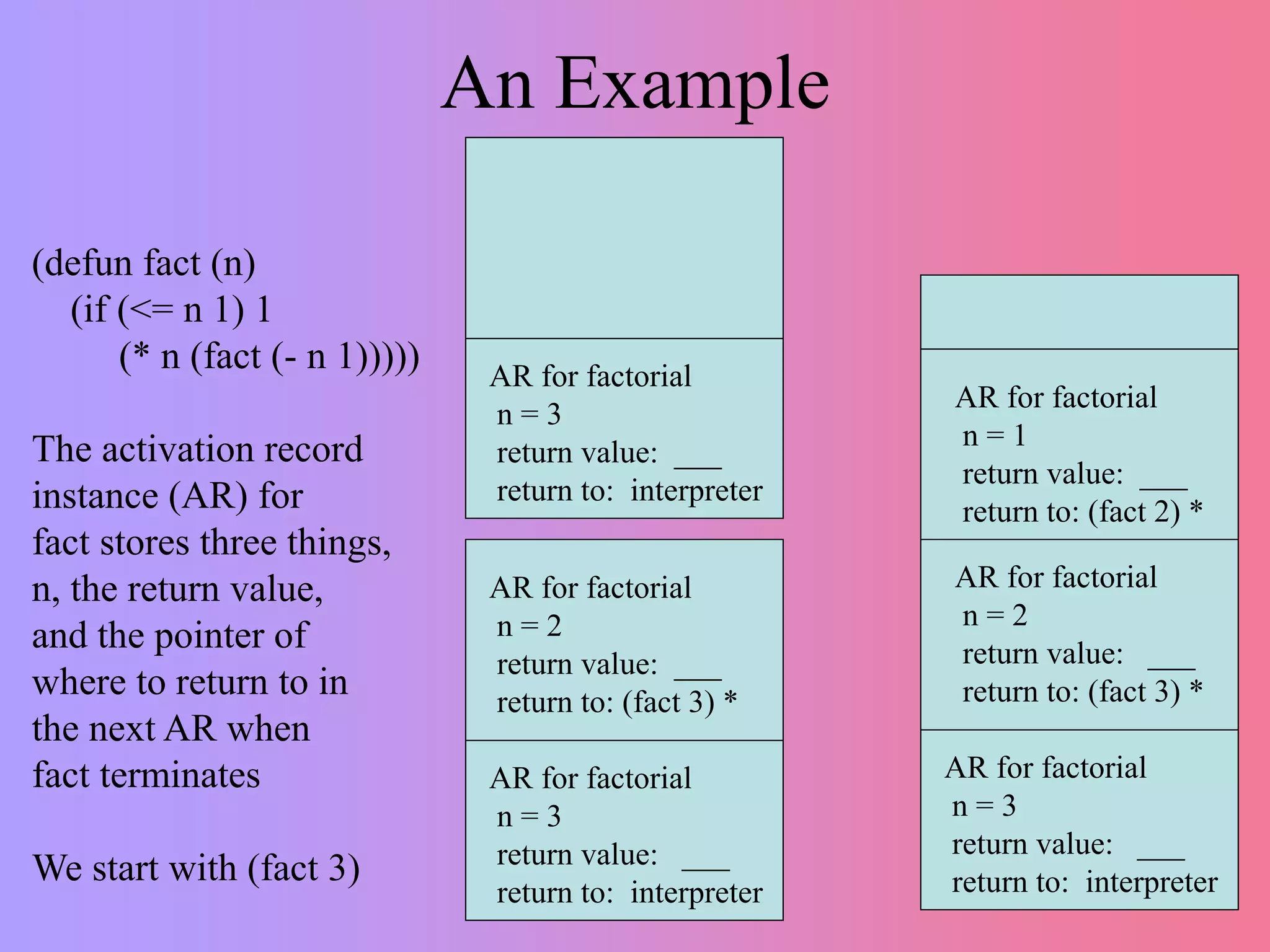
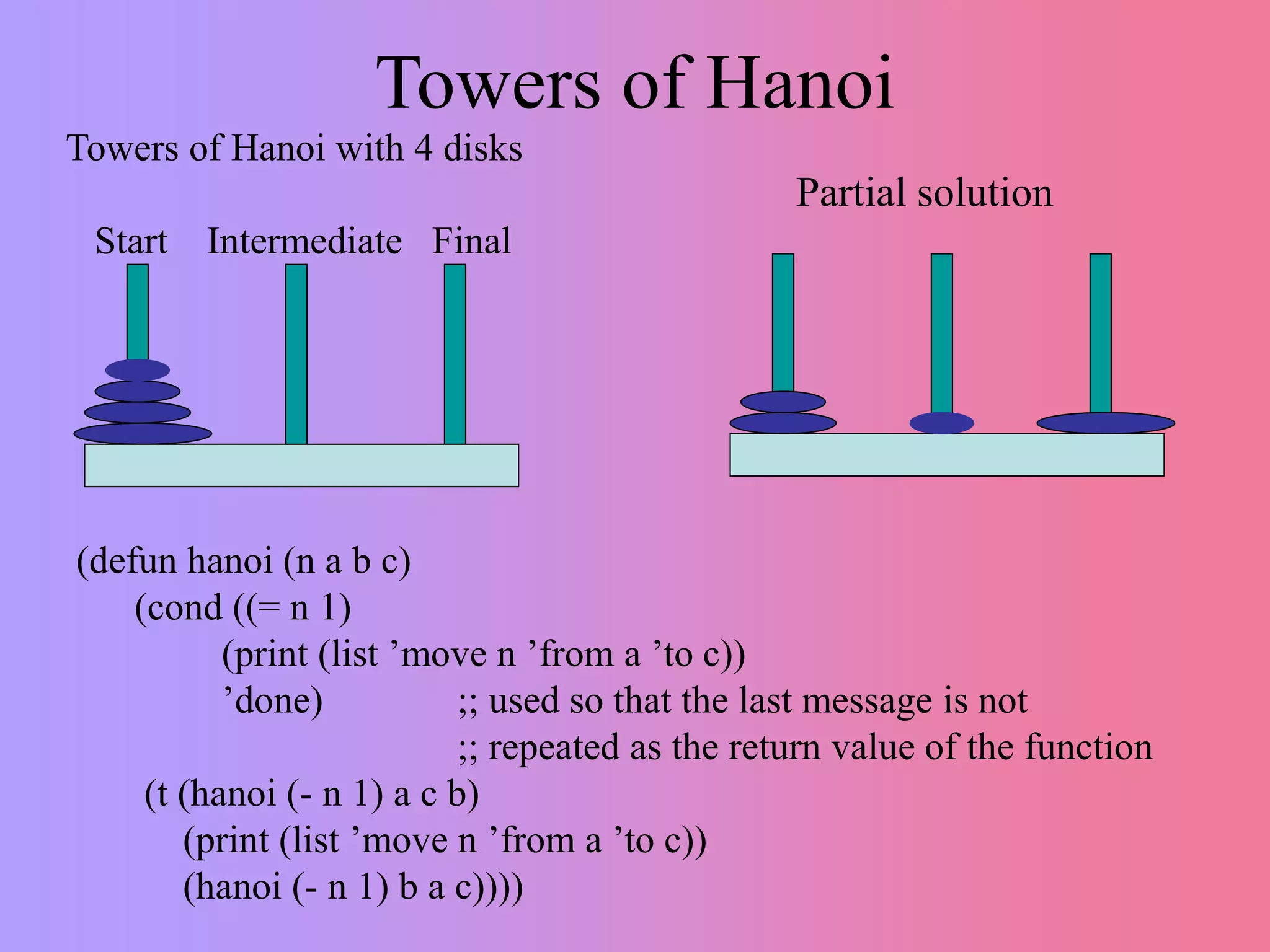
This document discusses recursion versus iteration in Lisp and Common Lisp. It notes that the original Lisp language was purely functional and used recursion to solve problems since it lacked local variables and iteration. While recursion is more elegant and leads to less code in some cases, it is also harder to understand, debug, and less efficient due to function call overhead. However, recursion is necessary for some problems like tree and graph traversals. Common Lisp makes recursion easier through its runtime stack and debugger. Several examples of recursive functions are provided, including ones for lists, trees, searching, and factorials. Tail recursion is discussed as a way to make recursion more efficient.











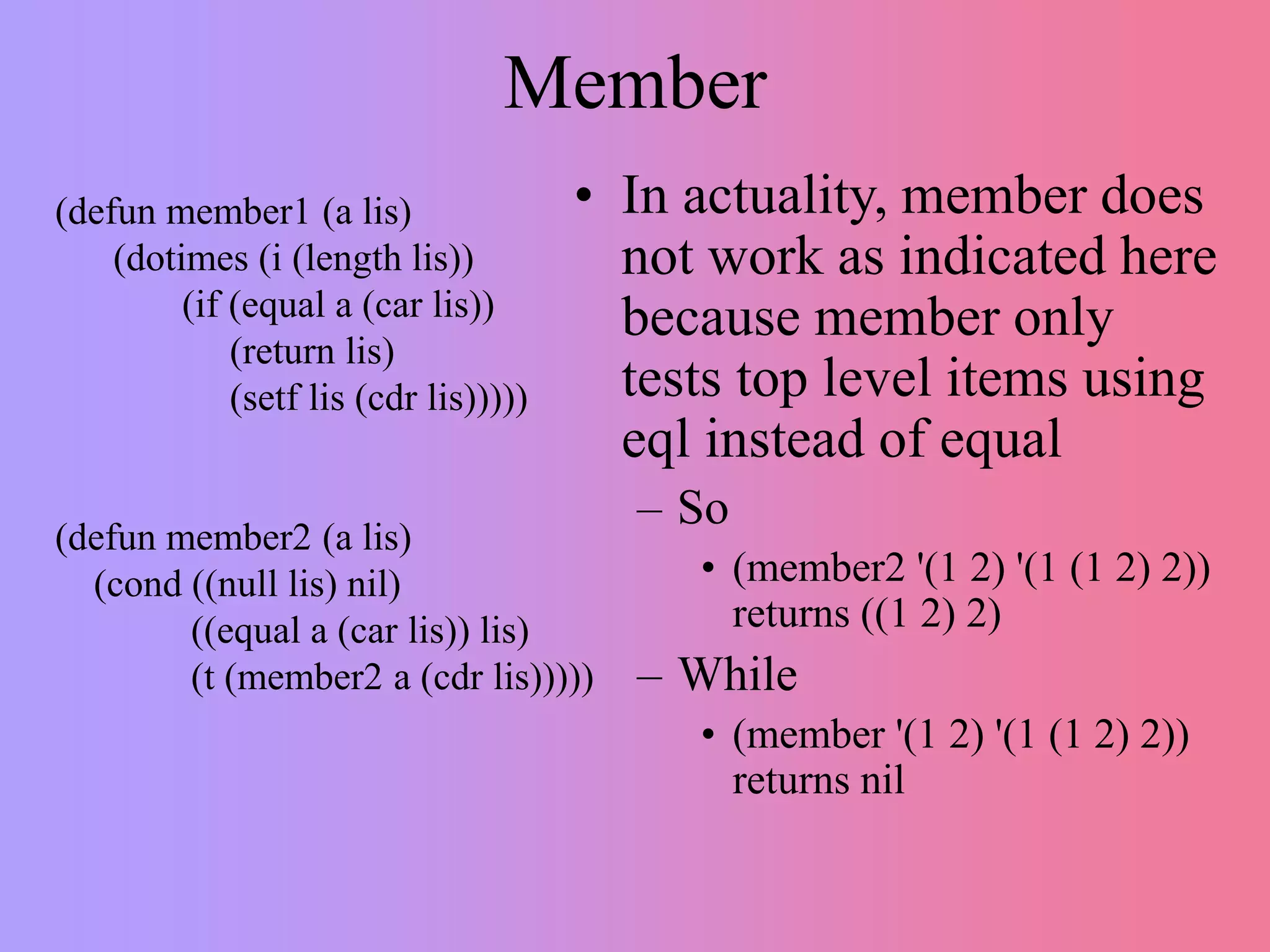
























![[ITP - Lecture 14] Recursion](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-21recursion-171215172939-thumbnail.jpg?width=640&height=640&fit=bounds)































