Download as PDF, PPTX


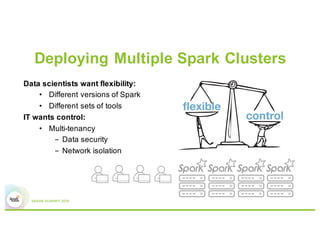







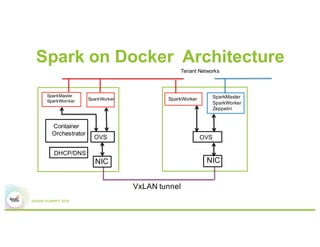


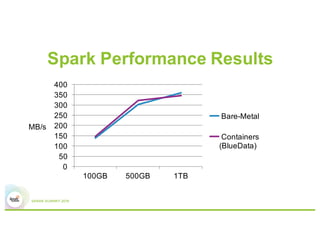




Running Spark on Docker containers provides flexibility for data scientists and control for IT. Some key lessons learned include optimizing CPU and memory resources to avoid noisy neighbor problems, managing Docker images efficiently, using network plugins for multi-host connectivity, and addressing storage and security considerations. Performance testing showed Spark on Docker containers can achieve comparable performance to bare metal deployments for large-scale data processing workloads.




















![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)












