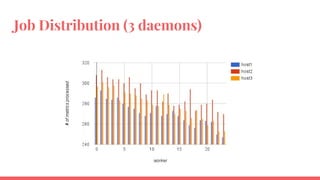
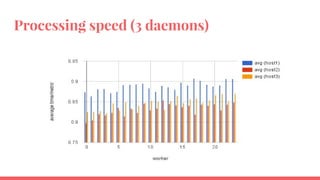
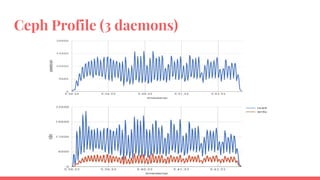
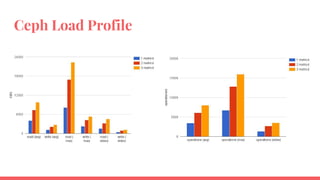
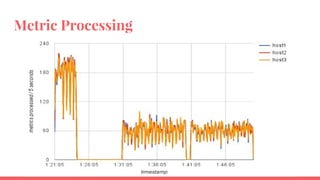
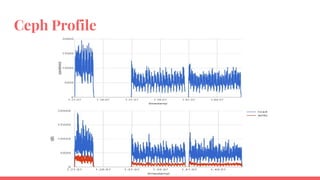
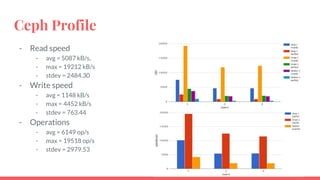
The document outlines the benchmarking tests for Gnocchi using a specific configuration across three physical hosts with OpenStack and Ceph. It details the performance metrics of Gnocchi's API and MetricD services, including injection times, read and write speeds, and operational throughput under various metrics processing configurations. Additionally, it presents observations on contention issues and future testing plans to enhance performance further.























![thanks
gord[at]live.ca
irc: gordc](https://image.slidesharecdn.com/gnocchiprofiling16-06-20-160620125822/85/Gnocchi-Profiling-2-1-x-42-320.jpg)



































































