Downloaded 638 times










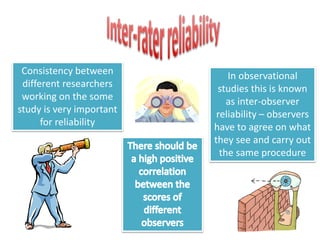




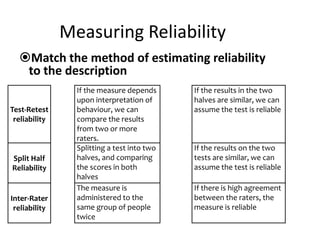
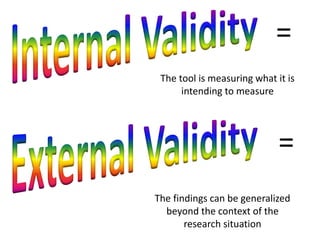







This document discusses the importance of validity and reliability in research. It addresses whether research tests truly measure what they aim to measure (validity) and whether the results are consistent (reliability). Specifically, it covers the concepts of internal validity, external validity, content validity, face validity, test-retest reliability, inter-rater reliability, and split-half reliability. The document emphasizes that research must demonstrate both validity and reliability to ensure the findings can be generalized and the measuring tools are sound.









































































































