Download to read offline



























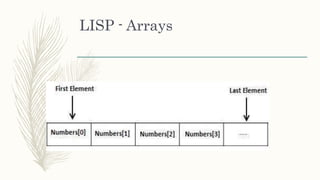









This document provides an overview of the LISP (List Processing) programming language. It discusses how LISP was commonly used for artificial intelligence programming due to its ability to modify programs dynamically. The document then describes various LISP dialects and the invention of LISP by John McCarthy. It also summarizes key LISP features like being machine-independent, providing object-oriented programming and advanced data types. The document concludes by explaining functions, predicates, conditionals, recursion, arrays, property lists, mapping functions and lambda expressions in LISP.























































































