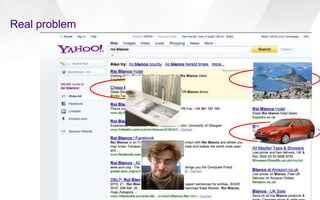
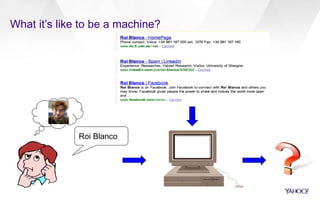
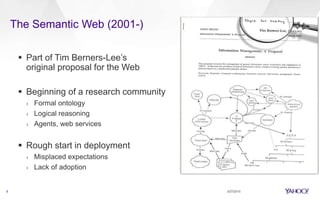
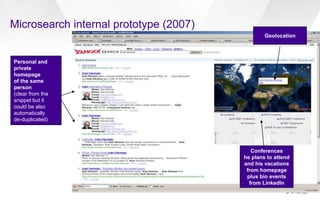
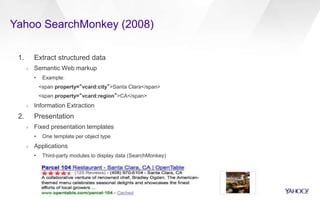
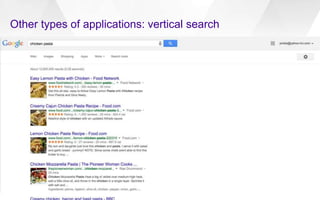
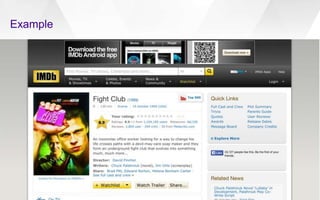
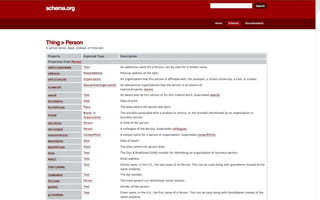
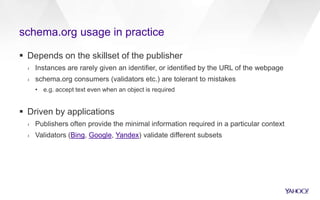
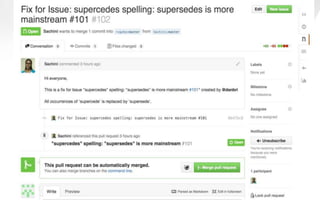
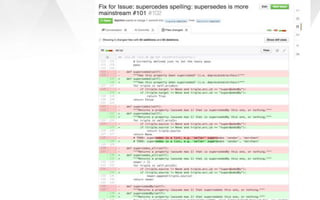
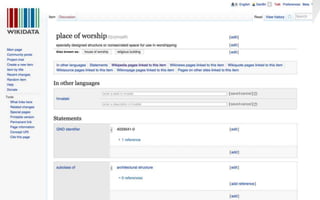
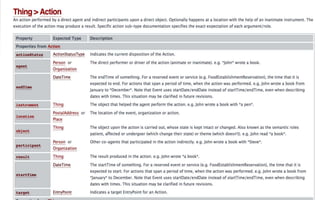
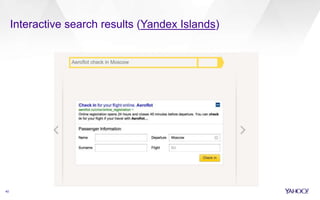
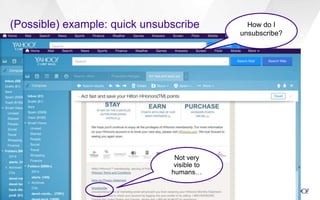
This document discusses semantic markup with schema.org to help search engines understand web pages better. It describes how schema.org was created as a collaborative effort by major search engines to define a shared set of schemas. This allows publishers to markup their content in a consistent way so it can be understood by different search engines and applications. The document outlines how schema.org has grown significantly in adoption and detail over time. It also discusses how schema.org builds on semantic web standards and can describe actions websites can take to help with task completion.