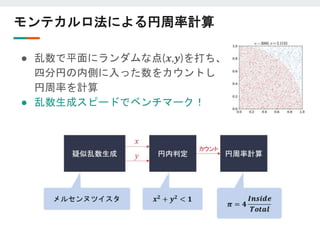
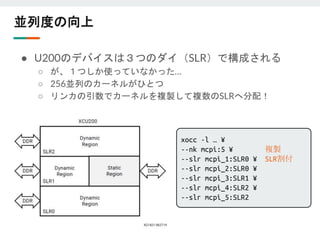
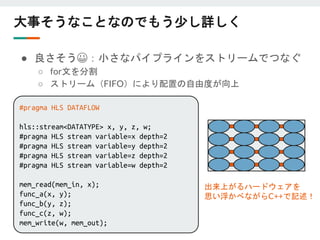
大事そうなことなのでもう少し詳しく
● 良くない😫:大きなパイプラインがひとつ
○ ひとつのfor文に処理を詰め込む
■ソフトウェア的な発想だと自然
○ 制御信号が遠くまで広がる
■ fanout、配線遅延、クロックリージョンまたぎ
○ SLRに納まりが悪そう
パイプライン
制御信号
for (int i=0; i<N; i++)
{
auto x = mem_in[i];
auto y = func_a(x);
auto z = func_b(y);
auto w = func_c(z);
mem_out[i] = w;
}





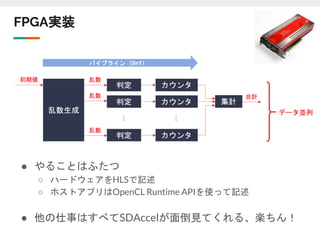
![メルセンヌツイスタ
● ハードウェア実装に適していそう
内部状態更新
statet+1[623] = update(statet[0], statet[1], statet[397])
statet+1[0..622] = statet[1..623]
乱数出力
outt+1 = tempering(statet+1[623])](https://image.slidesharecdn.com/191112-191112075423/85/FPGA-fpgax-12-6-320.jpg)
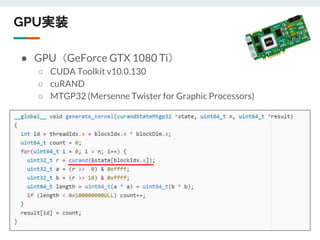

![大事そうなことなのでもう少し詳しく
● 良くない😫:大きなパイプラインがひとつ
○ ひとつのfor文に処理を詰め込む
■ ソフトウェア的な発想だと自然
○ 制御信号が遠くまで広がる
■ fanout、配線遅延、クロックリージョンまたぎ
○ SLRに納まりが悪そう
パイプライン
制御信号
for (int i=0; i<N; i++)
{
auto x = mem_in[i];
auto y = func_a(x);
auto z = func_b(y);
auto w = func_c(z);
mem_out[i] = w;
}](https://image.slidesharecdn.com/191112-191112075423/85/FPGA-fpgax-12-12-320.jpg)
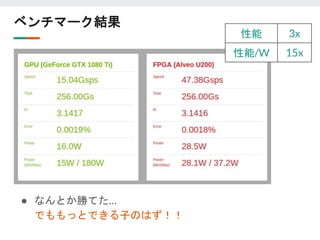
![改善結果 (改善前:256並列、185MHz、47Gs/s)
● 並列度
○ 64並列のカーネルを10個 = 640並列
● 周波数
○ 375MHzに改善
4個
2個
4個
性能 [Gs/s] 電力 [W] 性能比 性能比/W
GTX 1080 Ti 19.51 240 1.0 1.0
Alveo U200 222.95 73 11.4 37.5
最終ベンチマーク結果
一秒間に2230億個の乱数生成… エクストリーム感](https://image.slidesharecdn.com/191112-191112075423/85/FPGA-fpgax-12-14-320.jpg)








](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqlchatgptodc2023nttdata-230830045114-329af13b-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)

















