Download as PDF, PPTX



















![MegaEase
Sets Operation
l Considering we have the following query:
l app=“foo” AND __name__=“requests_total”
l How to do intersection with two invert index list?
l General Algorithm Interview Question
l By given two integer array, return their intersection.
l A[] = { 4, 1, 6, 7, 3, 2, 9 }
l B[] = { 11,30, 2, 70, 9}
l return { 2, 9} as there intersection
l By given two integer array return their union.
l A[] = { 4, 1, 6, 7, 3, 2, 9 }
l B[] = { 11,30, 2, 70, 9}
l return { 4, 1, 6, 7, 3, 2, 9, 11, 30, 70} as there union
l Time: O(m*n) - no extra space](https://image.slidesharecdn.com/prometheus-210222135250/85/How-Prometheus-Store-the-Data-27-320.jpg)
![MegaEase
Sort The Array
l If we sort the array
__name__="requests_total" -> [ 999, 1000, 1001, 2000000, 2000001, 2000002, 2000003 ]
app="foo" -> [ 1, 3, 10, 11, 12, 100, 311, 320, 1000, 1001, 10002 ]
intersection => [ 1000, 1001 ]
l We can have efficient algorithm
l O(m+n) : two pointers for each array.
while (idx1 < len1 && idx2 < len2) {
if (a[idx1] > b[idx2] ) {
idx2++
} else if (a[idx1] < b[idx2] ) {
idx1++
} else {
c = append(c, a[idx1])
}
}
return c
l Series ID must be easy to sort, use
MD5 or UUID is not a good idea
( V2 use the hash ID)
l Delete the data could cause the
index rebuild.](https://image.slidesharecdn.com/prometheus-210222135250/85/How-Prometheus-Store-the-Data-28-320.jpg)








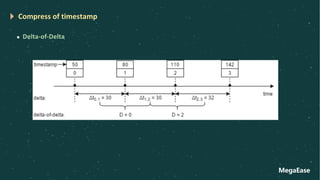
![MegaEase
Compression Algorithm
Compress Timestamp
D = 𝒕𝒏 − 𝒕𝒏"𝟏 − ( 𝒕𝒏"𝟏 − 𝒕𝒏"𝟐)
l D = 0, then store a single ‘0’ bit
l D = [-63, 64], ‘10’ : value (7 bits)
l D = [-255, 256], ‘110’ : value (9 bits)
l D = [-2047, 2048], ‘1110’ : value (12 bits)
l Otherwise store ‘1111’ : D (32 bits)
Compress Values (Double float)
X = 𝑽𝒊 ^ 𝑽𝒊"𝟏
l X = 0, then store a single ‘0’ bit
l X != 0,
首先计算XOR中 Leading Zeros 与 Trailing Zeros 的个数。第一个bit
值存为’1’,第二个bit值为
如果Leading Zeros与Trailing Zeros与前一个XOR值相同,则第2个bit
值存为’0’,而后,紧跟着去掉Leading Zeros与Trailing Zeros以后的
有效XOR值部分。
如果Leading Zeros与Trailing Zeros与前一个XOR值不同,则第2个bit
值存为’1’,而后,紧跟着5个bits用来描述Leading Zeros的个数,再
用6个bits来描述有效XOR值的长度,最后再存储有效XOR值部分
(这种情形下,至少产生了13个bits的冗余信息)](https://image.slidesharecdn.com/prometheus-210222135250/85/How-Prometheus-Store-the-Data-39-320.jpg)





Hao Chen, with over 20 years of experience, discusses the evolution of Prometheus's time series data storage from version 1.x to 2.x and beyond. The new design improves data writing and querying efficiency by using blocks of data that streamline operations and address previous storage challenges. The document outlines concepts such as write-ahead logging, data retention, and index management while highlighting benefits like reduced resource consumption and simplified old data deletion.














](https://cdn.slidesharecdn.com/ss_thumbnails/javajvmtoolsjjug20211007nttdata-211008124040-thumbnail.jpg?width=640&height=640&fit=bounds)




















































