This document discusses several key aspects of mathematics and algorithms used in internet information retrieval and search engines:
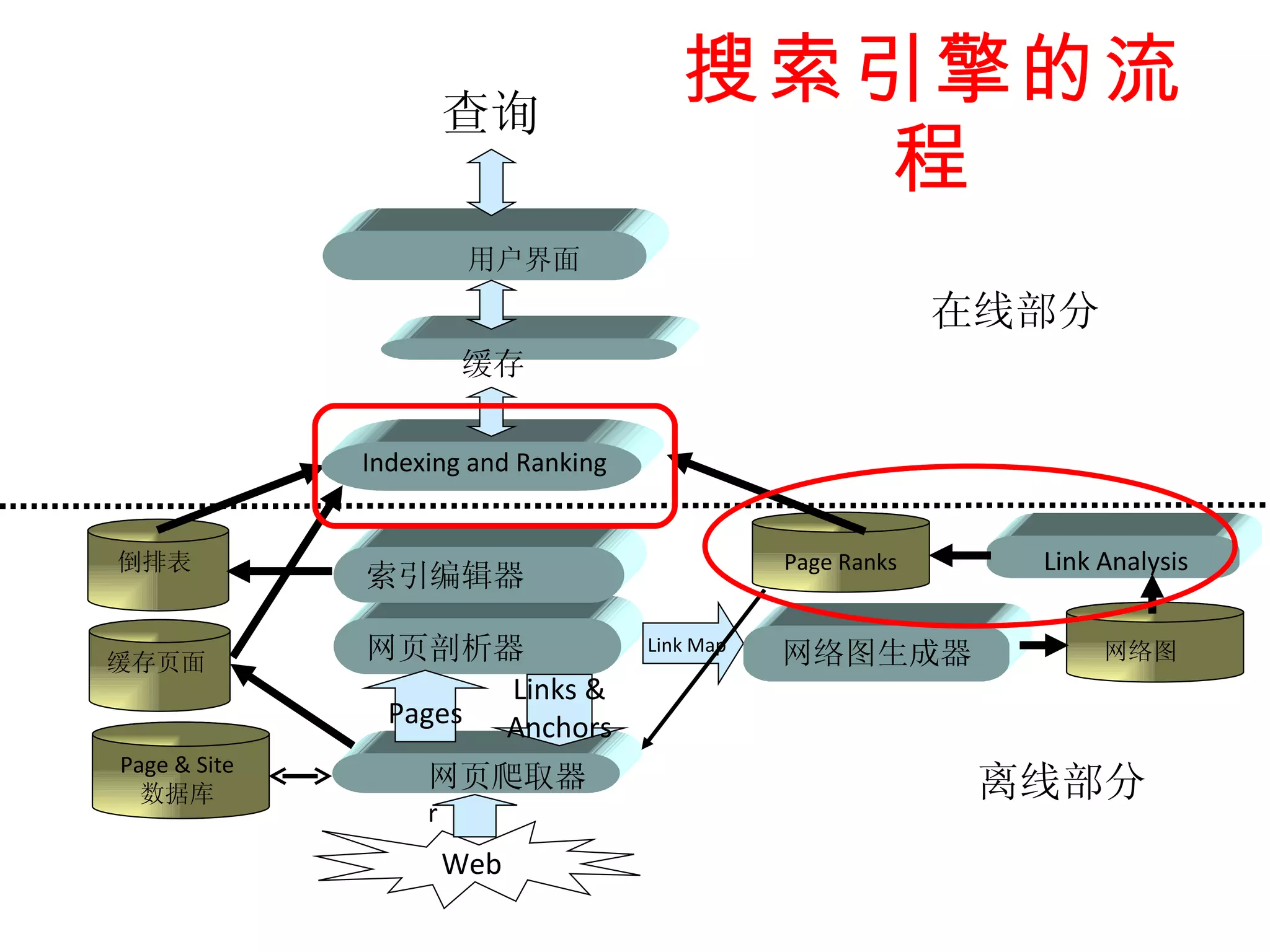
1. It explains how search engines like Google can rapidly rank billions of web pages using algorithms based on the topology and link structure of the web graph, such as PageRank.
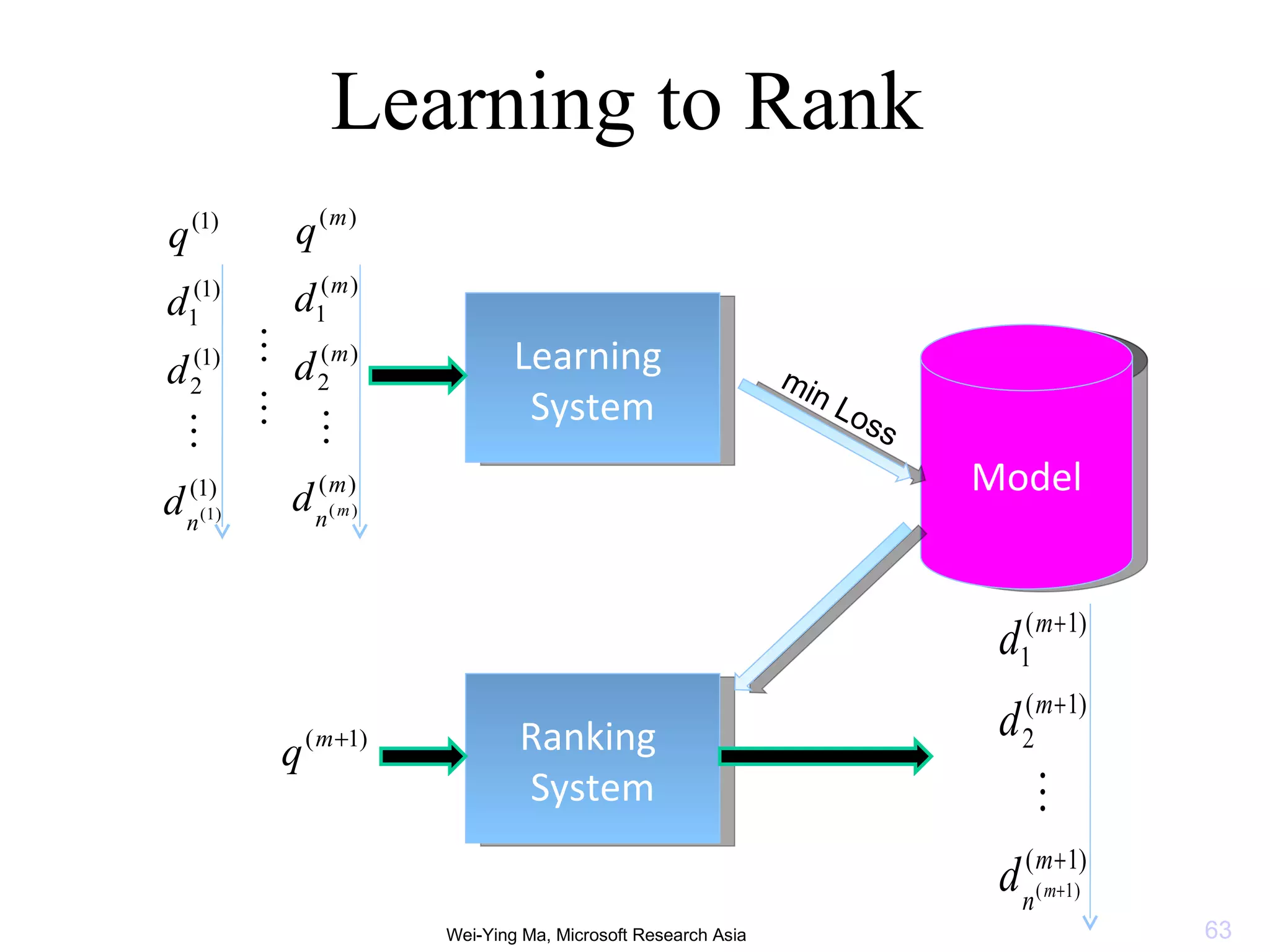
2. It describes two main types of page ranking algorithms - static importance ranking based on link analysis, and dynamic relevance ranking based on statistical learning models to match pages to queries.
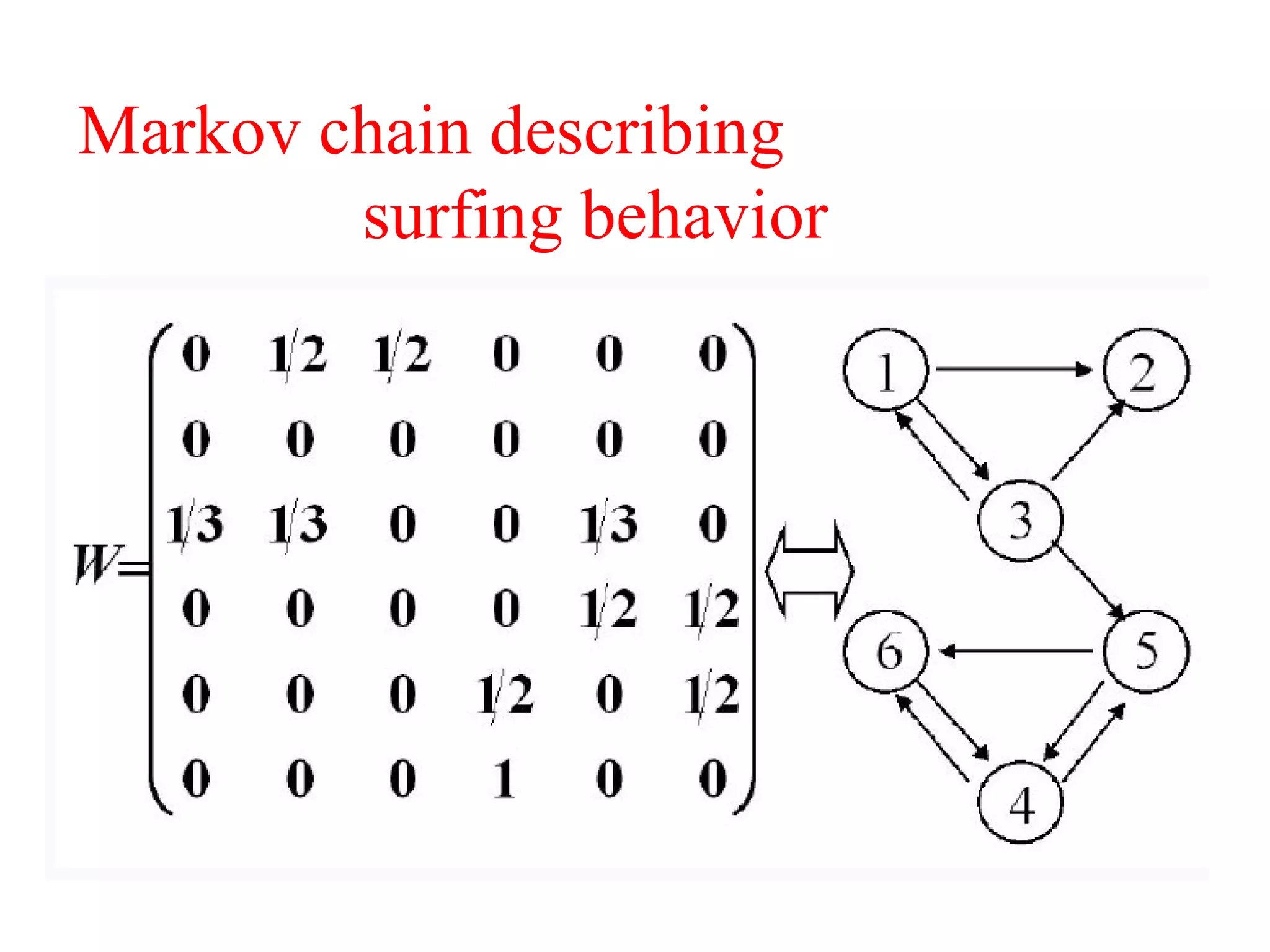
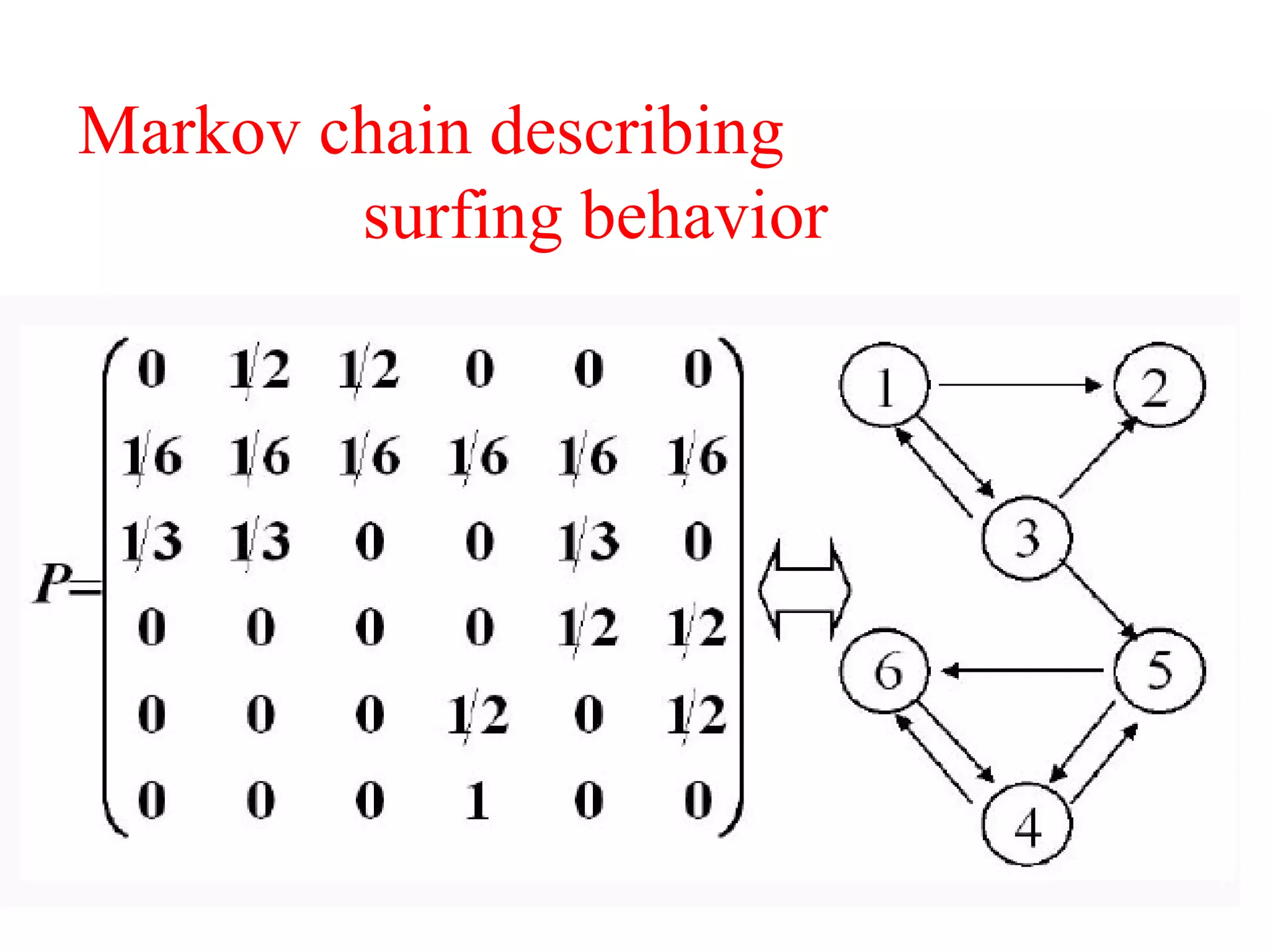
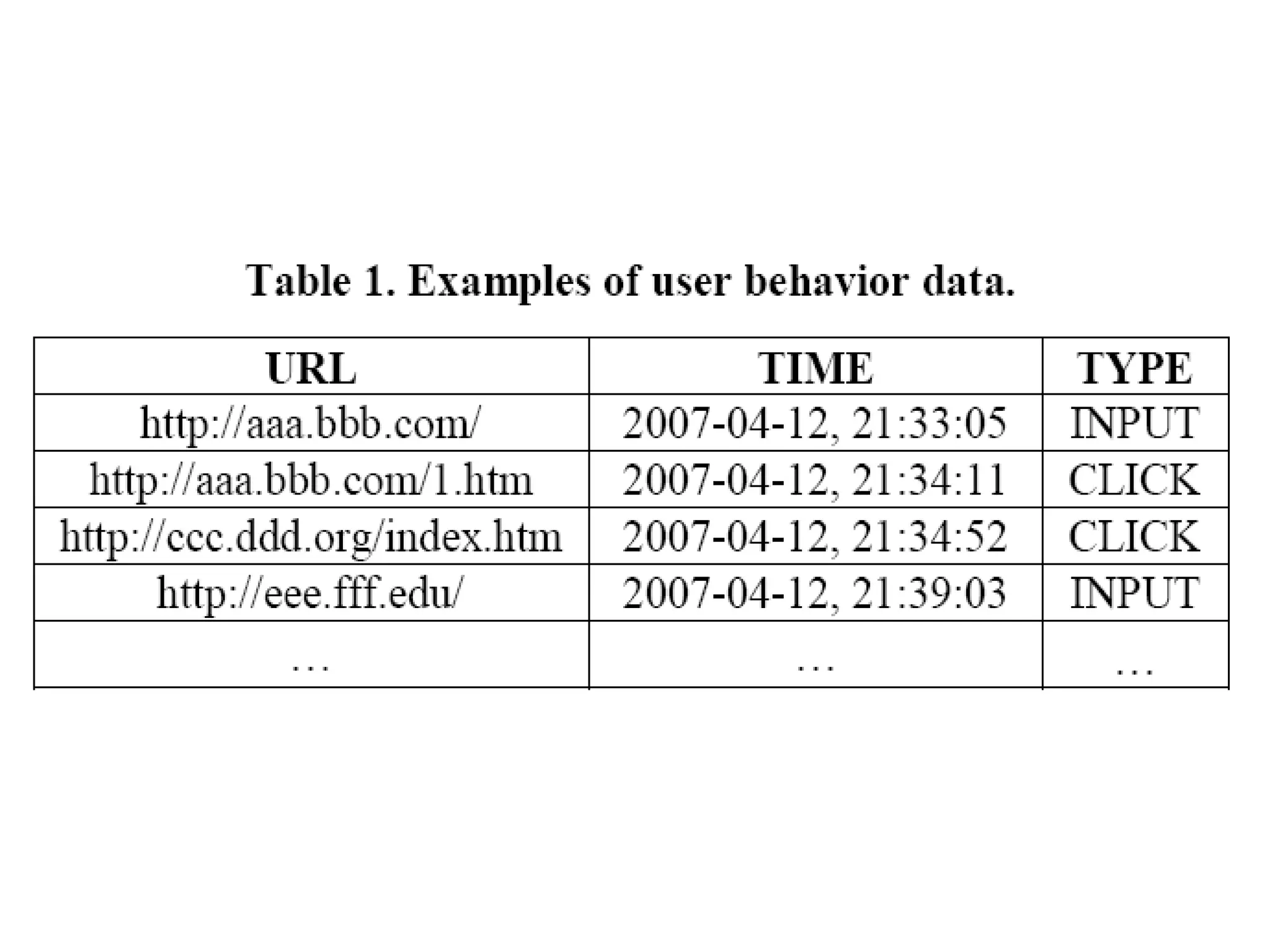
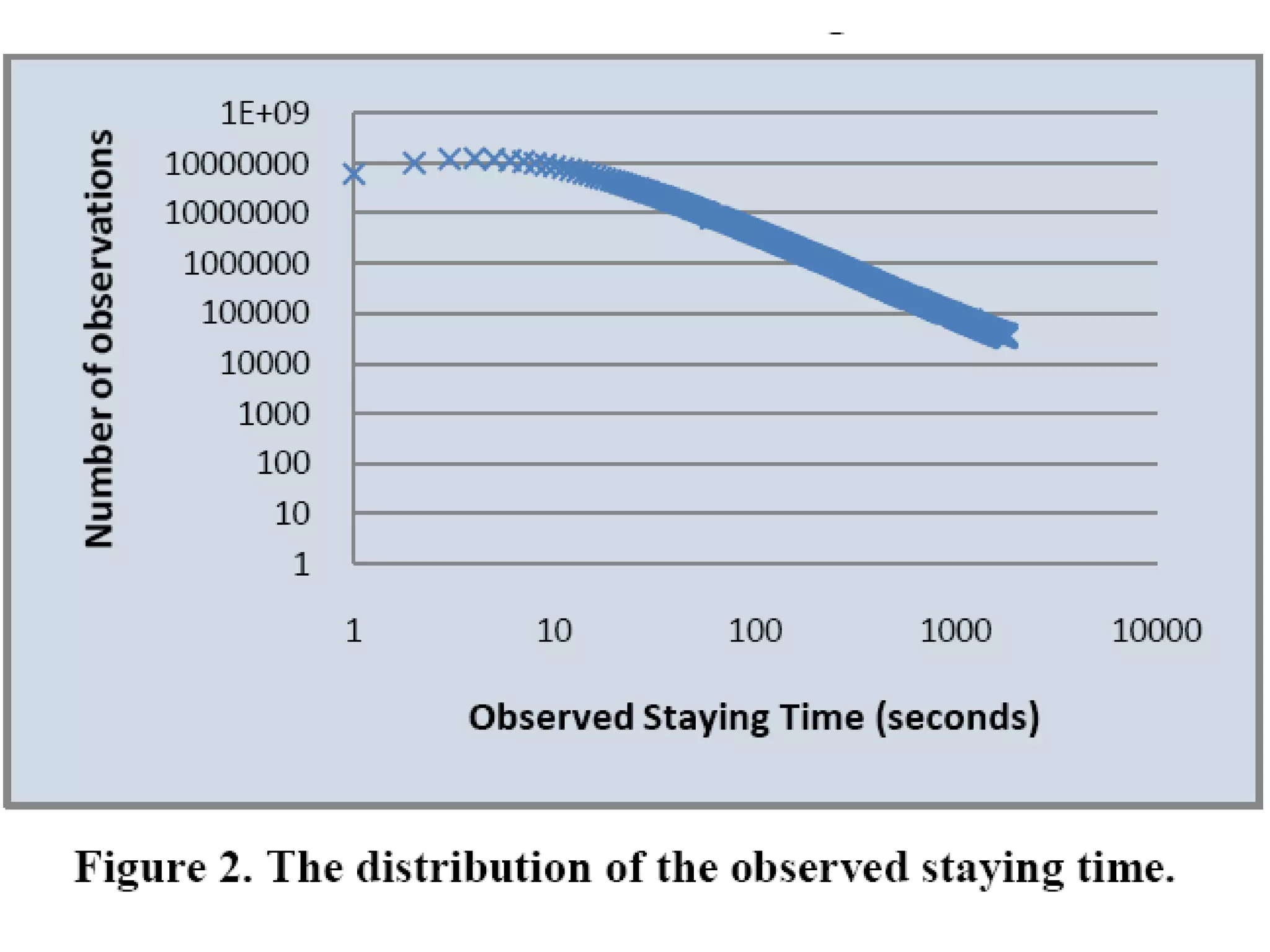
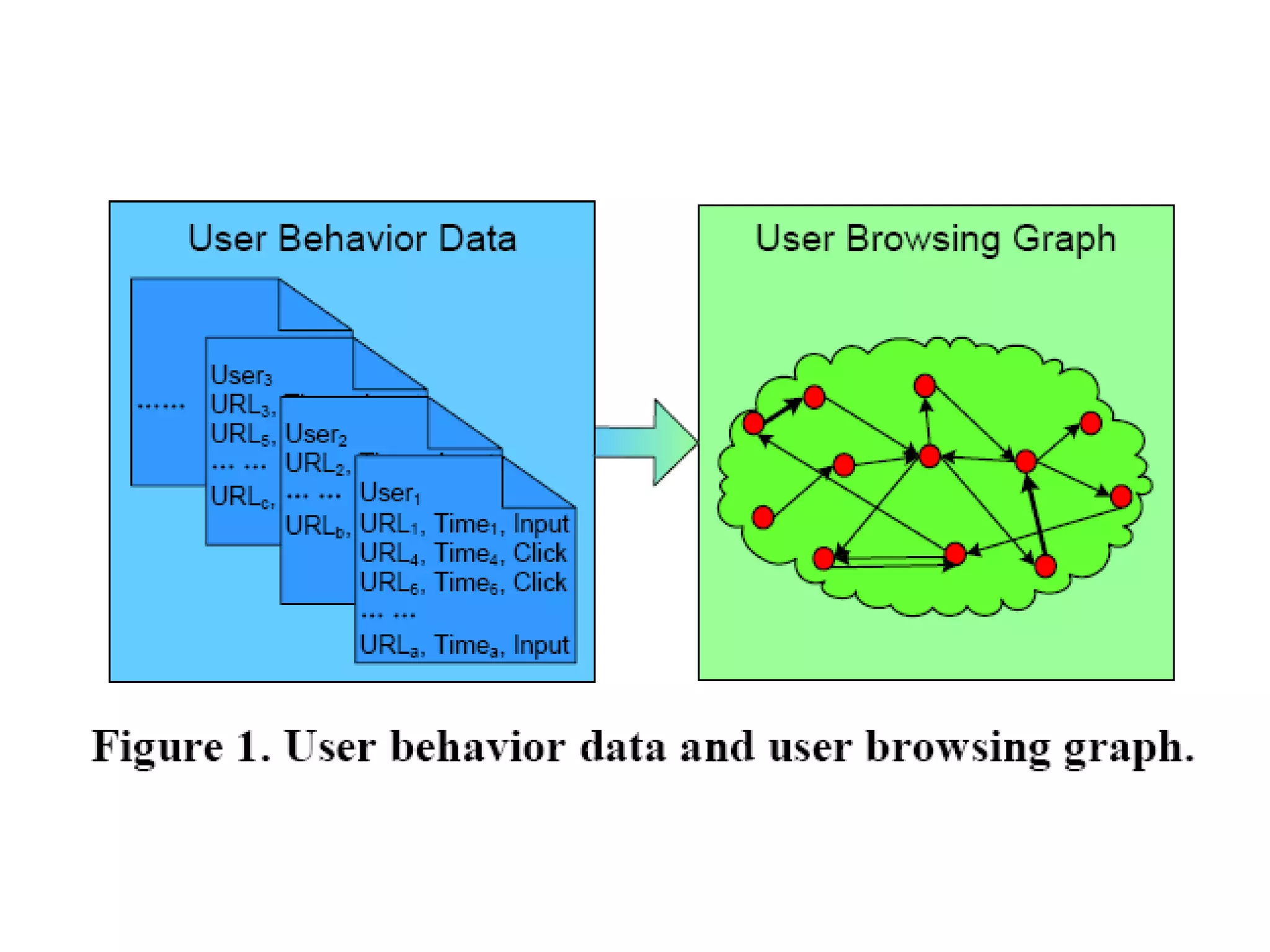
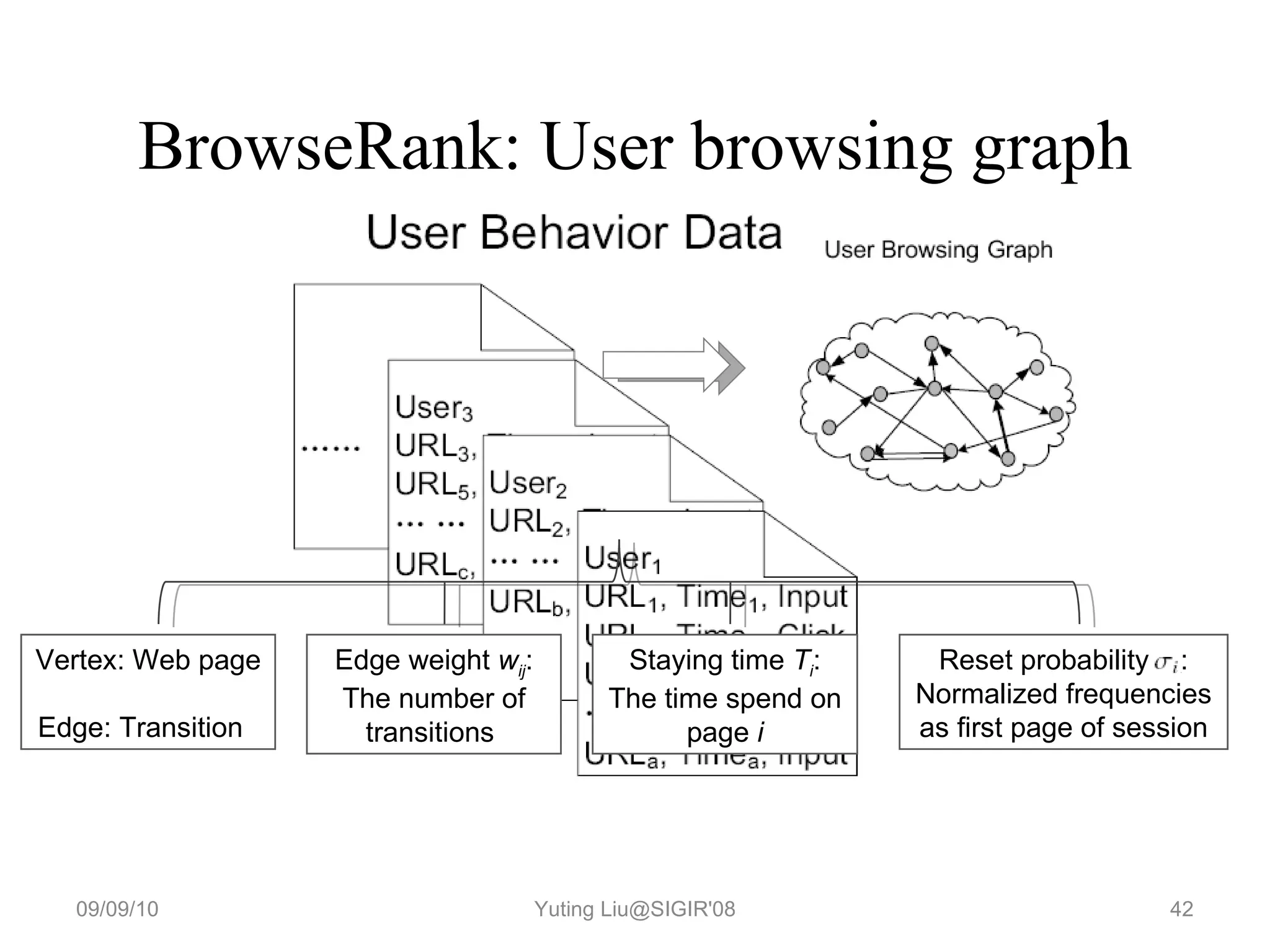
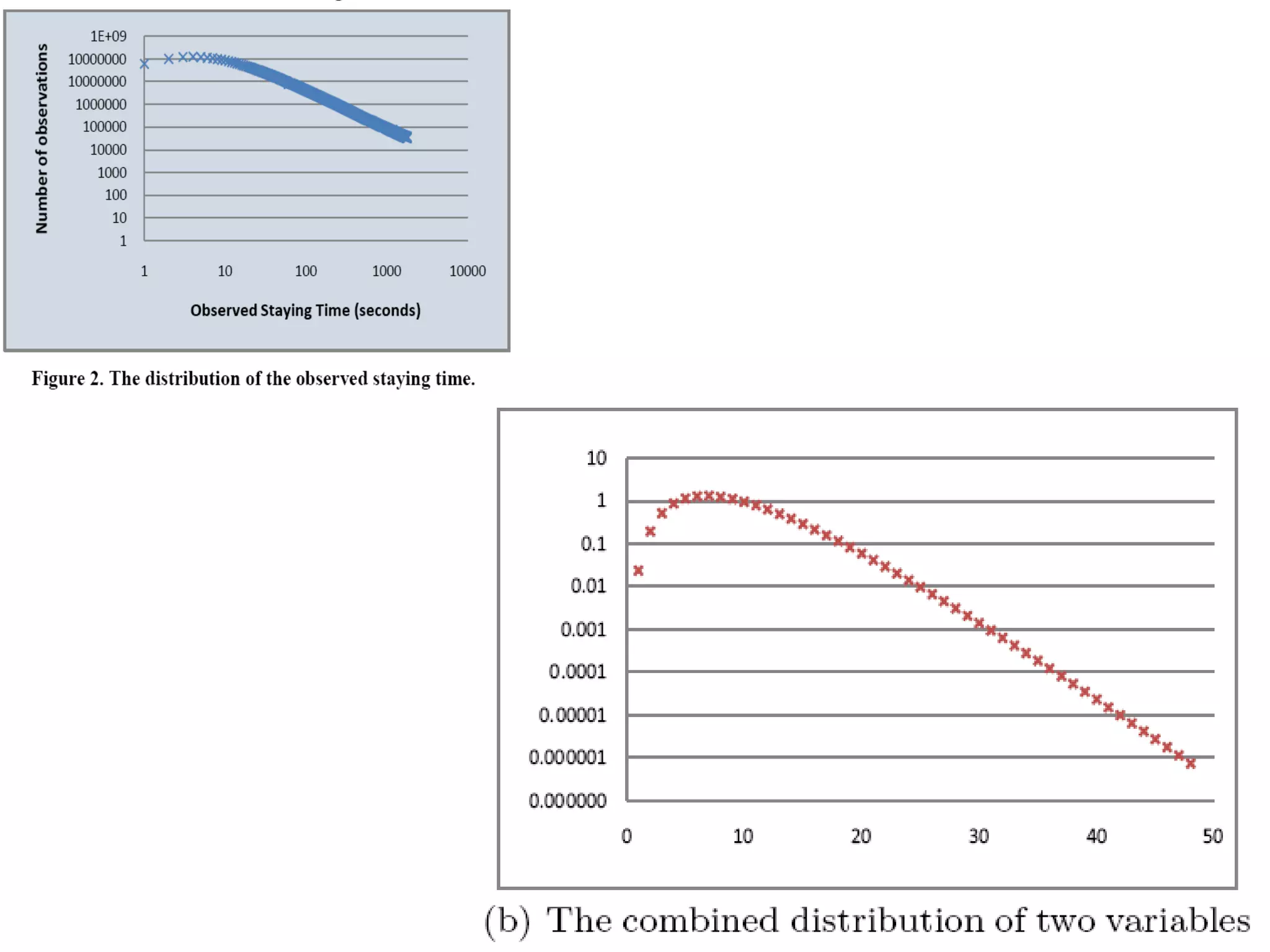
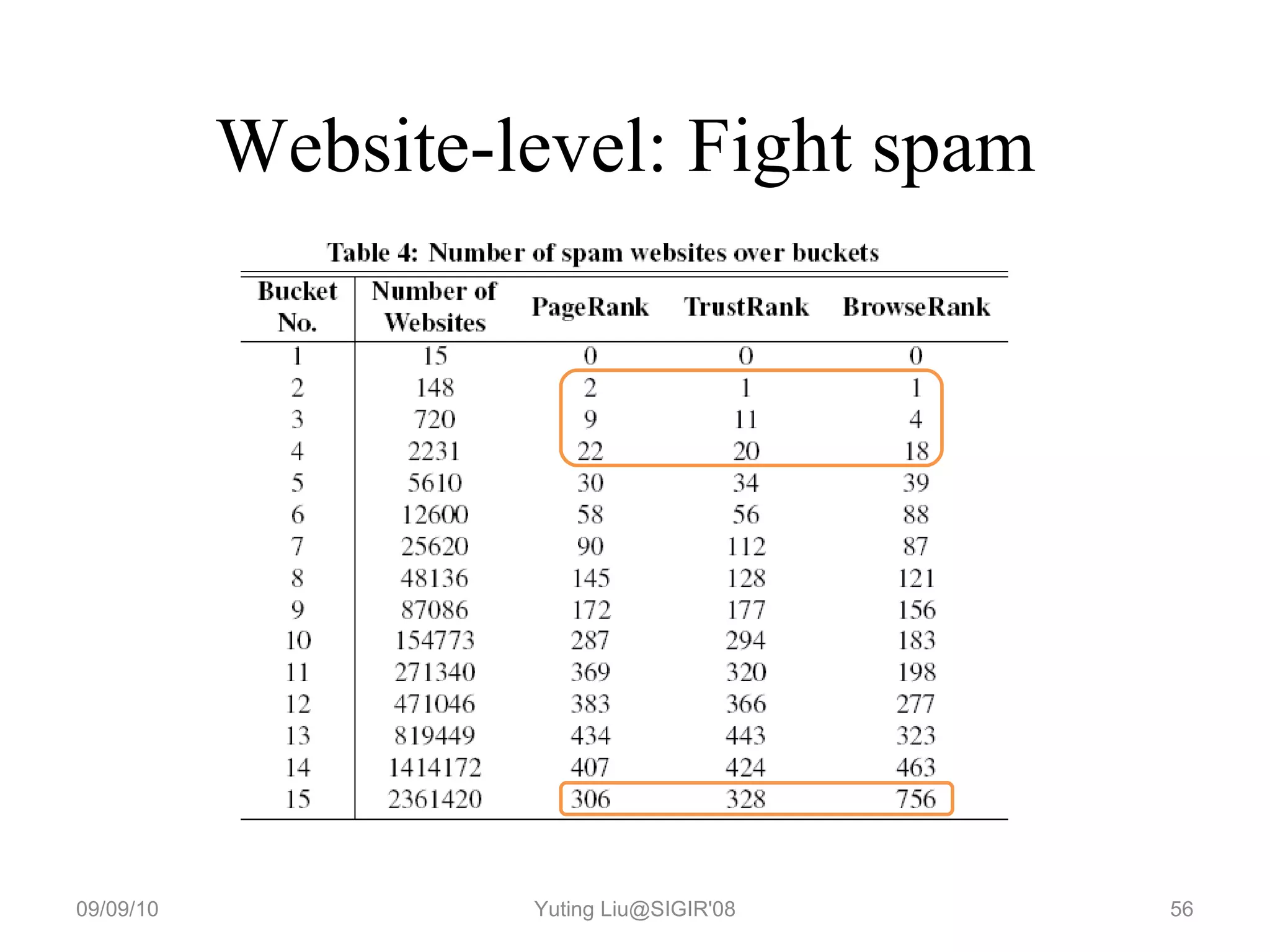
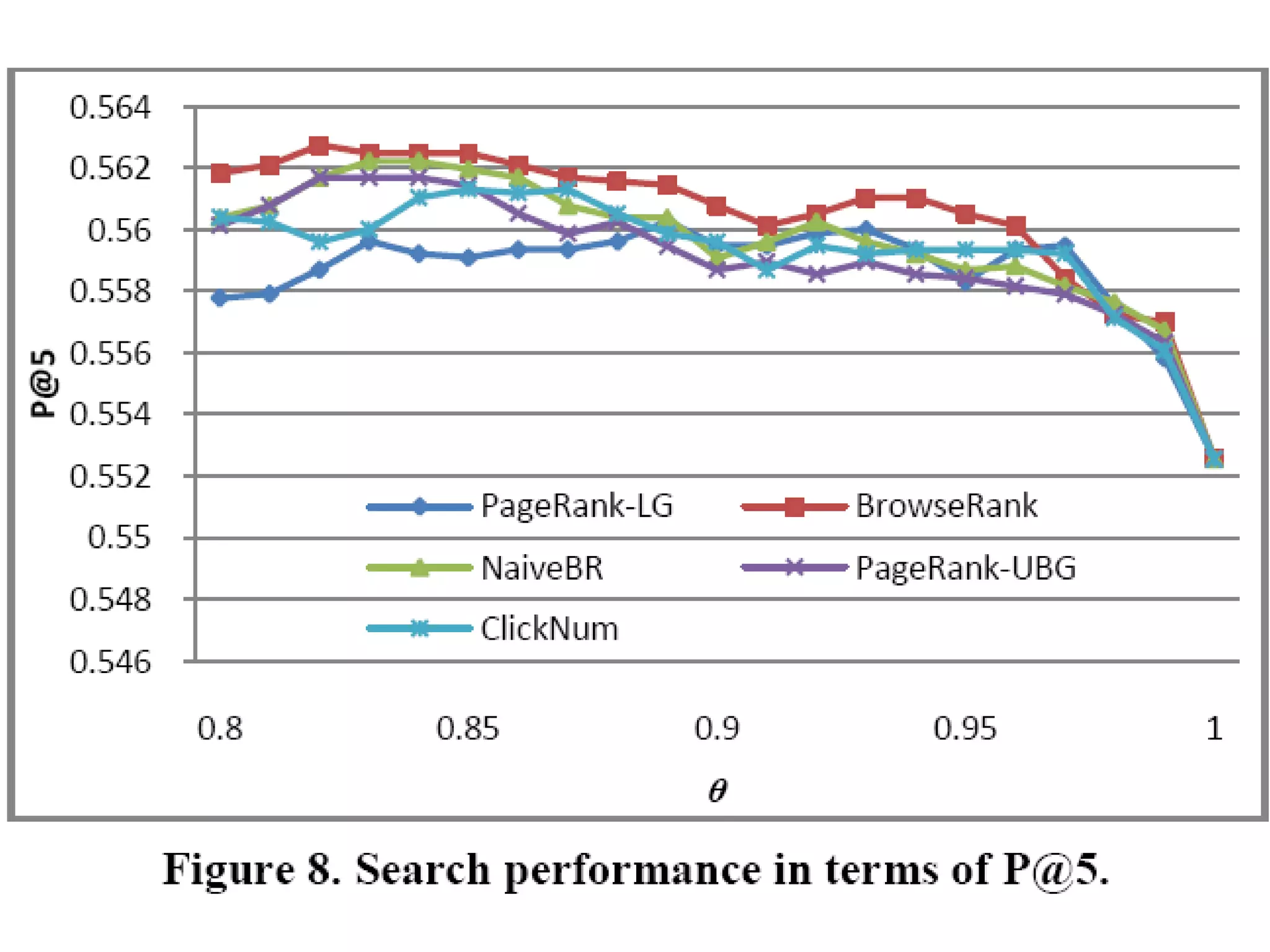
3. It proposes a new ranking algorithm called BrowseRank that models user browsing behavior using Markov chains and takes into account visit duration to better reflect true page importance.




![Static Rank ( 静态排序) Importance ranking Goal: compute page importance, page authority Method: Link analysis A method is based on the topology of the graph of whole Web pages. Web graph: page node, hyperlink edge. Algorithms: HITS(Kleinberg) [5] PageRank(GOOGLE) [6]](https://image.slidesharecdn.com/mazhiming-100908221800-phpapp02/75/Mazhiming-7-2048.jpg)
![Dynamic Rank (动态排序) Relevance ranking (相关性排序) Goal: compute the content match relevant score between pages and query. Method: Statistic machine learning Algorithms: Point-wise: BM25[7] Pair-wise: RankBoost[3], RankSVM[4], RankNet[1],… List-wise: ListNet[10]](https://image.slidesharecdn.com/mazhiming-100908221800-phpapp02/75/Mazhiming-8-2048.jpg)







































![Dynamic Rank (动态排序) Relevance ranking (相关性排序) Goal: compute the content match relevant score between pages and query. Method: Statistic machine learning Algorithms: Point-wise: BM25[7] Pair-wise: RankBoost[3], RankSVM[4], RankNet[1],… List-wise: ListNet[10]](https://image.slidesharecdn.com/mazhiming-100908221800-phpapp02/75/Mazhiming-61-2048.jpg)















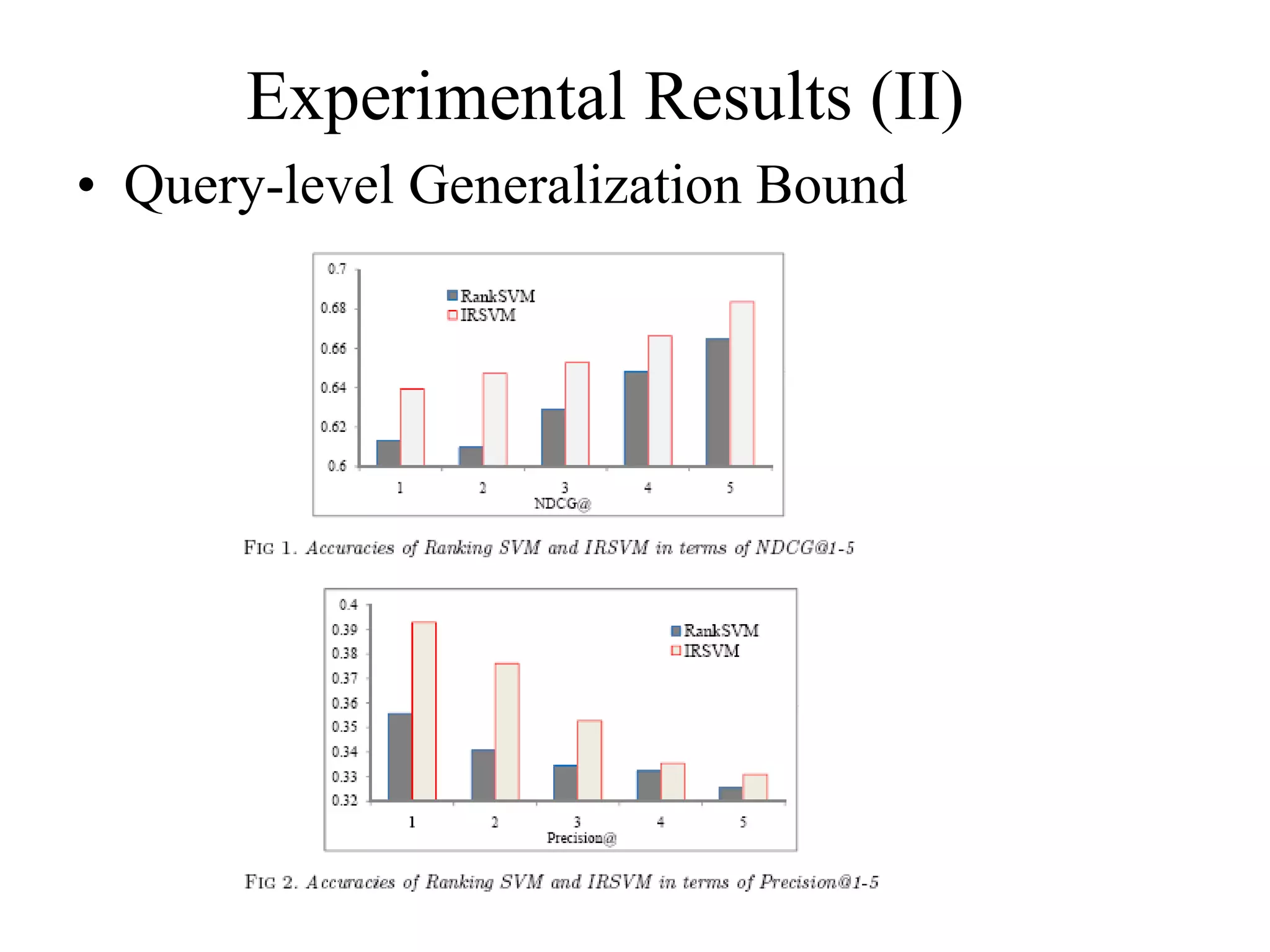
![Note: if , then the bound makes sense. This condition can be satisfied in many practical cases. As case studies, we investigate Ranking SVM and RankBoost. We show that after introducing query-level normalization to its objective function, Ranking SVM will have query-level stability. For RankBoost , the query-level stability can be achieved if we introduce both query-level normalization and regularization to its objective function . These analyses agree largely with our experiments and the experiments in Y. Cao, J. Xu, T.-Y. Liu, H. Li, Y. Huang, and H.-W. Hon, 2006 [5] and [11].](https://image.slidesharecdn.com/mazhiming-100908221800-phpapp02/75/Mazhiming-78-2048.jpg)


![RankBoost with Query-level Normalization and Regularization introducing query-level normalization to RankBoost does not lead to good performance [11]. query-level normalization cannot make RankBoost have query-level stability. adding both query-level normalization and regularization to the objective function, query-level stability can be achieved . Thus the framework offers us a way of modifying RankBoost for good ranking performance](https://image.slidesharecdn.com/mazhiming-100908221800-phpapp02/75/Mazhiming-81-2048.jpg)