Downloaded 48 times







































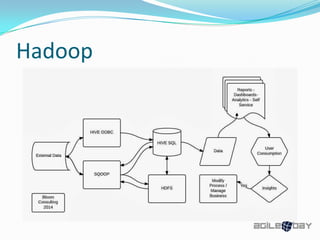





The document outlines the role and architecture of Enterprise Data Warehousing (EDW) and its integration with Hadoop for data management and analytics. It highlights data modeling techniques, data ingestion methods, and the importance of hybrid data warehouses that combine various data sources. The document also discusses advanced technologies such as machine learning, cloud services, and the future of Hadoop in relation to emerging trends like artificial intelligence.










































































