Download to read offline







![From: Project Leader Project X
Date: Sun, 26 May 2013 17:34:15 +0200
To: Project X
Subject: [Project X: 33] @WP-leiders
X-BeenThere: Project X @ Y.org
Beste WP-leiders,
Ik kreeg van Het Programma Management het volgende verzoek:
> Mag ik je vragen me een lijstje te sturen van welk EU
onderzoek en welk internationaal onderzoek er loopt bij de
partners gerelateerd aan Project X (internationale inbedding).
Dit is mijn meest urgente punt. Kunnen jullie zsm aan mij sturen
een lijstje met de volgende punten:
- lijst van lopende EU projecten waarbij mensen uit jouw WP
betrokken zijn; geef aub aan wi de partners zijn,
financieringsbron, of het een STREP (of NoE of ...) is, en of
jouw WP een participant of coordinator levert;
- lijst van aangevraagde EU projecten, met zelfde extra's
- lijst van eventuele andere internationale samenwerkingen die
niet door een formeel project zijn afgedekt
Stuur me de lijstjes aub zsm maar niet later dan dinsdag
18u. Bedankt voor jullie hulp. De Projectleider](https://image.slidesharecdn.com/glasgowworkshopkeynote-public-130602083901-phpapp01/85/Looking-beyond-plain-text-for-document-representation-in-the-enterprise-8-320.jpg)





















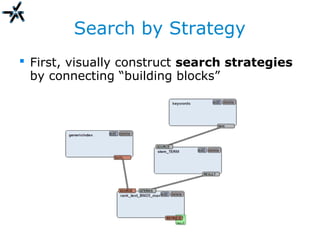

;](https://image.slidesharecdn.com/glasgowworkshopkeynote-public-130602083901-phpapp01/85/Looking-beyond-plain-text-for-document-representation-in-the-enterprise-37-320.jpg)
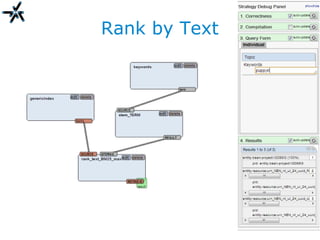
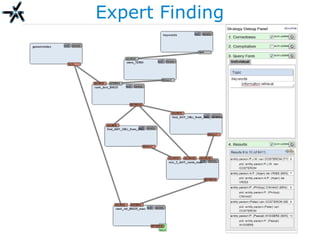
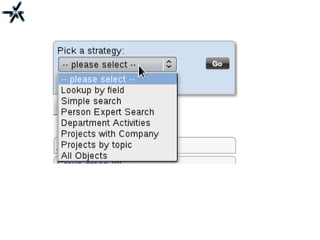
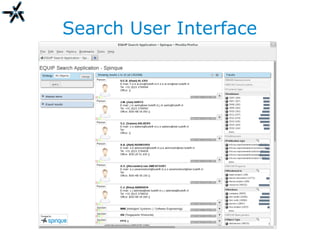
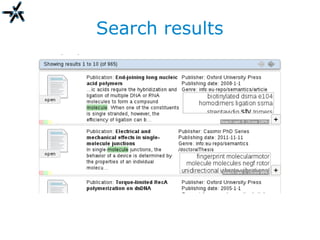

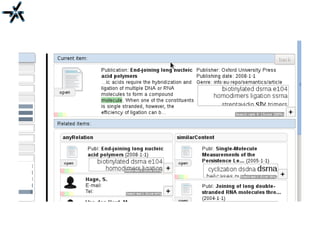

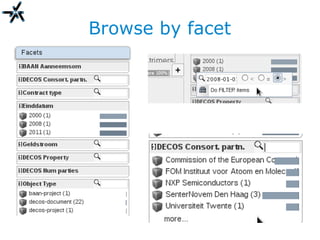

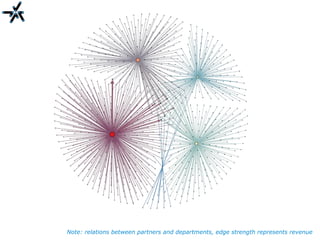







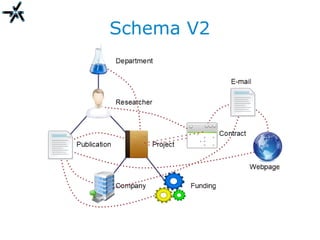
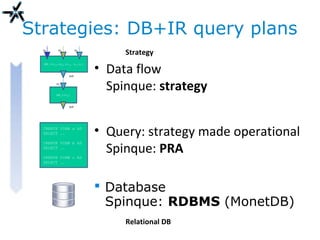
The document discusses the need for improved information retrieval in enterprise environments, focusing on integrating structured and unstructured data to meet strategic and business development needs. It highlights the inefficiencies caused by incomplete data and the implementation of effective search strategies using various organizational systems. The workshop emphasizes leveraging existing resources like ERP, CMS, and institutional repositories to enhance document representation and facilitate better access to information across different projects and collaborations.

























































![[AIIM17] Data Categorization You Can Live With - Monica Crocker](https://cdn.slidesharecdn.com/ss_thumbnails/aiim17datacategorizationyoucanlivewith-monicacrocker-170327220721-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















