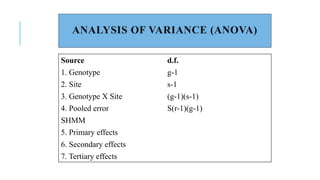
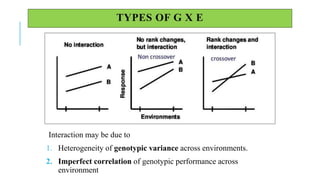
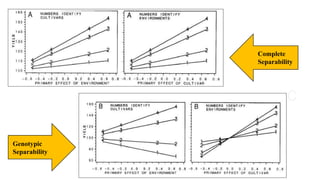
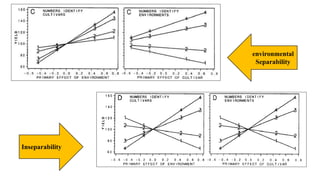
The document covers advanced topics in biometrical and quantitative genetics, specifically discussing various models for analyzing genotype and environmental interactions. Key points include the additive and multiplicative models, the Alternating Conditional Expectations (ACE) algorithm, and the significance of genotype x environment interactions (GEI) in crop improvement. Biplot analysis is highlighted as a valuable tool for visualizing relationships in genotype by environment data, aiding breeders in selecting superior genotypes.




















































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)

![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)










