Downloaded 16 times












![Shard allocation
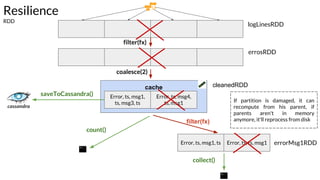
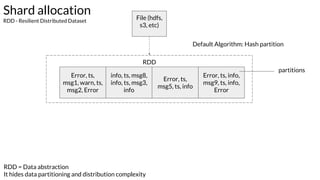
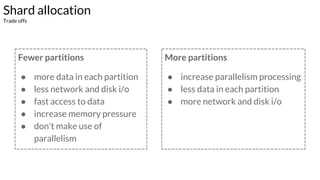
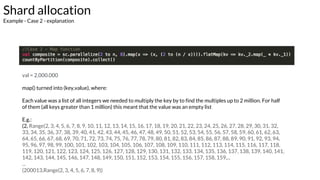
Example - Case 1 - explanation
val = 2.000.000 / 8 = 250.000
Range partition:
[0] -> 2 - 250.000
[1] -> 250.001 - 500.000
[2] -> 500.001 - 750.000
[3] -> 750.001 - 1.000.000
[4] -> 1.000.001 - 1.025.000
[5] -> 1.025.001 - 1.050,000
[6] -> 1.050.001 - 1.075.000
[7] -> 1.075.001 - 2.000.000](https://image.slidesharecdn.com/apachespark-part2-170119123923/85/Apache-Spark-Internals-Part-2-20-320.jpg)




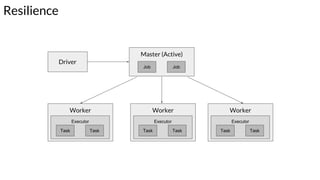
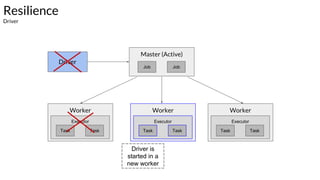
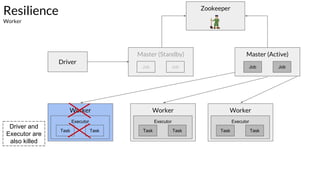
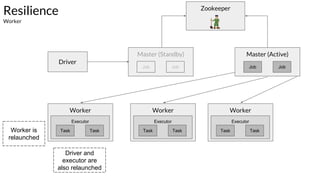
The document discusses the resilience and fault-tolerant features of Apache Spark's Resilient Distributed Dataset (RDD), explaining how RDDs can recover from node failures using lineage-based recomputation. It also covers shard allocation strategies, partition configurations, and the trade-offs involved in setting the number of partitions to optimize performance. Additionally, examples illustrate common partitioning issues and their solutions within Spark's ecosystem.























































































