Downloaded 119 times







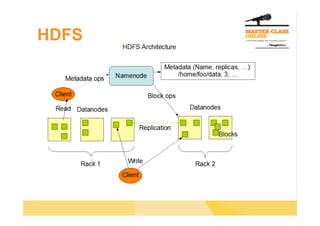

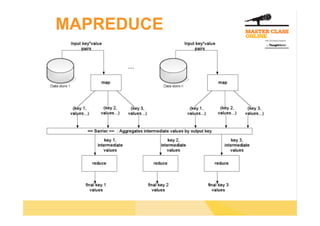






The document discusses the use of Hadoop for processing large data sets, emphasizing its capabilities in scalable storage and batch data processing. Key components include HDFS for data storage and MapReduce for data processing, highlighting the importance of parallel data reading and the abstraction of programming tasks. Additionally, it introduces tools like Pig and Hive for simplified data analysis and SQL-like querying over Hadoop data.






















































































