Download as PDF, PPTX








































![cassandra.yaml: `concurrent_compactors`
[…]
concurrent_compactors: 8
[…]
50](https://image.slidesharecdn.com/ilandapachecon2016long-160510203821/85/Cassandra-multi-datacenter-operations-essentials-50-320.jpg)
![cassandra.yaml:
`compaction_throughput_mb_per_sec`
[…]
compaction_throughput_mb_per_sec: 16
[…]
51](https://image.slidesharecdn.com/ilandapachecon2016long-160510203821/85/Cassandra-multi-datacenter-operations-essentials-51-320.jpg)
![cassandra.yaml:
`inter_dc_stream_throughput_outbound_megabits_per_sec`
[…]
# inter_dc_stream_throughput_outbound_megabits_per_sec: 200
[…]
52](https://image.slidesharecdn.com/ilandapachecon2016long-160510203821/85/Cassandra-multi-datacenter-operations-essentials-52-320.jpg)

















![the nodetool utility (1/2)
• command line interface for managing a cluster.
• nodetool [options] command [args]
nodetool help
nodetool help command name
• use Salt Stack (or equivalent) to get command results
coming from all nodes.
70](https://image.slidesharecdn.com/ilandapachecon2016long-160510203821/85/Cassandra-multi-datacenter-operations-essentials-70-320.jpg)













































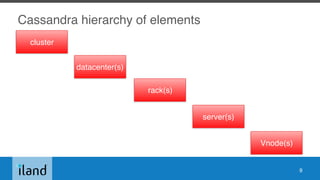
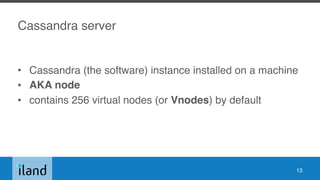
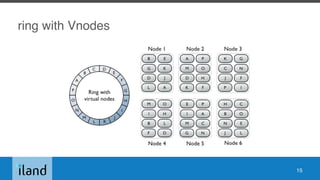
The document outlines essential operations for Apache Cassandra in multi-datacenter environments, covering configuration, tuning, tools, and monitoring best practices. It discusses various key concepts such as data hierarchy, replication strategies, and consistency levels, alongside practical recommendations for tuning system performance. The talk primarily focuses on versions 2.0.x to 3.0.x, leaving out post-3.1 features and other general aspects of data modeling and authentication.



































































