Download as PDF, PPTX





































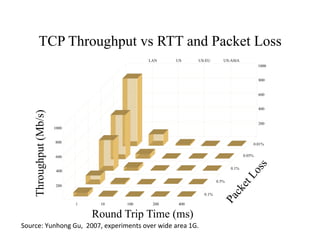

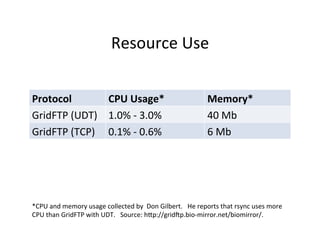
![Case
Study:
Bio-‐mirror
[The
open
source
GridFTP]
from
the
Globus
project
has
recently
been
improved
to
offer
UDP-‐based
file
transport,
with
long-‐distance
speed
improvements
of
3x
to
10x
over
the
usual
TCP-‐based
file
transport.
-‐-‐
Don
Gilbert,
August
2010,
bio-‐mirror.net](https://image.slidesharecdn.com/02-managing-big-data-11-v5-111114072318-phpapp02/85/Managing-Big-Data-Chapter-2-SC-11-Tutorial-52-320.jpg)



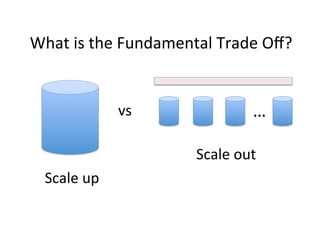
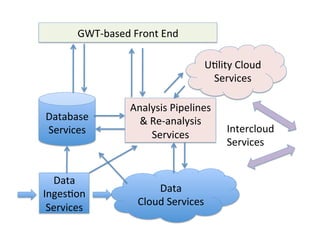
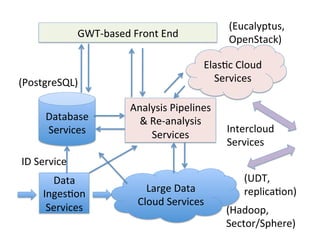
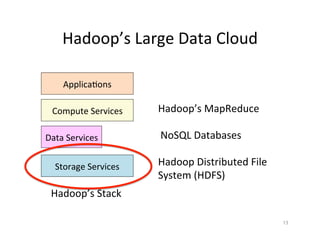
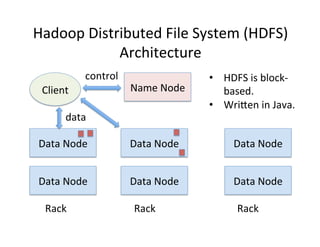
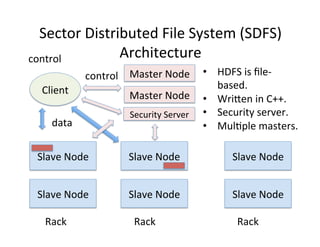
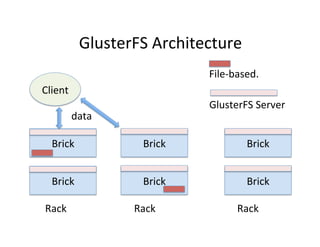
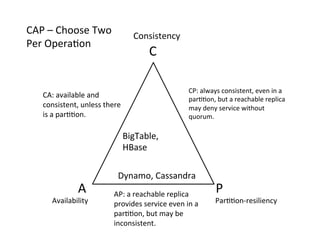
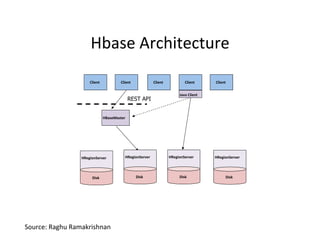
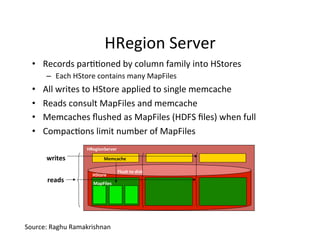
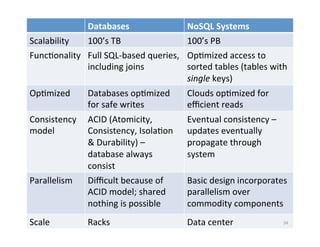
This document provides an introduction to data management techniques for big data. It discusses using databases to store metadata and pointers to files, as well as using distributed file systems like HDFS, Sector/Sphere, and GlusterFS to store large amounts of data. NoSQL databases are also covered as an alternative to traditional SQL databases for large, unstructured datasets. The chapter aims to help readers understand the tradeoffs between scaling up single systems versus scaling out across many systems when dealing with big data.






































































































