Download to read offline
















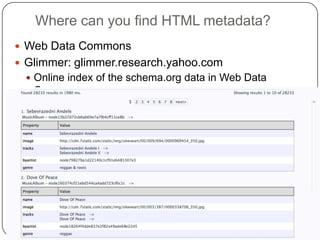

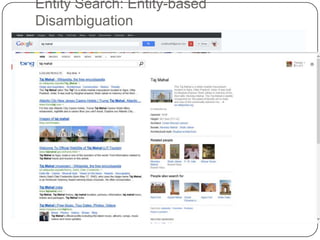
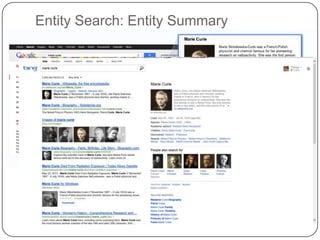
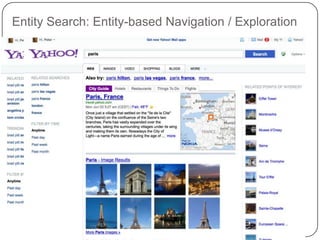
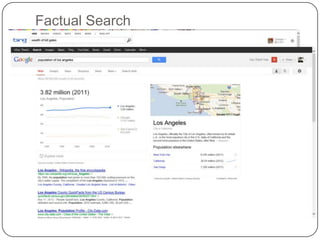
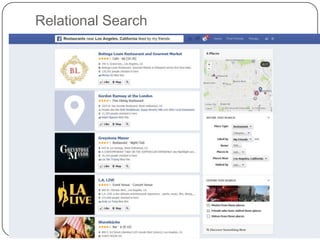
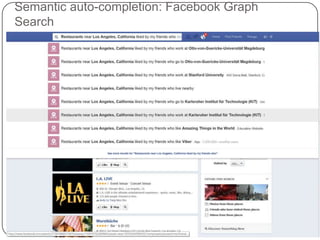
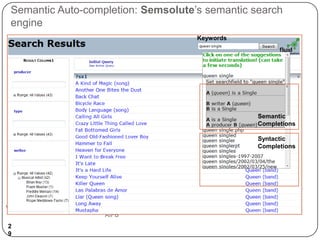
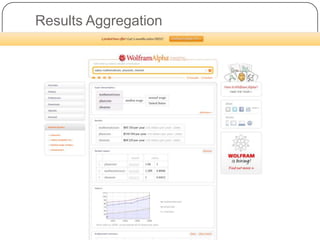

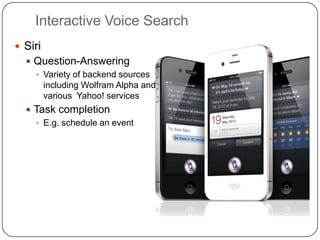
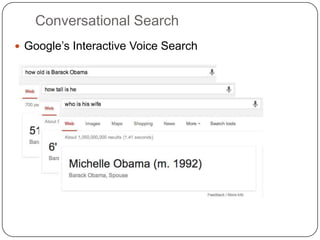



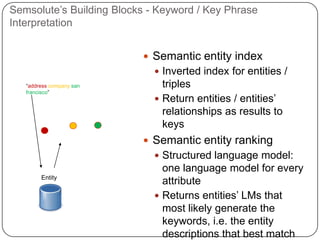
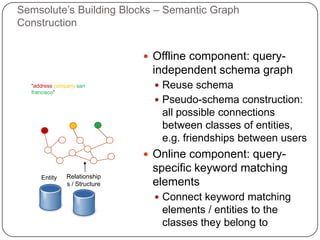
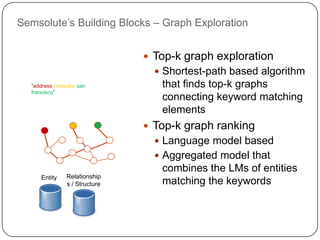
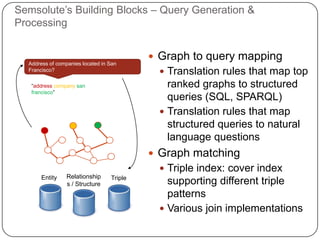

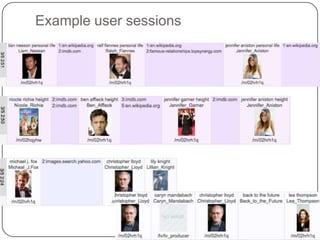
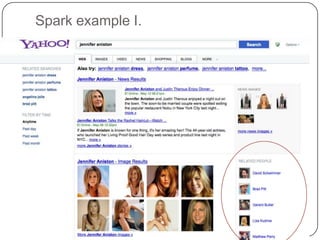
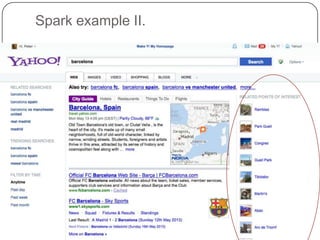
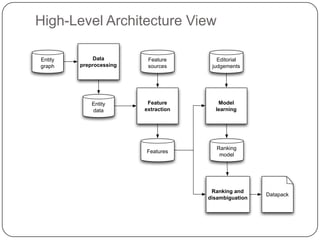





This document summarizes a presentation on semantic search given by Peter Mika from Yahoo! Research, Spain and Thanh Tran from Semsolute, Germany. It discusses why semantic search is needed to address complex queries, describes what semantic search is and how it uses semantic models, and provides examples of innovative semantic search applications such as entity search, relational search, and conversational search. It also outlines some of the main technological building blocks used in semantic search systems, including entity recognition, ranking, aggregation, and knowledge graph construction and exploration techniques.



















































































