Downloaded 36 times








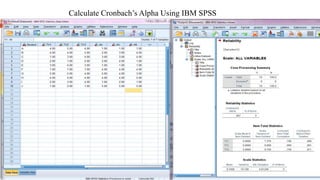
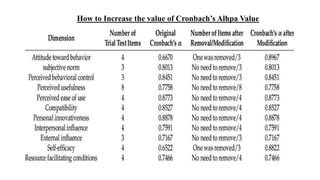

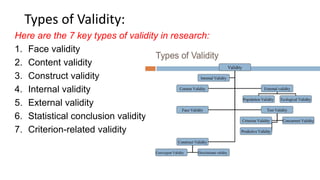





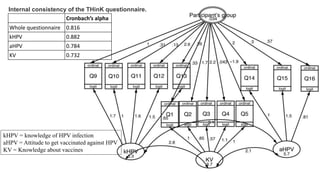



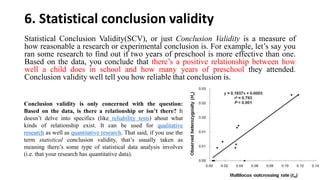


Reliability and validity are important concepts for researchers to consider when developing and evaluating measurement tools and methods. Reliability refers to the consistency of a measure, while validity refers to the accuracy. There are different types of reliability, including test-retest and internal consistency, which can be estimated using Cronbach's alpha. Validity includes face, content, construct, internal, external, statistical conclusion, and criterion-related validity. Researchers must ensure their measures are both reliable in providing consistent results and valid in accurately measuring the intended construct.










































































