Programmable Solutions Group4
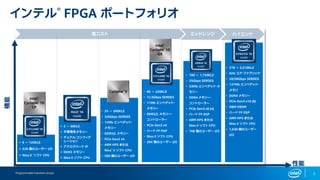
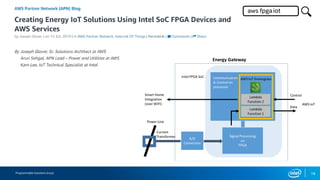
FPGA概要
•Sea of programmable logic and routing
•DSPs (floating-point units)
•M20K SRAMs (2.5KB/SRAM)
•Range of devices:
- Intel® Stratix® 10 FPGA: 14 nm, high performance
- Intel Arria® 10 FPGA: 20 nm, mid range
- Intel Cyclone® 10 FPGA: 20 nm, low power
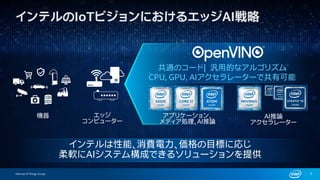
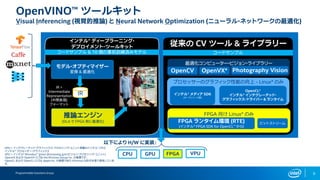
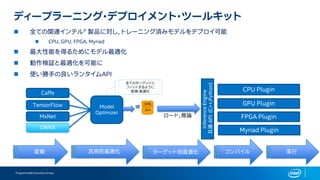
FPGAs are well positioned for deep learning…
X
+





























![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Track2-5] CPUだけでAIをやり切った最近のお客様事例 と インテルの先進的な取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/intel20200801dllabdeeplearningdigitalconferencefinalv1-200806120825-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)