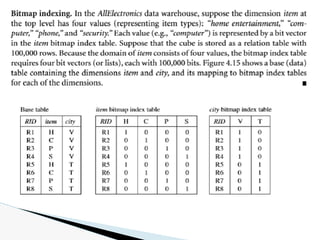
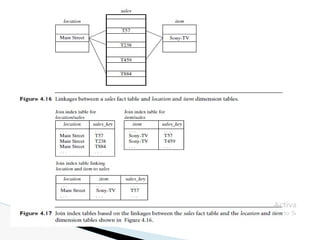
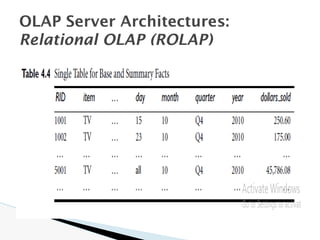
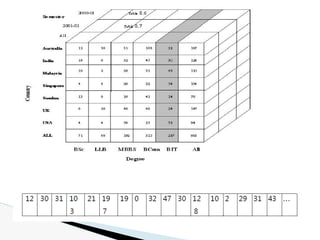
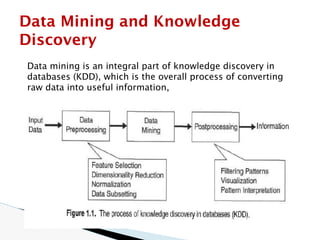
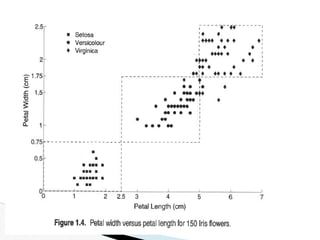
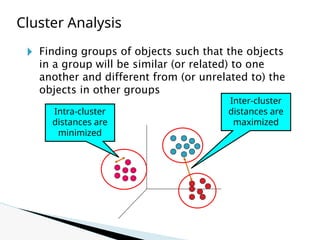
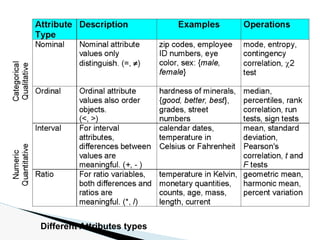
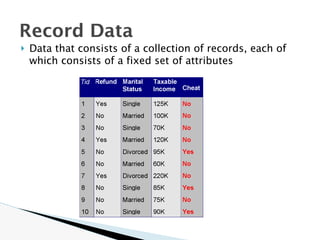
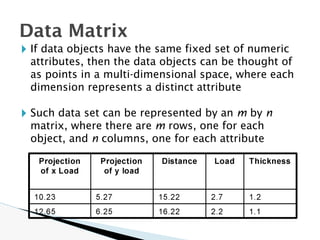
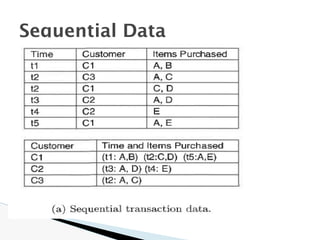
The document discusses data warehouse implementation and efficient data cube computation for OLAP, detailing methods of query processing, cube materialization strategies, and indexing techniques such as bitmap and join indices. It also explores data mining processes, challenges, and tasks, emphasizing the need for scalability, handling high-dimensional data, and employing predictive modeling and clustering techniques to uncover hidden patterns within large datasets. Overall, it highlights the significance of efficient data management in analytics to derive meaningful insights from complex information systems.





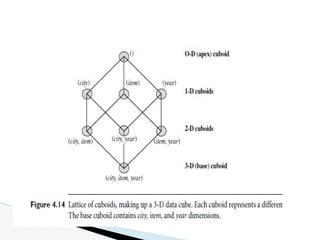

![🞂 The compute cube operator computes aggregates
over all subsets of the dimensions specified in the
operation.
🞂 SQL syntax, the data cube could be defined in
DMQL as:
define cube sales [item, city, year]: sum (sales_in_dollars)
🞂 Compute the sales aggregate cuboids as:
compute cube sales
Data Cube Computation](https://image.slidesharecdn.com/module2-240817051701-805d2556/85/data-mining-and-data-warehousing-PPT-module-2-7-320.jpg)
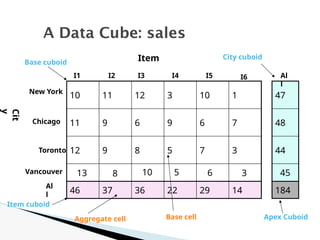
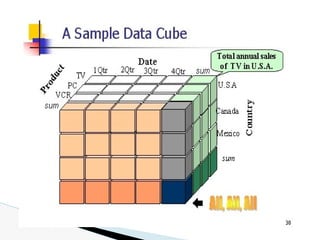
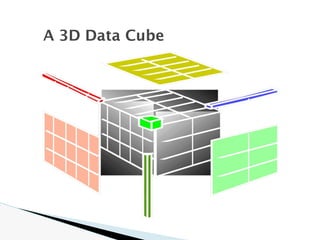













![1. Determine which operations should be performed on the available
cuboids
e.g., dice = selection + projection
2. Determine which materialized cuboid(s) should be selected for
OLAP operation.
◦ the one with low cost
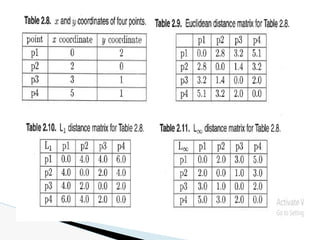
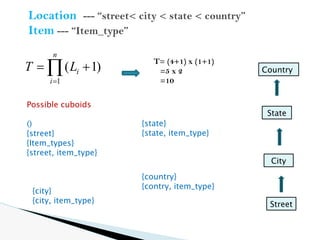
Suppose that we define a data cube for AllElectronics of the form
“sales cube [time, item, location]: sum(sales in dollars).”
The dimension hierarchies used are
“day < month < quarter < year” for time;
“item name < brand < type” for item;
“street < city < province or state < country” for location.
Efficient Processing of OLAP
Queries](https://image.slidesharecdn.com/module2-240817051701-805d2556/85/data-mining-and-data-warehousing-PPT-module-2-30-320.jpg)
































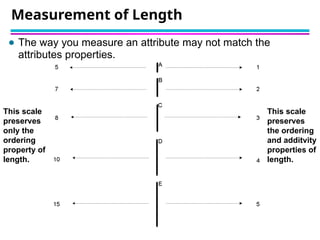














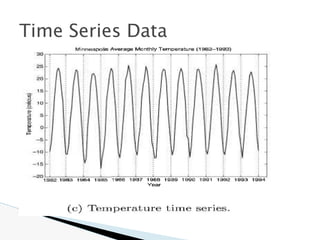
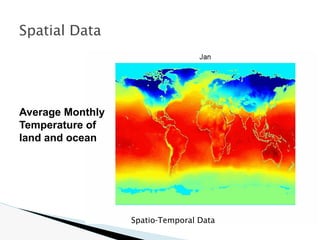



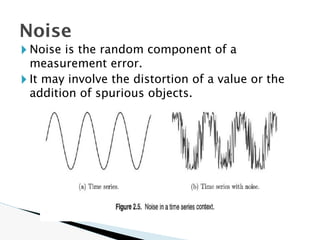
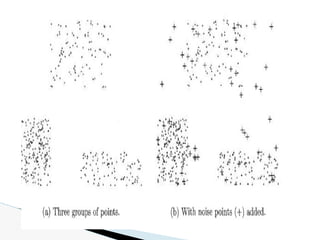








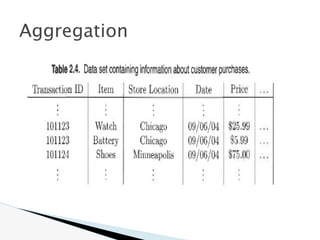
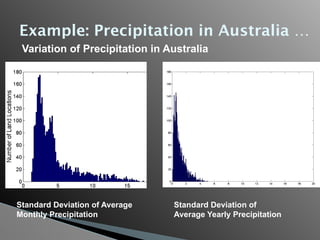




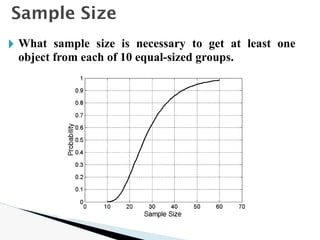

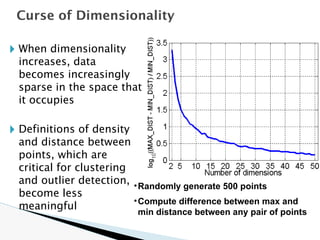
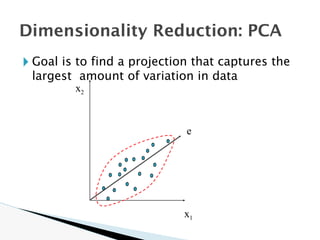


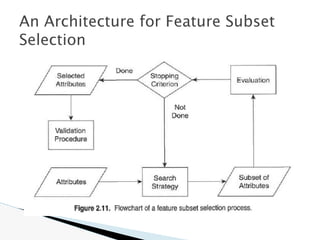

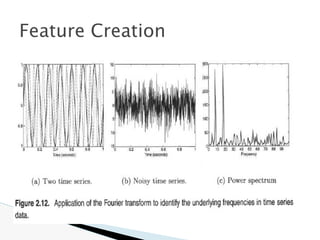

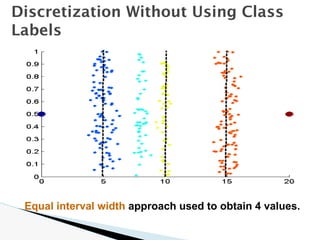
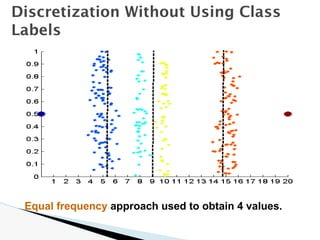
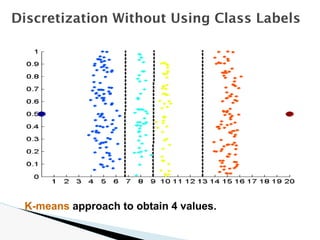
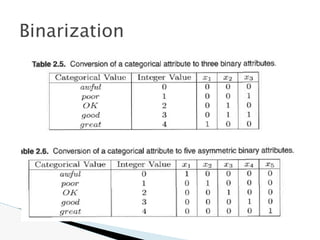
![🞂 Similarity measure
◦ Numerical measure of how alike two data objects are.
◦ Is higher when objects are more alike.
◦ Often falls in the range [0,1]
🞂 Dissimilarity measure
◦ Numerical measure of how different two data objects are
◦ Lower when objects are more alike
◦ Minimum dissimilarity is often 0
◦ Upper limit varies
🞂 Proximity refers to a similarity or dissimilarity
Similarity and Dissimilarity
Measures](https://image.slidesharecdn.com/module2-240817051701-805d2556/85/data-mining-and-data-warehousing-PPT-module-2-122-320.jpg)