More Related Content

PDF
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法 
PDF
ACRi_webinar_20220118_miyo 
PDF

PDF
GPU-FPGA 協調計算を記述するためのプログラミング環境に関する研究(HPC169 No.10) 
PDF
多数の小容量FPGAを用いた スケーラブルなステンシル計算機の開発 
PDF

PPTX

PDF
Ac ri webiner-agenda-20210309 Similar to 20220525_kobayashi.pdf

PPTX
GPU-FPGA協調プログラミングを実現するコンパイラの開発 
PDF

PPTX
研究者のための Python による FPGA 入門 ![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PPTX

PDF
電波望遠鏡用の分光器をAltera SDK for OpenCL使ってサクッと作ってみた 
PDF

PDF
FPGAを用いた世界最速のソーティングハードウェアの実現に向けた試み 
PPTX

PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究 
PPT

PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介 
PDF
Ac ri lt_fixstars_20210720 
PDF
「FPGA 開発入門:FPGA を用いたエッジ AI の高速化手法を学ぶ」 
PPTX
20161120_HPCでFPGAを使ってみたい_fpgastartup 
PDF
20210528_ACRi-panel_ksano_r2_submit 
PDF
16th_ACRi_Webinar_Kumamoto-Univ_Okawa_20240308.pdf 
PDF
GPGPU Education at Nagaoka University of Technology: A Trial Run 
PPTX
Abstracts of FPGA2017 papers (Temporary Version) 
PPTX
2012 1203-researchers-cafe More from 直久 住川

PDF
20th ACRi Webinar - Kyoto SU Oura-san Presentation 
PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料 
PDF
17th_ACRi_Webinar_Sadasue-san_Slide_20240724 
PDF

PDF
VCK5000_Webiner_GIGABYTE様ご講演資料 
PDF

PDF
AMD_Xilinx_AI_VCK5000_20220602R1.pdf 
PDF
20th ACRi Webiner - Presentation by MathWorks 
PDF

PDF
20th ACRi Webinar - Kyoto SU Presentation 
PDF

PDF
第11回ACRiウェビナー_東工大/坂本先生ご講演資料 
PDF
第9回ACRiウェビナー_セック/岩渕様ご講演資料 
PDF
18th ACRi Webinar : Presentation Slide ; Fukuda-san, ChipTip Technology 
PDF

PDF
ACRi-Webinar_Feb2023_agenda_20230225.pdf 
PDF
VCK5000_Webiner_Fixstars様ご講演資料 
PDF
16th_ACRi_Webiner_SEC_Takebe_20240308.pdf 
PDF

PDF
18th ACRi Webinar : Presentation Material - Prof. Yamaguchi 20220525_kobayashi.pdf
- 1.
- 2.
自己紹介
⚫名前:小林 諒平
➢筑波大学 助教
⚫略歴
➢2016年4月~ 筑波大学 助教
➢2016年3月 東工大 博士 (工学)
➢2013年3月 東工大 修士 (工学)
⚫主な研究分野
➢FPGAを用いたカスタムコンピューティング
➢GPU-FPGA協調計算
1
https://sites.google.com/site/ryokbya/
スーパーコンピュータ Cygnus
(GPU・FPGA混載クラスタ)
Stencil-Computation Accelerator
using 100 FPGAs
- 3.
FPGAのHPC利用
⚫近年のハイエンドFPGA
➢真の意味でアプリケーションとハードの codesigning
➢プログラミング環境: OpenCL,C++, etc.
➢高性能の光インターコネクト: 100Gb x N
➢柔軟な精度コントロールが可能
➢(比較的)低電力
⚫課題
➢GPUより低い演算性能 (FLOPS)
➢メモリテクノロジ,バンド幅: GPUより1世代程度遅い
➢高位合成ベースの開発コストは決して低くない
✓ FPGAに特化した記述やコンパイラ指示子挿入
✓ ライブラリ・デバッグツールの不足
2
BittWare 520N with Intel Stratix 10 FPGA
equipped with 4x 100Gbps optical
interconnection interfaces
各計算デバイスの特性
各デバイスをアプリの特性に基づいて
適材適所的に活用するのが重要
GPUが得意なことをFPGAにやらせようとすると爆死します (経験談)
→ 「FPGAは永遠の二番手」なので,使いどころの見極めが大事
→ 我々は GPU が不得手な部分のみのオフローディングに活用
- 4.
CHARM: Cooperative HeterogeneousAcceleration with
Reconfigurable Multidevices
⚫GPUとFPGAを適材適所的に活用してアプリケーション全体の性能を向上
➢CPUは,GPUおよびFPGAの制御を担当 (カーネルを起動・両デバイスを同期)
➢GPUは,アプリケーション中の並列性が高い部分を実行
➢FPGAは,GPUの苦手とする演算および通信を実行 (演算と通信の融合)
3
H ig h-speed
interconnect
CPU
Accelerator
(GPU)
Accelerator
(GPU)
PCIe sw itch
Comm unication
Log ic
Com putation
Log ic
FPGA
Netw ork Sw itch
Node
Node Node Node
Application oriented FPGA-FPGA comm.
invoke GPU/FPGA kernels
data movement via PCIe
(kicked from FPGA)
multi-physics/multi-scale
complicated problem
例:石炭の燃焼解析 (化学反応と流体計算)
シミュレーション内に様々な特性の演算が出現するので,
GPUに不適合な演算が部分的に含まれる可能性がある
CHARMコンセプトの概要図
このコンセプトの実証システムがスーパーコンピュータ Cygnus
- 5.
4
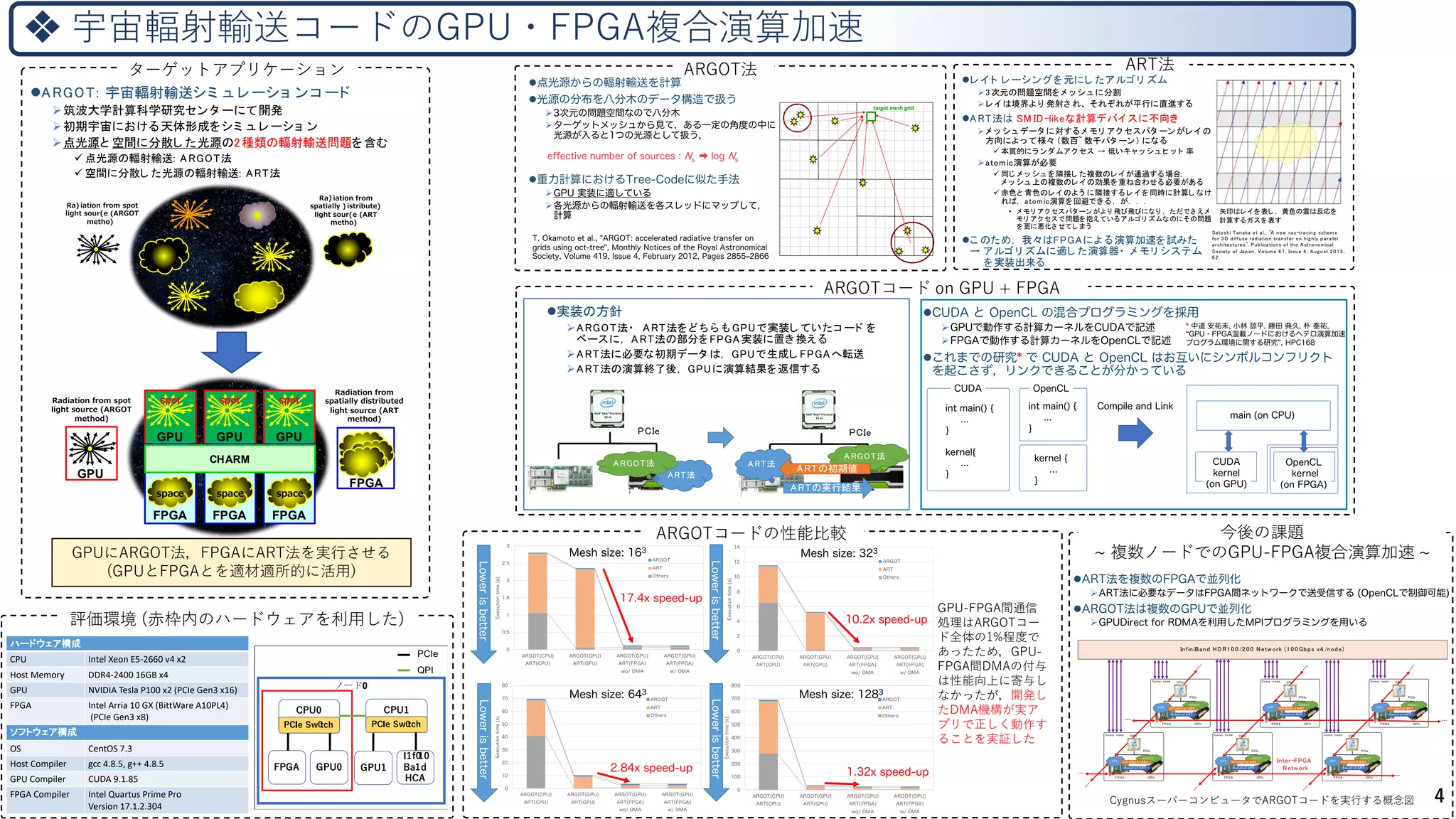
lARGOT: 宇宙輻射輸送シミ ュレーショ ンコ ード
Ø筑波大学計算科学研究センタ ーにて開発
Ø初期宇宙における天体形成をシミ ュ レ ーショ ン
Ø点光源と 空間に分散し た光源の2種類の輻射輸送問題を含む
ü 点光源の輻射輸送: ARGOT法
ü 空間に分散し た光源の輻射輸送: ART法
)
(
)
)
) )
(
)
ターゲットアプリケーション
GPUにARGOT法,FPGAにART法を実行させる
(GPUとFPGAとを適材適所的に活用)
ハードウェア構成
CPU Intel Xeon E5-2660 v4 x2
Host Memory DDR4-2400 16GB x4
GPU NVIDIA Tesla P100 x2 (PCIe Gen3 x16)
FPGA Intel Arria 10 GX (BittWare A10PL4)
(PCIe Gen3 x8)
ソフトウェア構成
OS CentOS 7.3
Host Compiler gcc 4.8.5, g++ 4.8.5
GPU Compiler CUDA 9.1.85
FPGA Compiler Intel Quartus Prime Pro
Version 17.1.2.304
ARGOT法 ART法
ARGOTコード on GPU + FPGA
1 0
10
1
0
PCIe
0
0
QPI
評価環境 (赤枠内のハードウェアを利用した)
❖ 宇宙輻射輸送コードのGPU・FPGA複合演算加速
lレイ ト レーシングを元にし たアルゴリ ズム
Ø3 次元の問題空間をメ ッ シュ に分割
Øレ イ は境界より 発射さ れ、 それぞれが平行に直進する
lART法は SM ID-likeな計算デバイ スに不向き
Øメ ッ シュ データ に対するメ モリ アク セスパタ ーンがレイ の
方向によっ て様々 (数百~ 数千パタ ーン) になる
ü 本質的にラ ンダムアク セス → 低いキャ ッ シュ ヒ ッ ト 率
Øatomic演算が必要
ü 同じ メ ッ シュ を隣接し た複数のレイ が通過する場合,
メ ッ シュ 上の複数のレイ の効果を重ね合わせる必要がある
ü 赤色と 青色のレイ のよう に隣接するレイ を同時に計算し なけ
れば, atomic演算を回避でき る, が. . .
• メ モリ アク セスパタ ーンがより 飛び飛びになり , ただでさ えメ
モリ アク セスで問題を抱えているアルゴリ ズムなのにその問題
を更に悪化さ せてし まう
lこ のため, 我々はFPGAによる演算加速を試みた
→ アルゴリ ズムに適し た演算器・ メ モリ システム
を実装出来る
矢印はレイ を表し , 黄色の雲は反応を
計算するガスを表す
Satoshi Tanaka et al., "A new ray-tracing scheme
for 3 D diffuse radiation transfer on hig hly parallel
architectures", Publications of the Astronomical
Society of Japan, Volume 6 7 , Issue 4 , Aug ust 2 0 1 5 ,
6 2
l実装の方針
ØARGOT法・ ART法をどちら も GPUで実装し ていたコ ード を
ベースに, ART法の部分をFPGA実装に置き 換える
ØART法に必要な初期データ は, GPUで生成し FPGAへ転送
ØART法の演算終了後, GPUに演算結果を返信する
PCIe PCIe
ART法
ARGOT法
ARGOT法
ART法
ARTの初期値
ARTの実行結果
ARGOTコードの性能比較
GPU-FPGA間通信
処理はARGOTコー
ド全体の1%程度で
あったため,GPU-
FPGA間DMAの付与
は性能向上に寄与し
なかったが,開発し
たDMA機構が実ア
プリで正しく動作す
ることを実証した
今後の課題
~ 複数ノードでのGPU-FPGA複合演算加速 ~
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
PCIe
ARGOT
ART Init data of ART
Result of ART
Comp. node
FPGA GPU
CPU
InfiniBand H DR1 0 0 /2 0 0 Netw ork (1 0 0Gbps x4 /node)
Inter-FPGA
Netw ork
CygnusスーパーコンピュータでARGOTコードを実行する概念図
GPU
FPGA
GPU
spot
GPU
spot
GPU
spot
FPGA
space
FPGA
space
FPGA
CHARM
Radiation from
spatially distributed
light source (ART
method)
space
Radiation from spot
light source (ARGOT
method)
- 6.
研究なかで FPGA に苦労した点
⚫論理合成時間長すぎ
➢1回の合成につき12 時間超えとかはザラ
➢どうやって乗り越えたか?
→ 高性能な合成用サーバを大人買い!(爆速クロックのCPU・メモリマシマシ)
➢FPGAベンダに解決を期待 (我々現代人は忙しい!Time is money!)
⚫ツールのバージョン互換性がなさすぎ
➢ついでに OS のバージョン縛り (Linux カーネルも含む) も厳しい
➢新しいツールが出る度,プロダクトの作り直しになる
➢FPGAベンダに解決を期待 (我々現代人は忙しい!Time is money!)
⚫実機で動作しなかった時はただただ絶望
➢「ロジアナ仕込まなきゃ」と思うと気が滅入る (観測すべき範囲が不明 → お手上げ)
➢RTLでのテストをしっかりやれば問題なかったことが経験的に多い
✓ メモリの動作モデルをキチンと再現しなかった,テストパターンが足りなかった等
➢シーン別デバッグまとめサイトとか簡単なデバッグチュートリアルとかがあると
嬉しいかも?
5
- 7.
- 8.
2)FPGA業界のダメなところ、苦労しているところは?
(FPGA業界で何を変えたいと考えていますか?)
⚫効率的な開発をサポートするプログラミング環境がまだまだ発展途上
➢ 数値計算ライブラリ・機械学習ライブラリが少ない (CUDA環境と比べると)
✓ バージョン互換性の問題も並行してある
➢ 個人的にはバージョン互換性がある標準ライブラリを策定してくれると嬉しい
⚫関連研究
➢ CannonのアルゴリズムのOpenCL実装 [1]
✓ 行列積のFPGAアクセラレータを実装するのが目的ではない
• 行列積のオフロードだけならGPUの方がマシ (オフロードしない方が良い場合も...)
✓ 行列積をベースとするFPGAアプリのための高性能なビルディングブロックを提供
➢ fBLAS: Streaming Linear Algebra on FPGA [2]
✓ FPGA用BLASライブラリ
• FPGA用数値計算アプリケーションの効率的な実装に資することを目的
7
https://github.com/ac2-prod/fpga_sort
[1]: P. Gorlani et al., “OpenCL Implementation of Cannon's Matrix Multiplication Algorithm on Intel Stratix 10 FPGAs”, ICFPT19, pp.99-107
[2]: Tiziano De Matteis et al., “fBLAS: streaming linear algebra on FPGA”, SC20, Article No.59, Pages 1–13
- 9.






![2)FPGA業界のダメなところ、苦労しているところは?
(FPGA業界で何を変えたいと考えていますか?)
⚫効率的な開発をサポートするプログラミング環境がまだまだ発展途上
➢ 数値計算ライブラリ・機械学習ライブラリが少ない (CUDA 環境と比べると)
✓ バージョン互換性の問題も並行してある
➢ 個人的にはバージョン互換性がある標準ライブラリを策定してくれると嬉しい
⚫関連研究
➢ CannonのアルゴリズムのOpenCL実装 [1]
✓ 行列積のFPGAアクセラレータを実装するのが目的ではない
• 行列積のオフロードだけならGPUの方がマシ (オフロードしない方が良い場合も...)
✓ 行列積をベースとするFPGAアプリのための高性能なビルディングブロックを提供
➢ fBLAS: Streaming Linear Algebra on FPGA [2]
✓ FPGA用BLASライブラリ
• FPGA用数値計算アプリケーションの効率的な実装に資することを目的
7
https://github.com/ac2-prod/fpga_sort
[1]: P. Gorlani et al., “OpenCL Implementation of Cannon's Matrix Multiplication Algorithm on Intel Stratix 10 FPGAs”, ICFPT19, pp.99-107
[2]: Tiziano De Matteis et al., “fBLAS: streaming linear algebra on FPGA”, SC20, Article No.59, Pages 1–13](https://image.slidesharecdn.com/20220525kobayashi-220525104918-56506d64/75/20220525_kobayashi-pdf-8-2048.jpg)
