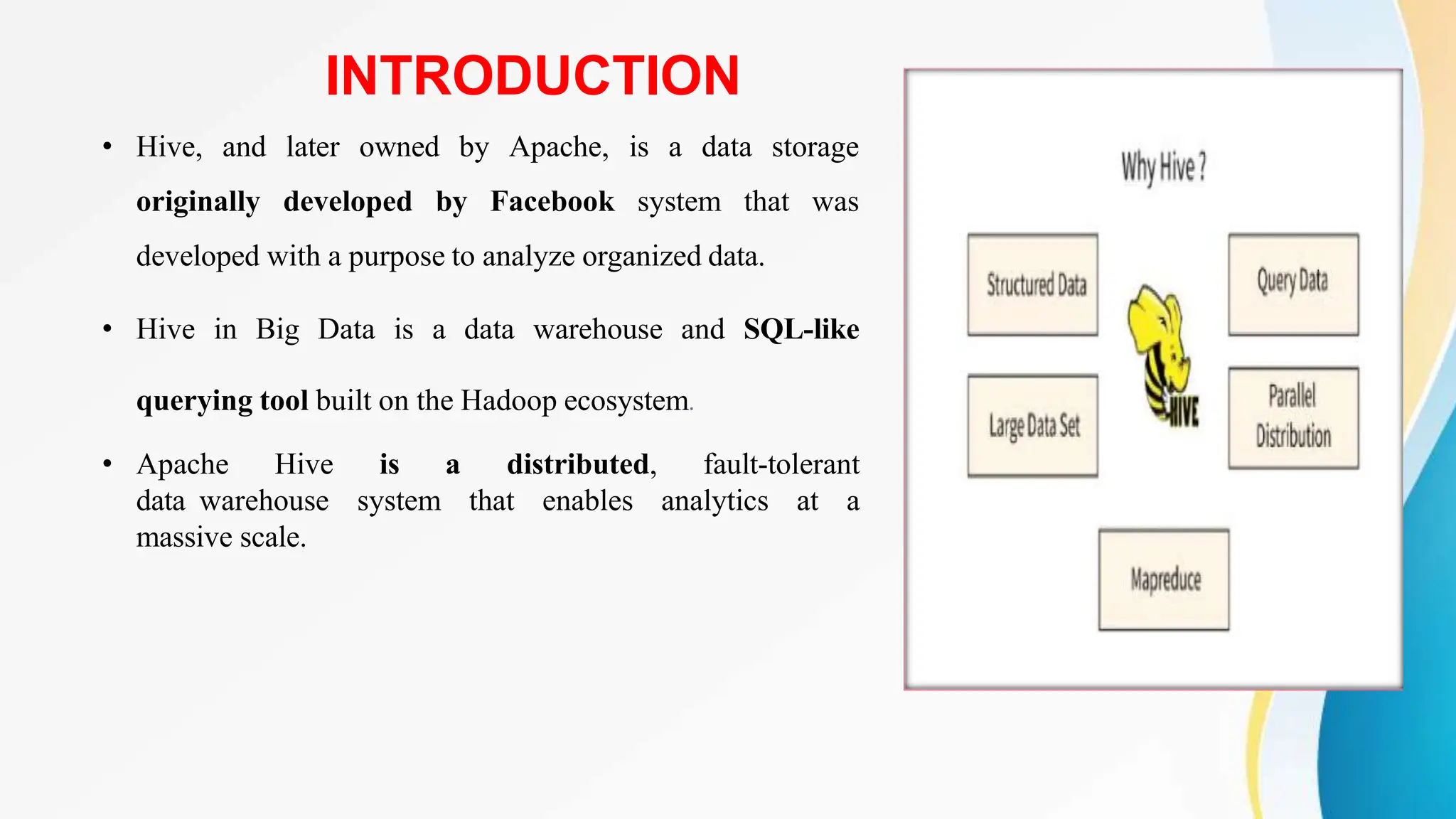
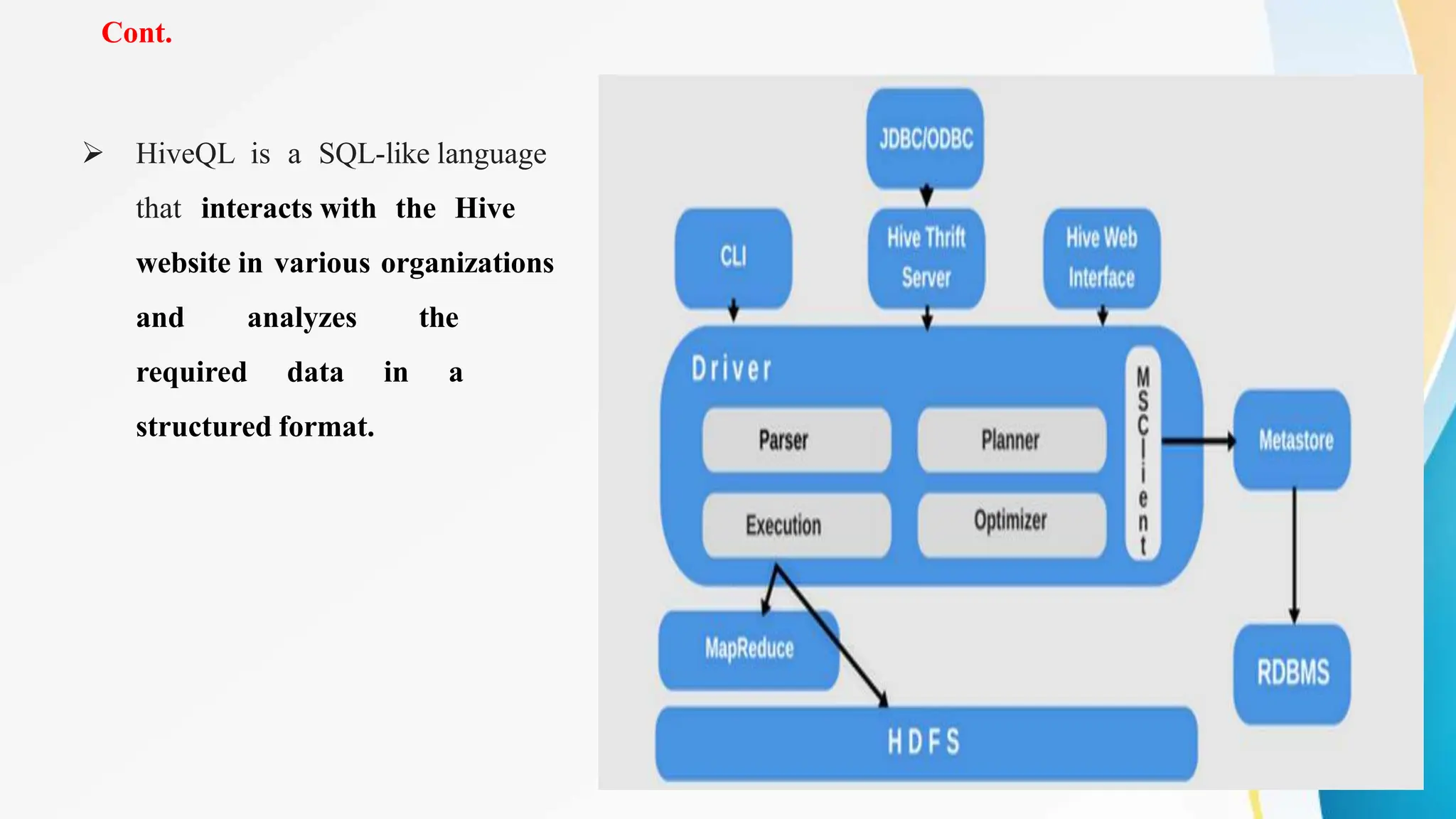
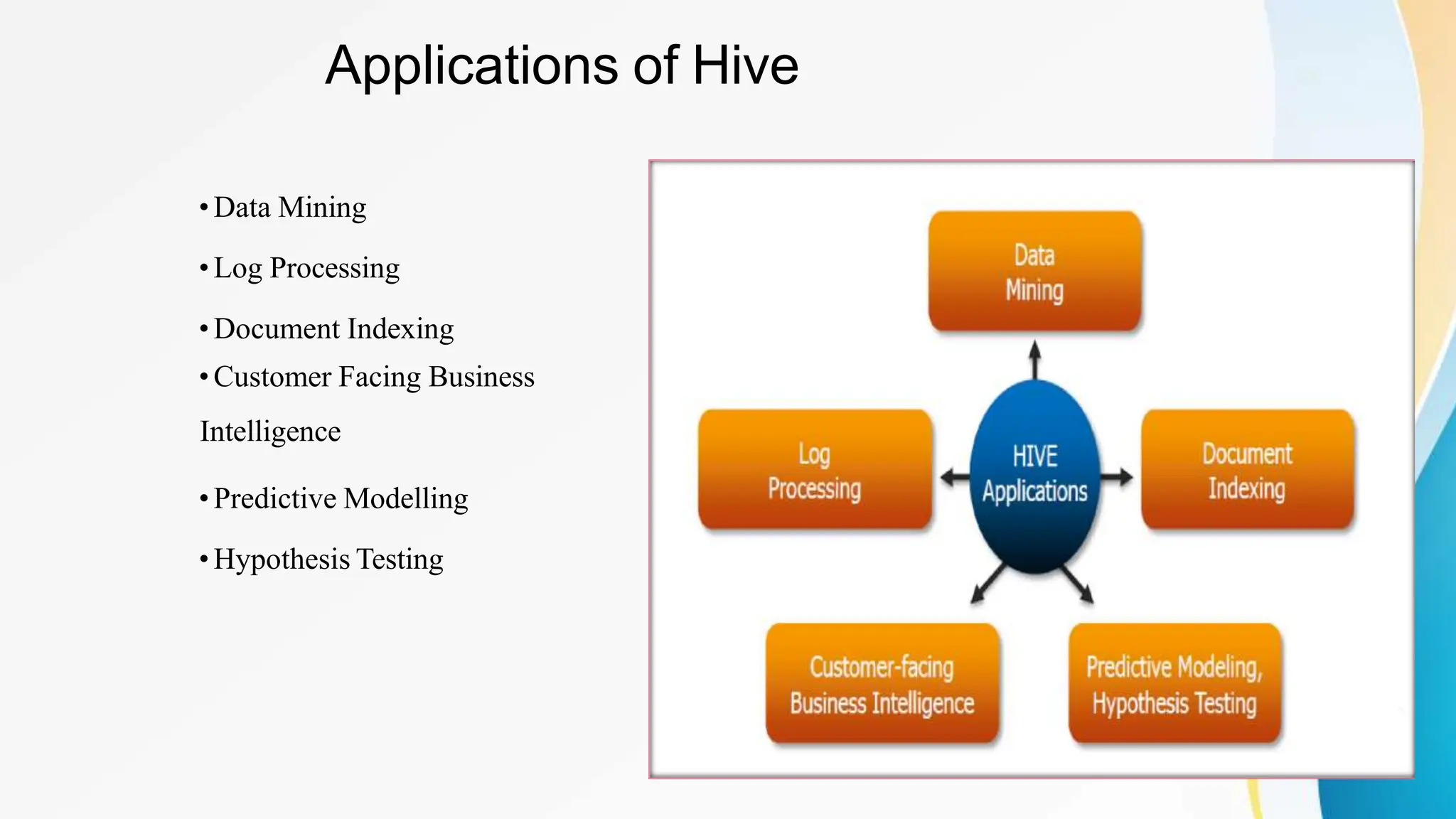
Apache Hive is a data warehouse system that enables large-scale data analytics on Hadoop clusters. It allows users to query and analyze large datasets using SQL-like queries. Hive provides scalability, flexibility, and integration with other Hadoop tools. It is commonly used by large organizations to store and analyze large amounts of collected data to generate data-driven insights.