Downloaded 11 times


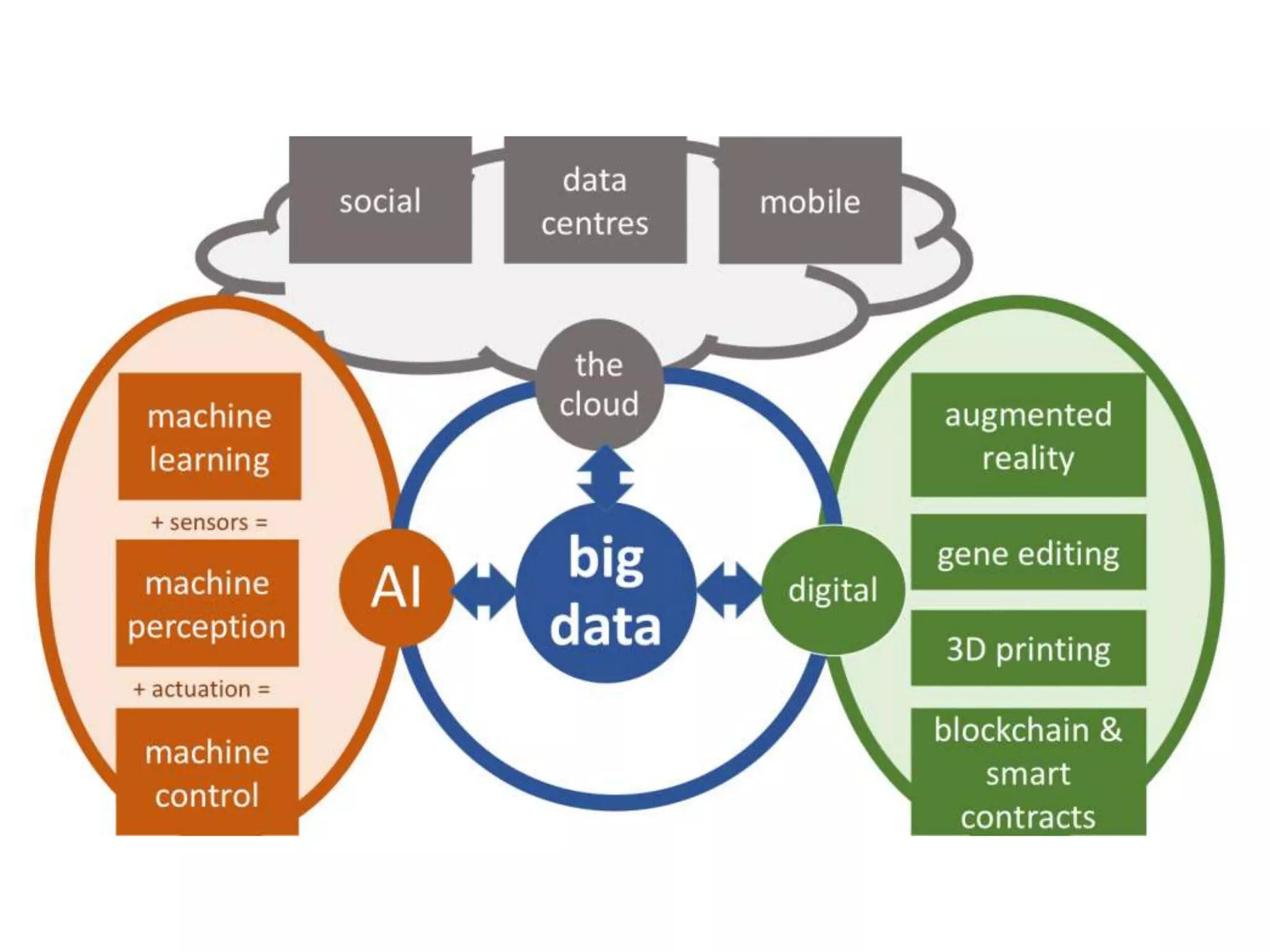





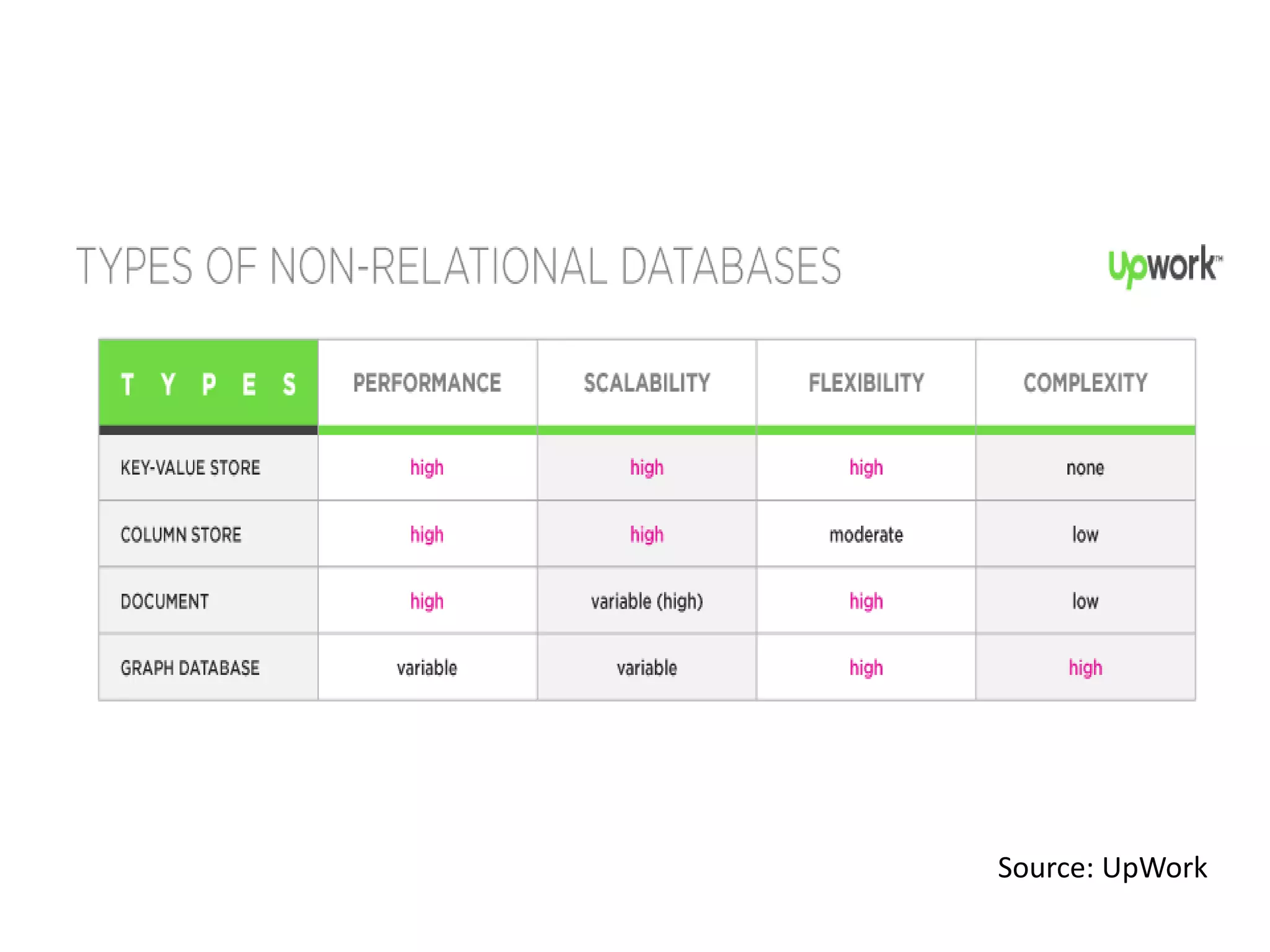

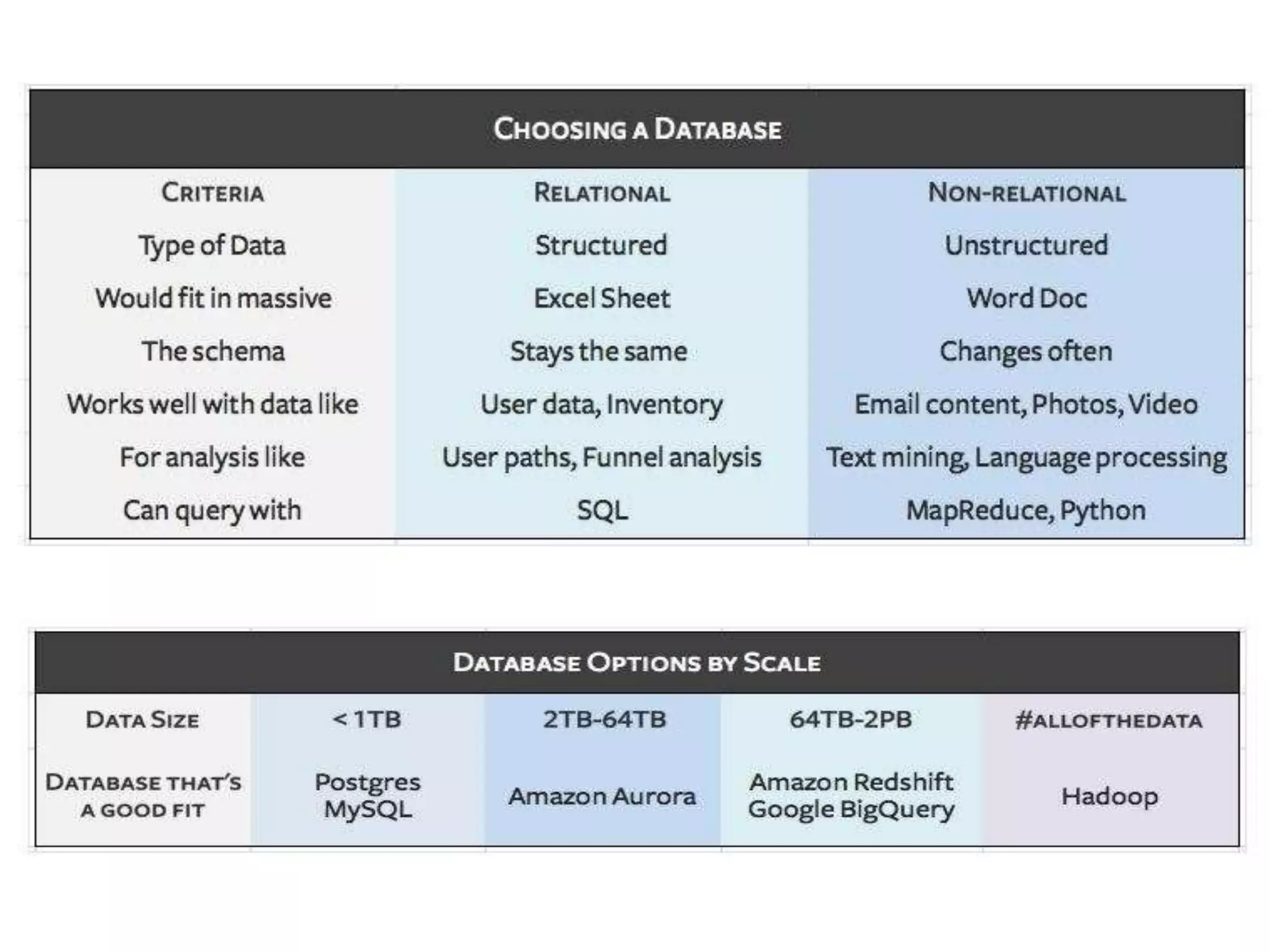
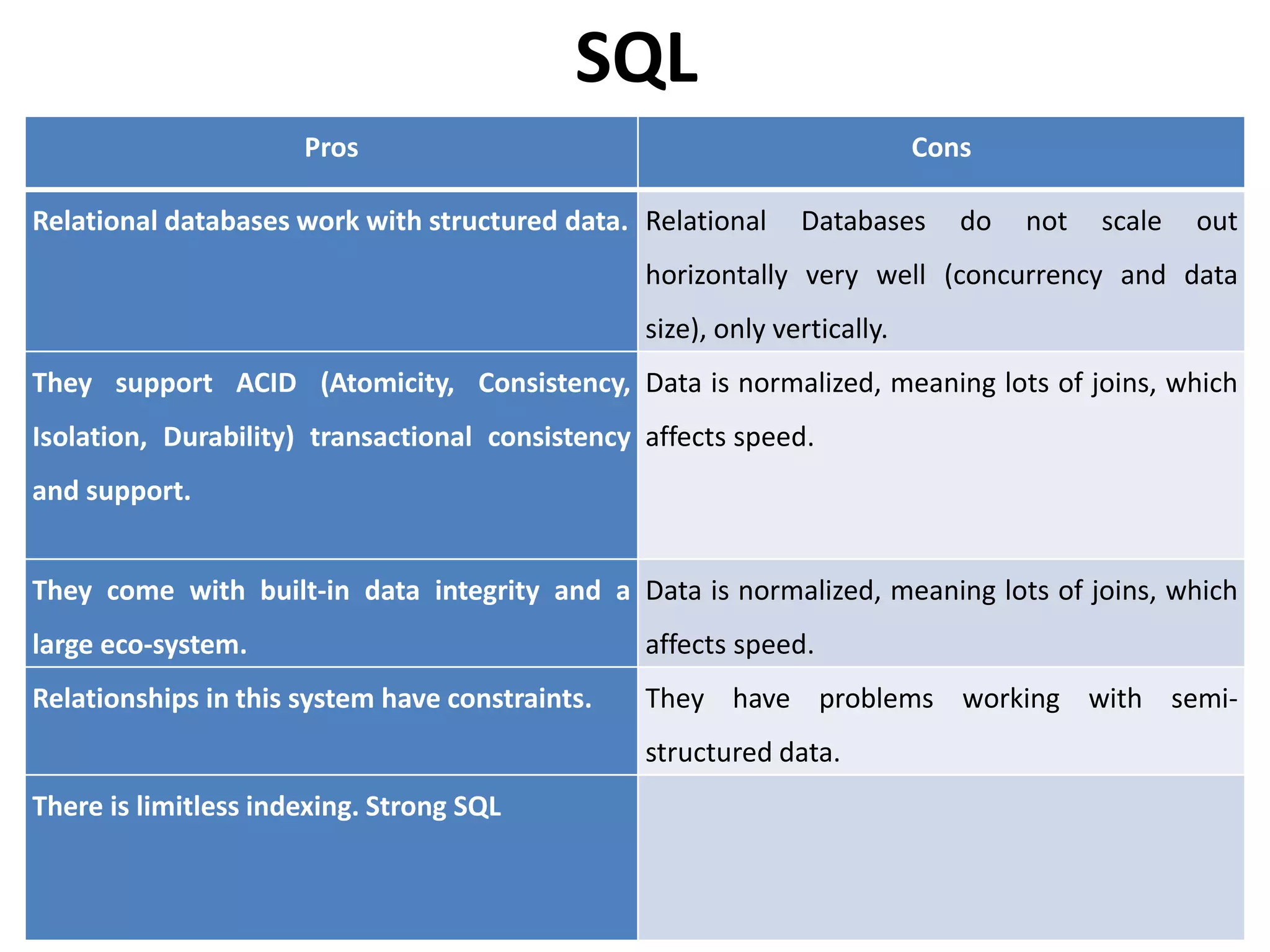


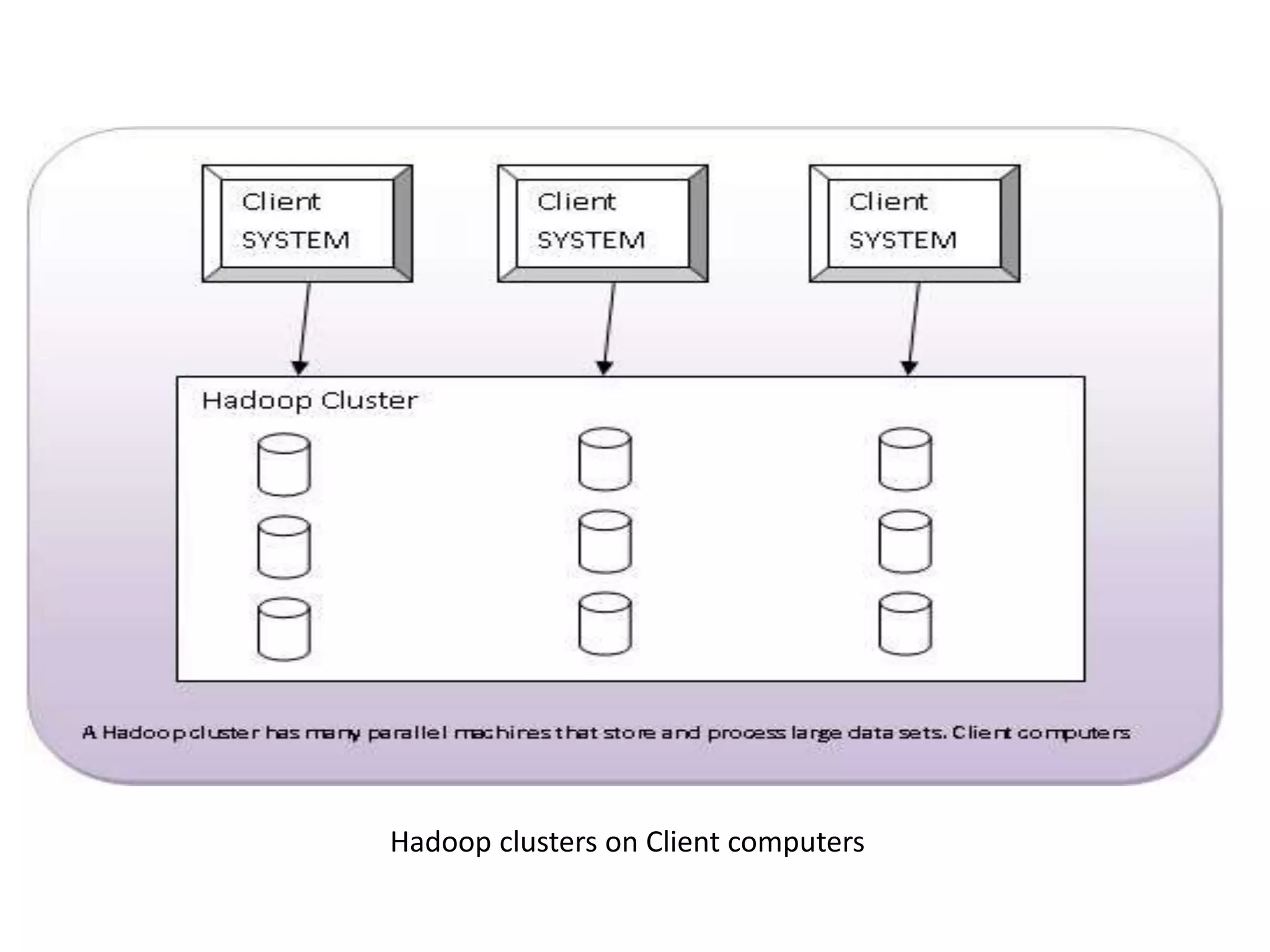




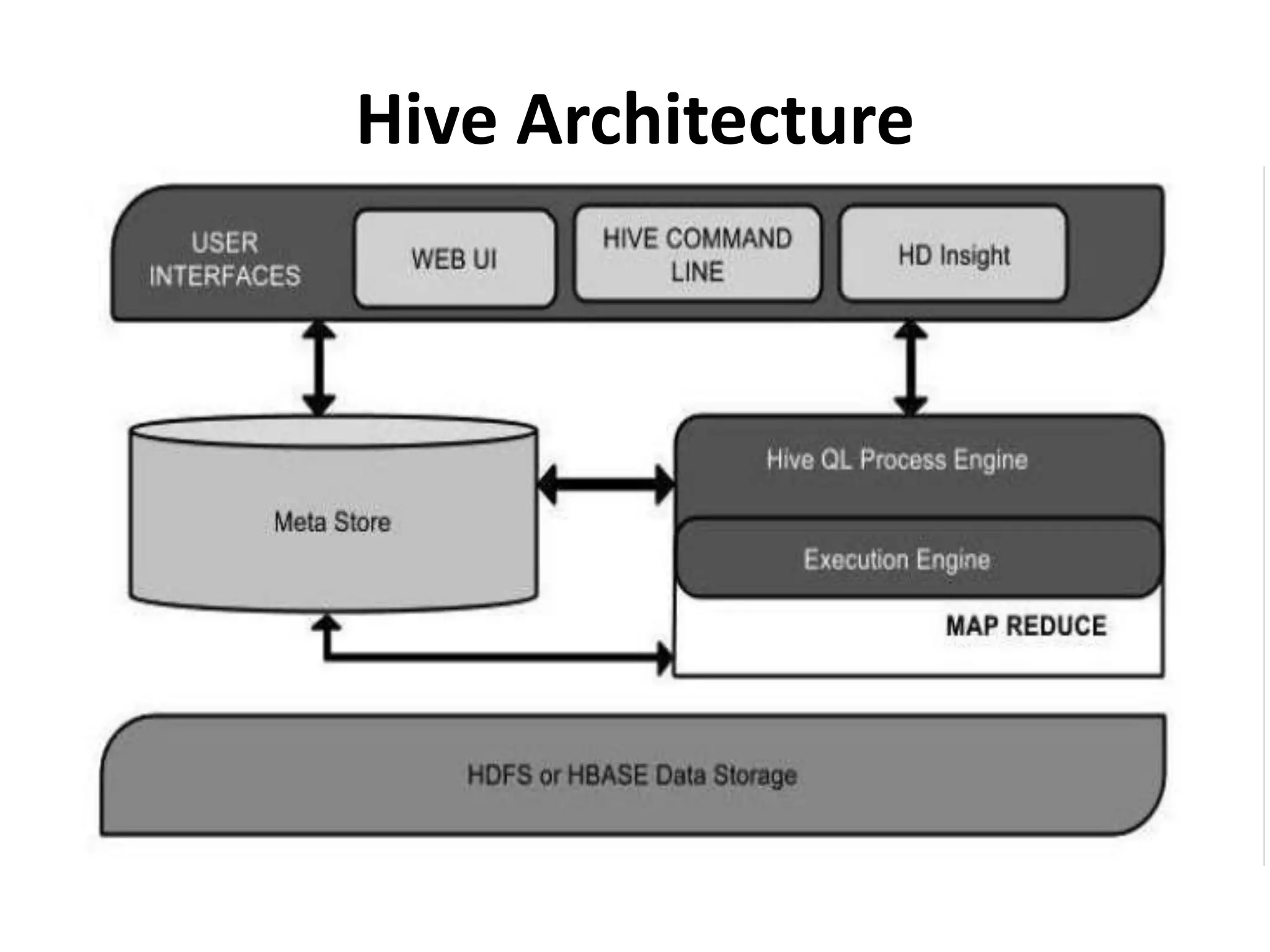





The document outlines the history and functionality of Apache Hive, a data warehouse infrastructure tool built on Hadoop, designed to summarize and analyze large datasets using a familiar SQL interface known as HiveQL. Initially developed by Facebook, Hive facilitates easy querying and processing of structured data while leveraging Hadoop’s processing capabilities. The document also compares SQL and NoSQL databases, discussing their advantages, disadvantages, and applications in handling big data.












































































